Anaconda+TensorFlow安装配置过程
Win8.1+TensorFlow1.14+Pyhton3.7+CUDA10
这几天一直在配置 Python 环境,遇到了许多坑。决定开一篇文章,记录一下自己的踩坑过程,避免在将来重装时遇到同样的问题。同时也分享给同样要做 Python 开发的小伙伴们,希望你们能少走一些弯路。
近几年数据科学与大数据的发展直接促使Python编程语言作为大众化的主力编程语言,主要原因有以下几点
- 语法简单
- 各领域的 Package 十分充足
- 开发效率高
我在这里安装的是 Anaconda + Pycharm 。所以也介绍这两个的安装
Anaconda
Anaconda指的是一个开源的Python发行版本,是管理 Python 环境(environment)和包(package)的一个软件。
- Environment :Python 的各种版本,比如 Python 2.7 或者 3.5 ,3.6等
- Package : 各种开源的包,调用包中的函数来完成任务
管理各种的 Python 环境与各种的包是一件非常麻烦的事情,但是我们有了 Anaconda 这个软件,让我们对 python 的各种操作变得更容易了!
安装
首先进入 Anaconda 的官网 点击右上角的 Download,进入下载页面,根据操作系统下载相应的版本:

下载好之后双击打开,前面过程下一步就行,到步后: 假如你的电脑有好几个 Users ,才需要考虑这个问题.其实我们电脑一般就一个 User,就我们一个人使用,如果你的电脑有多个用户,选择All Users,我这里直接 All User,继续点击 Next 。

有些 Windows 的电脑默认安装是C盘的一个隐藏文件夹,这就导致有时候安装包没有权限,同时用 PyCharm的时候无法读取Anaconda的虚拟环境。并且,Anaconda 与后期的各种 Python 环境,包会占用非常大的空间。所以,建议将 Anaconda 安装到系统盘之外!
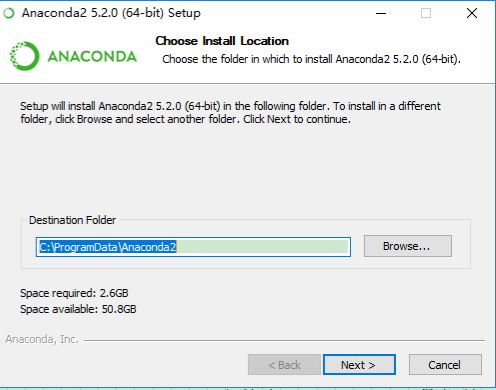
高级选项这里,不要勾选第一项。我们手动添加变量环境到 %Path%。
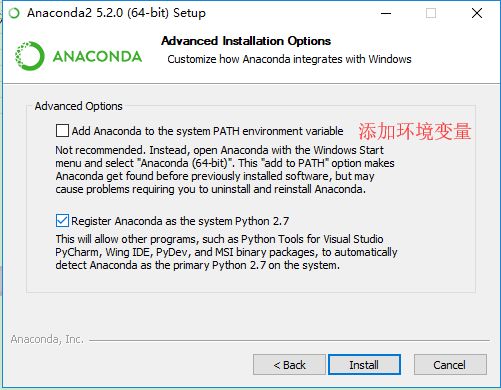
之后一直下一步就行,不建议改动。安装好之后我们添加变量环境:
右键计算机 —> 属性 —> 高级系统设置 -----> 变量环境

点击 编辑

将一下路径添加到变量中。我的是安装在 D 盘中,文件夹为 Anaconda3 ,把这两个改成你自己的。
D:\Anaconda3\
D:\Anaconda3\Scripts
D:\Anaconda3\Library\bin
D:\Anaconda3\Library\mingw-w64\bin
之后就可以打开命令行输入 conda --version。如果输出了版本号说明安装成功。!!
管理虚拟环境
安装完成后会有一个 Anaconda Prompt,叫做终端,是Shell的一种。
输入 conda list 或者 pip list 会把已经安装的包显示出来
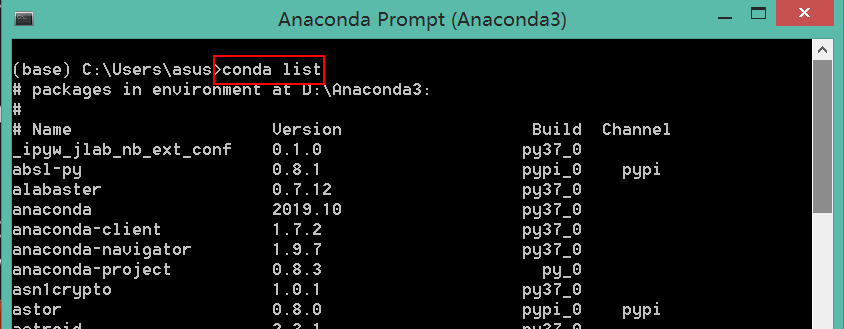
通过 conda info 可以查看某个包的的详细信息。
可以看到最前面有一个 (base),说明我们此时在 这个环境下。你可以输入python试试, 这样会进入base环境的python解释器。可以输入 exit() 退出。

我们当然不满足一个base环境, 我们应该为自己的程序安装单独的虚拟环境。用下面的命令可以创建新的环境
conda create --name .environment.name> python=3.7 numpy scipy
就是创建一个名为numpy和 scipy 表示我们在安装这个环境的时候把这两个包也装上。
我们可以通过下面的命令删除某个环境
conda remove --name --all
假设我创建了一个名为 tensorflow 名称的一个python环境,通过“ conda activate <环境名称>” 来进入那个环境中

通过 conda deactivate 来退出环境,回到 base 中

如果忘记了环境名称,可以查看一下所有的环境 :conda env list 或者 conda info ---envs
安装环境包
-
输入
conda install或者pip install来安装某个包。 -
pip install可以安装指定某个版本。=x.x.x pip只是一个包管理器,所以它不能为你管理环境。pip 甚至不能升级 python,因为它不像conda一样把python当做包来处理。但是它可以安装一些conda安装不了的包。
-
输入
pip install --upgrade来更新某个包。 -
conda update --all可以把所有包都更新一下
我们把这三个包更新一下
pip install --upgrade numpy
pip install --upgrade pandas
pip install --upgrade scipy
- 卸载包:
pip uninstall
推荐安装的 Python 环境包
- numpy (Data Manipulation)
- pandas (Data Analyze)
- scipy (Scientific Computation)
- matplotlib and seaborn (Drawing Figures)
- scikit-learn (Machine Learning)
安装TensorFlow
版本可以自己选择,如果没有选择版本默认安装最新的,我这里指定的gpu的1.14版本。
国内安装包速度慢,建议是用清华大学镜像
pip install tensorflow-gpu==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
国内的话请在pip install 后面加上-i https://pypi.tuna.tsinghua.edu.cn/simple这句话,这样下载速度更快些!
豆瓣的镜像:http://pypi.douban.com/simple/
中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
其他常用命令可以查看 https://blog.csdn.net/fyuanfena/article/details/52080270
Pycharm
Pycharm 是一款非常强大的编辑器。使用它的原因是这款软件的代码补全和提示功能做的特别特别好!所以写代码来说会省不少事情!
下载版本有社区版Community 与专业版Professional,建议下载专业版,可以免费试用一个月或者使用学校的邮箱去申请一年的免费试用。
这个官网由于某些原因上不去,所以大家自己想办法搭梯子或者找其他安装方法。
安装完成 PyCharm 之后,我们需要用 PyCharm 读取 Anaconda 创建的虚拟环境
首先 Create New Project

在 Location 填写你选择的工作路径,叫做Project,这个路径很有用,选择的这个文件夹地址将会是文件读取的相对路径。
在 Existing interpreter 处的 Interpreter 点击后面的三个点。
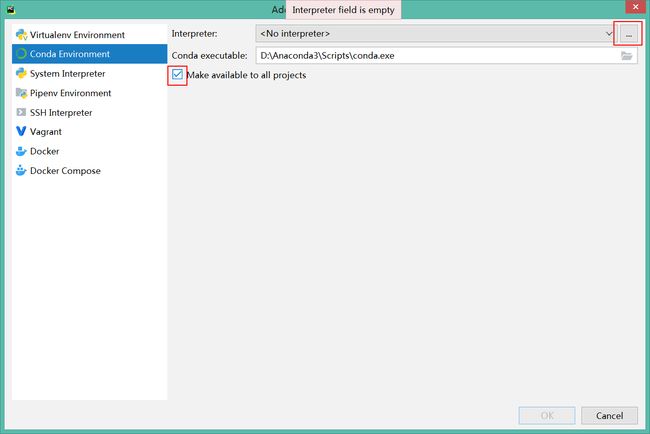
在这个页面, Interpreter 后的点选择路径
首先,找到安装Anaconda的文件夹;然后找 envs 这个文件夹,就是安装的环境的路径,在 TensorFlow 中找到 python.exe

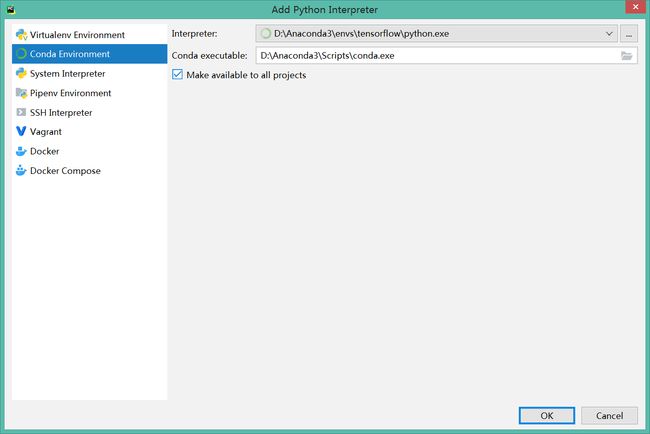
这样就可以了。
打开PyCharm的界面也可以进行环境的配置,先选择界面上的设置 。选择左侧的Project;里面选择Python Interpreter;右上角选择小齿轮的设置;后续读取Anaconda创建环境中的操作和上面一样。

CUDA & cuDNN
提前告知:在安装 CUDA 的过程中,你可能会遇到很多很多坑!!要有耐心!(QAQ)
如果要用英伟达的显卡去加速训练深度学习模型,需要安装CUDA和CuDnn。注意:TensorFlow 版本 ,CUDA版本,CuDnn版本三者要对应。
CUDA是NVIDIA推出的用于自家GPU的并行计算框架,也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。 CUDA的本质是一个工具包(ToolKit)。而 cuDNN是一个SDK,是一个专门用于神经网络的加速包。
CUDA 的下载地址 https://developer.nvidia.com/cuda-toolkit-archive
cuDNN 下载地址: https://developer.nvidia.com/rdp/cudnn-download
没有账号需要注册账号,账号登录后,找到自己对应的CUDA版本,点击下载。下载后就是个压缩文件。
网上有说 CUDA 版本要和电脑的显卡有关,要先看英伟达控制面板 CUDA 版本,然后下载对应版本的CUDA。我试过了,我的电脑一开始是CUDA7.5,安装之后 TensorFlow1.14不支持,所以我就直接下载了 CUDA10 发现能用,而且英伟达控制面板里的CUDA 版本也变为10了。
下图为 windows 系统中的版本对应,其他系统百度都能找到。
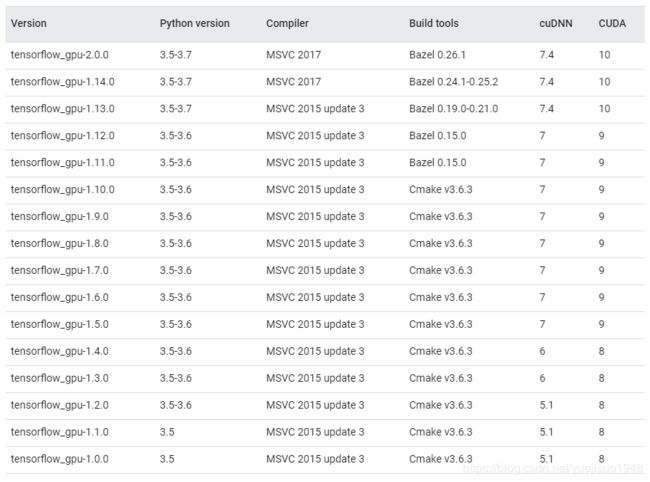
安装 CUDA
我们之前安装的是 TensorFlow1.14.0 所以安装 CUDA10
找到 CUDA 版本,根据操作系统下载。有 network 和 local 两种。network 版安装的时候要联网,一般就 十几MB。而local 版则是离线安装,已经把所有组建下载了,因此一般在2GB左右。我用的是离线版。
选择自定义

下面注意 CUDA 是必装的,如果你的 Display Driver 当前版本比新版本还要高就不装,新版本大于就当前版本就装。这里建议大家安装新版本,如果不更新 Display Driver 的话,在导入 tensorflow 包的时候可能会出现 CUDA驱动版本不满足CUDA运行版本 的错误。

这里我就默认C盘了

这一步很重要:下面检测你的电脑中是否有Visual Studio 环境(因为我的电脑里已经有了VS,所以没有那个界面了,大家知道就好)。 可能会要求你的电脑中有 Visual Studio,如果没有的话要勾选一个选项才能下一步(选项说的就是你的电脑中没有VS环境,是否继续?)如果你继续安装 CUDA 八成装不上,不要问我为什么(QAQ)。所以下载一个VS去吧!我用的是 VS2017 版本。
安装好之后,打开路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin (改成你自己的安装路径),查看nvcc.exe,有这个nvcc.exe就说明CUDA安装已成功.
打开路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64,查看有没有cuti64_100.dll (如果安装的是10.1版本则是cuti64_101.dll )有这个cuti64_101.dll就说明CUPT1已成功
配置cuDNN
解压cuDNN后,将对应的bin、lib、include与CUDA10对应的bin、lib、include进行合并。

就是把 cuDNN 中的文件 复制 到 CUDA10 安装目录下对应的文件夹中。每个文件都像下面这样!
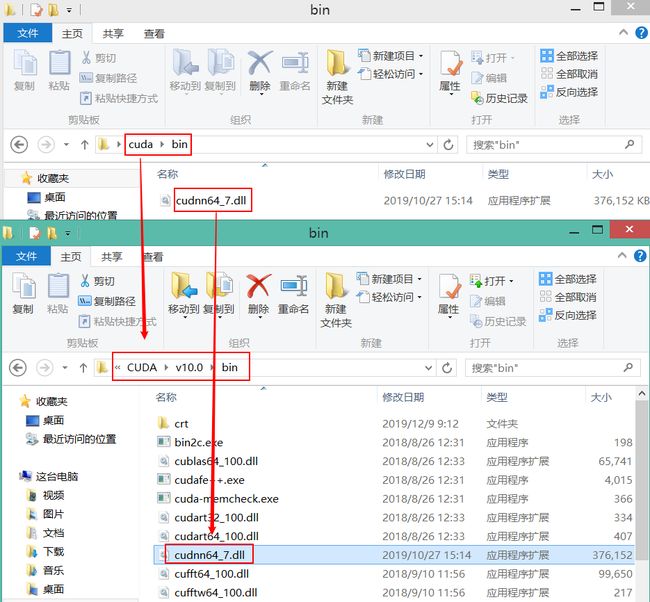
配置环境变量
安装完CUDA后,CUDA会自动添加到环境变量中,多了 CUDA_PATH 和 CUDA_PATH_V10_0
CUPTA和CUDNN还没有加进来,所以必须将它们添加到路径,这样使用Tensorflow的时候才不会报错 。
将下面几个变量添加到 Path 中,跟前面 Anaconda 一样
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\extras\CUPTI\libx64;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.0\bin\win64;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.0\common\lib\x64;
测试 CUDA
输入 nvcc -V

代码测试
import tensorflow as tf
sess = tf.Session(config=tf.compat.v1.ConfigProto(log_device_placement=True))
from __future__ import print_function
import tensorflow as tf
a = tf.constant(2)
b = tf.constant(3)
add = tf.add(a,b)
sess = tf.Session()
print('a+b= ',sess.run(add))
sess.close()
如果有报错,根据报错信息上网查一下解决方案。
参考资料
Win10安装CUDA10和cuDNN