PyTorch进阶训练技巧及UNet演示
Datawhale202210——《深入浅出PyTorch》(6)
文章目录
- Datawhale202210——《深入浅出PyTorch》(6)
- 前言
- 一、自定义损失函数
-
- 以函数方式定义
- 以类方式定义
- 二、动态调整学习率
-
- 使用官方scheduler
- 自定义scheduler
- 三、模型微调-torch vision、timm
-
- torchvision
-
- 微调流程(如图所示)
- 使用已有的结构
- 注意事项
- 训练特定层
- timm(自行了解)
- 四、半精度训练
-
- 在PyTorch中设置半精度训练
- 拓展
- 五、数据增强-imgaug
-
- imgaug的安装
- imgaug在PyTorch的使用
- 六、使用argparse进行调参
-
- argparse 的简介
- argparse 的使用
- argparse 的进阶
- 七、参考文档
-
- 来自Datawhale的投喂
- 来自官方的投喂
- 来自广大网友的投喂
- 总结
前言
训练模型往往需要根据实验情况灵活调整,同时做到活用PyTorch提供的库和更好地服务自己的项目,因此需要进一步强化训练技巧,这将是一个长期的旅途,就从今天的第一站开始吧!
一、自定义损失函数
以函数方式定义
损失函数的本质就是“对输入进行函数运算,得到一个输出”,因此可以用定义函数的方式直接定义,但不太常用。
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss
以类方式定义
该方式及是把损失函数当作神经网络的一层来对待,同样是继承至nn.Module类。
Dice Loss是一种在分割领域常见的损失函数,定义如下:

class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets)
相关知识补充:nn.module和nn.function
nn.Module是一个包装好的类,具体定义了一个网络层,可以维护状态和存储参数信息;而nn.functional仅仅提供了一个计算,不会维护状态信息和存储参数。在Module类内部,层的功能其实又是通过nn.functional来实现的。
(当然常见的损失函数有很多,后续可以做一篇专项总结)
二、动态调整学习率
学习速率设置过小,会极大降低收敛速度,增加训练时间;学习率太大,可能导致参数在最优解两侧来回振荡。
使用官方scheduler
PyTorch已经在torch.optim.lr_scheduler封装了动态调整学习率的方法,具体scheduler罗列如下:
lr_scheduler.LambdaLR
lr_scheduler.MultiplicativeLR
lr_scheduler.StepLR
lr_scheduler.MultiStepLR
lr_scheduler.ExponentialLR
lr_scheduler.CosineAnnealingLR
lr_scheduler.ReduceLROnPlateau
lr_scheduler.CyclicLR
lr_scheduler.OneCycleLR
lr_scheduler.CosineAnnealingWarmRestarts
官方使用教程说明及解释
# 选择一种优化器
optimizer = torch.optim.Adam(...)
# 选择上面提到的一种或多种动态调整学习率的方法
scheduler1 = torch.optim.lr_scheduler....
scheduler2 = torch.optim.lr_scheduler....
...
schedulern = torch.optim.lr_scheduler....
# 进行训练
for epoch in range(100):
train(...)
validate(...)
optimizer.step()
# 需要在优化器参数更新之后再动态调整学习率
scheduler1.step()
...
schedulern.step()
自定义scheduler
虽然PyTorch官方已经提供了丰富的API,但是为了应对繁复的实验项目,仍然需要自己定义学习率调整策略,示例如下:
誓言要i去学习率没30论下降为原来的1、10,假设官方API无法满足该需求,则需进行如下定义:
def adjust_learning_rate(optimizer, epoch):
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
在训练过程中,调用adjust_learning_rate函数可以实现学习率的动态变化。
def adjust_learning_rate(optimizer,...):
...
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):
train(...)
validate(...)
adjust_learning_rate(optimizer,epoch)
三、模型微调-torch vision、timm
torchvision
微调流程(如图所示)
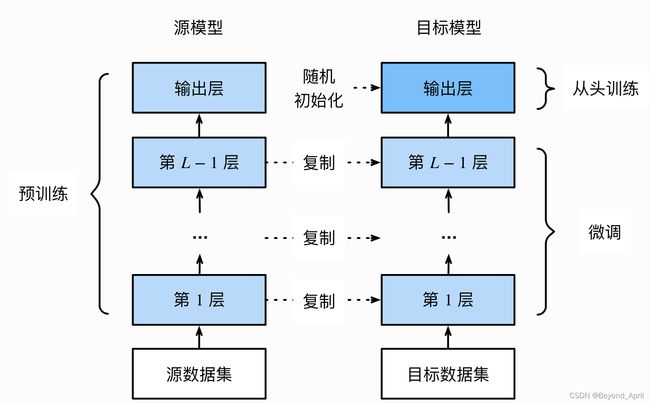
使用已有的结构
以torchvision中的常见模型为例,列出了如何在图像分类任务中使用PyTorch提供的常见模型结构和参数。
实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
传递pretrained参数
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
注意事项
1.PyTorch模型的扩展通常为.pt/.pth,程序运行时会首先检查默认路径中是否有已经下载过的模型权重,一旦有过下载,下次加载就不需要重新下载。
2.为了提高模型下载的速度,可以手动下载:去这里查看模型的module_urls,并自行下载,默认保存路径如下:
Linux、mac:用户根目录下的.cache文件夹
Windows:C:\Users
torch.utils.model_zoo.load_url()设置权重的下载地址
3.还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络。
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
4.如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,要不然可能会报错。
训练特定层
1.设置requires_grad = False来冻结部分层.
在PyTorch官方中提供了这样一个例程。
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
2.对模型输出部分的全连接层进行修改
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=num_ftrs, out_features=4, bias=True)
3.之后在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。
timm(自行了解)
注意:在jupyter notebook上运行经常出现xxx not defined,有可能是因为前面的块没有运行过,全部重新运行一次就可能解决问题。
四、半精度训练
半精度训练是为了提高显卡的使用效率(确切说是通过减少显存的占用,来让其能加载更多的数据)
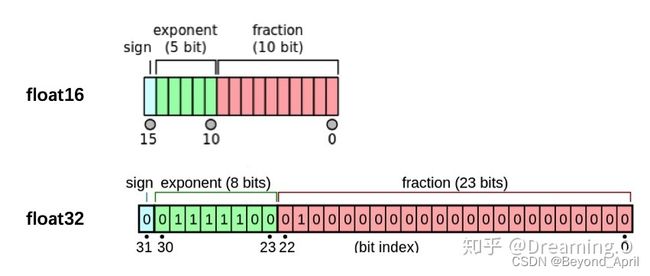
在PyTorch中设置半精度训练
import autocast
from torch.cuda.amp import autocast
模型设置:使用python的装饰器方法
@autocast()
def forward(self, x):
...
return x
训练过程:将数据输入模型及其之后的部分放入“with autocast():"。
for x in train_loader:
x = x.cuda()
with autocast():
output = model(x)
...
拓展
1.另外一种设置半精度的方法:GradScaler
GradScaler就是梯度scaler模块,需要在训练最开始之前实例化一个GradScaler对象。
因此PyTorch中经典的AMP使用方式如下:
from torch.cuda.amp import autocast as autocast
# 创建model,默认是torch.FloatTensor
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
2.遇到的坑——出现nan怎么解决
计算loss 时,出现了除以0的情况
loss过大,被半精度判断为inf
网络参数中有nan,那么运算结果也会输出nan
五、数据增强-imgaug
imgaug的安装
conda
conda config --add channels conda-forge
conda install imgaug
pip
# install imgaug either via pypi
pip install imgaug
# install the latest version directly from github
pip install git+https://github.com/aleju/imgaug.git
imgaug在PyTorch的使用
这里没有固定的模板,建议自己在使用过程中依据问题找答案。
六、使用argparse进行调参
argparse 的简介
argsparse是python的命令行解析的标准模块,内置于python,不需要安装,可以将命令行传入的其他参数进行解析、保存和使用
argparse 的使用
- 创建ArgumentParser()对象
- 调用add_argument()方法添加参数
- 使用parse_args()解析参数
# demo.py
import argparse
# 创建ArgumentParser()对象
parser = argparse.ArgumentParser()
# 添加参数
parser.add_argument('-o', '--output', action='store_true',
help="shows output")
# action = `store_true` 会将output参数记录为True
# type 规定了参数的格式
# default 规定了默认值
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--batch_size', type=int, required=True, help='input batch size')
# 使用parse_args()解析函数
args = parser.parse_args()
if args.output:
print("This is some output")
print(f"learning rate:{args.lr} ")
在命令行输入
python demo.py --lr 3e-4 --batch_size 32
输出
This is some output
learning rate: 3e-4
argparse 的进阶
1.为了使代码更加简洁和模块化,可以将有关超参数的操作写在config.py,然后在train.py或者其他文件导入。(来自ZhikangNiu)
2.(未完待续)
……
七、参考文档
来自Datawhale的投喂
在线教程链接:
https://datawhalechina.github.io/thorough-pytorch/
Github在线教程:
https://github.com/datawhalechina/thorough-pytorch
Gitee在线教程:
https://gitee.com/datawhalechina/thorough-pytorch
b站视频:
https://www.bilibili.com/video/BV1L44y1472Z
(欢迎大家一键三连+关注!)
来自官方的投喂
Github链接:
https://github.com/rwightman/pytorch-image-models
官网链接:
https://fastai.github.io/timmdocs/ https://rwightman.github.io/pytorch-image-models/
来自广大网友的投喂
pytorch教程之损失函数详解
https://blog.csdn.net/qq_27825451/article/details/95165265
解决半精度训练出现nan的方法
https://github.com/huggingface/transformers/issues/4287
imgaug在PyTorch的使用
https://github.com/aleju/imgaug/issues/406
argparse模块用法实例详解
https://zhuanlan.zhihu.com/p/56922793
总结
1.在这一章我更加体会到我们教程设置的精妙之处,往往能够让读者明白某一种方法出现或升级的上下因果,清晰明了。像我们的项目贡献者致谢。
2.教程中涉及的很多内容由于时间限制往往只能展示核心部分,其实在实践过程中仍然会出现各种各样的问题,需要惯于收集和整理参考资料。
3.本章的学习让我有一点点体会到计算机基础学习的意义,比如深入了解硬件有时可以帮助我们更好地进行算法学习。
4.再次向Datawhale的小伙伴们致谢,特别是队内的Dennis博士和奇奇同学。