Machine Learning with Python Cookbook 学习笔记 第14章
Chapter 14. Trees and Forests
前言
- 本笔记是针对人工智能典型算法的课程中Machine Learning with Python Cookbook的学习笔记
- 新学期开始大三了,太忙了,这个系列估计更新的会非常缓慢
- 学习的实战代码都放在代码压缩包中
- 实战代码的运行环境是python3.9 numpy 1.23.1 **anaconda 4.12.0 **
- 上一章:(97条消息) Machine Learning with Python Cookbook 学习笔记 第11章_五舍橘橘的博客-CSDN博客
- 代码仓库
- Github:yy6768/Machine-Learning-with-Python-Cookbook-notebook: 人工智能典型算法笔记 (github.com)
- Gitee: 机器学习笔记代码仓库: 主要存放一些笔记和代码 第一期主要围绕Machine Learning with Python Cookbook的学习笔记和代码 (gitee.com)
14.0 Introduction
-
树与森林算法是非常广泛使用的机器学习算法,有如下特性:
- 监督学习算法
- 非参数
- 适用于分类和回归问题
-
基于树的学习模型是决策树:
- 决策树有许多节点,每个节点存储一条决策规则
- 从根节点到叶子结点一次进行决策的判断
-
树模型的一个好处是:可解属性
14.1 Training a Decision Tree Classifier
-
创建一棵决策树
-
DecisionTreeClassifier -
decision_tree_classifier.py
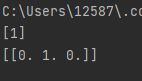
# Load libraries from sklearn.tree import DecisionTreeClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # 创建一棵决策树 decisiontree = DecisionTreeClassifier(random_state=0) # 训练模型 model = decisiontree.fit(features, target) # Make new observation observation = [[5, 4, 3, 2]] # Predict observation's class预测类 print(model.predict(observation)) # 预测属于各个类的概率 print(model.predict_proba(observation)) # Create decision tree classifier object using 信息熵 decisiontree_entropy = DecisionTreeClassifier( criterion='entropy', random_state=0) # Train model model_entropy = decisiontree_entropy.fit(features, target)
Discussion
- 决策树希望从混杂类别中找到一种划分规则
- scikit-learn的
DecisionTreeClassifier使用Gini impurity(基尼指数)来衡量混杂度- G ( t ) = 1 − Σ i = 1 c p i 2 G(t) = 1 - \Sigma_{i=1}^cp_i^2 G(t)=1−Σi=1cpi2
- G(t)是基尼指数, p i p_i pi是每个类的比例
- 根据基尼指数的大小来使用属性来划分数据集,直到所有节点的属性都是纯的(递归调用)
- 训练完毕后可以预测样本的类
model.predict(observation),也可以查看概率model.predict_proba(observation)
-
如果使用不一样的指标,可以使用
criterion参数来指定:# Create decision tree classifier object using 信息熵 decisiontree_entropy = DecisionTreeClassifier( criterion='entropy', random_state=0) # Train model model_entropy = decisiontree_entropy.fit(features, target)
14.2 Training a Decision Tree Regressor
- 使用决策树来训练回归模型
scikit-learn’s DecisionTreeRegressor- decision_tree_regressor.py
# Load libraries
from sklearn.tree import DecisionTreeRegressor
from sklearn import datasets
# Load data with only two features
boston = datasets.load_boston()
features = boston.data[:, 0:2]
target = boston.target
# Create decision tree classifier object
decisiontree = DecisionTreeRegressor(random_state=0)
# 训练模型
model = decisiontree.fit(features, target)
# Make new observation
observation = [[0.02, 16]]
# 预测
model.predict(observation)
decisiontree_mae = DecisionTreeRegressor(random_state=0, criterion='mae')
model_mae = decisiontree_mae.fit(features, target)
Discussion
-
类似于分类器,决策树回归模型只是把Gini(entropy)换成了MSE:
- M S E = Σ i = 1 n ( y ^ i − y i ) 2 MSE = \Sigma_i=1^n(\hat y_i - y_i)^2 MSE=Σi=1n(y^i−yi)2
- y i y_i yi是目标值, y ^ i \hat y_i y^i是线性模型的预测值
-
DecisionTreeRegressor:-
预测:predict(observation)
-
更改标准:criterion
# 预测 model.predict(observation) decisiontree_mae = DecisionTreeRegressor(random_state=0, criterion='mae') model_mae = decisiontree_mae.fit(features, target)
-
14.3 Visualizing a Decision Tree Model
- 使一棵决策树可视化
- 导出为
DOT格式 - visualize_tree_model.py
# Load libraries
import pydotplus
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
from IPython.display import Image
from sklearn import tree
# Load data
iris = datasets.load_iris()
features = iris.data
target = iris.target
# Create decision tree classifier object
decisiontree = DecisionTreeClassifier(random_state=0)
# Train model
model = decisiontree.fit(features, target)
# 创建DOT数据
dot_data = tree.export_graphviz(decisiontree,
out_file=None, #导出的文件
feature_names=iris.feature_names,
class_names=iris.target_names)
# Draw graph
graph = pydotplus.graph_from_dot_data(dot_data)
# Show graph
Image(graph.create_png())
# pdf文件
graph.write_pdf("iris.pdf")
# png图片
graph.write_png("iris.png")
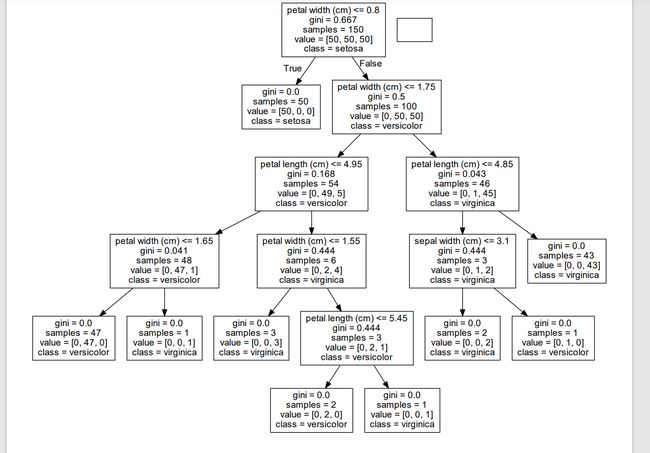
Discussion
-
我们可以查看决策树模型,这也就是为什么大家认为决策树是最可解释的模型之一
-
可以导出为DOT图格式,还可以生成PDF或者PNG
-
需要安装pydotplus,我在跑的时候还遇到了问题
pydotplus.graphviz.InvocationException: GraphViz's executables not found

如果使用conda环境一定要conda的包
conda install pydotplus
conda install graphviz
14.4 Training a Random Forest Classifier
- 训练一个随机森林的分类器
RandomForestClassifier- random_forest_classifier.py
# Load libraries
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# Load data
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 训练一个随机森林算法
randomforest = RandomForestClassifier(random_state=0, n_jobs=-1)
# 训练模型
model = randomforest.fit(features, target)
# 创建新的样本集
observation = [[5, 4, 3, 2]]
# 预测
print(model.predict(observation))
# 使用信息熵来作为指标训练随机森林
random_forest_entropy = RandomForestClassifier(
criterion="entropy", random_state=0)
# Train model
model_entropy = random_forest_entropy.fit(features, target)
print(model_entropy.predict(observation))
Discussion
- 对于决策树而言最大的问题就是容易过拟合
- 解决这个问题需要使用随机森林(Random Forest)
- 随机森林算法会训练很多个不同的决策树
- 每个决策树会通过Bootstrap(自助法)的方法获得一部分的样本集(非全部)
- 每棵树的结果进行对样本进行投票来进行预测
RandomForestClassifiern_estimators表示多少个树组成,默认是10random_state每颗树的生成模式criterion表示判别标准,常用的有gini、entropymax_features决定最多一个节点会考虑多少个特征,默认情况下,max_features的值会设置为sqrt,也就是说有n个属性,那么一个节点会考虑 n \sqrt n n个属性bootstrap表示是否使用自助法(如果为True,那么采样会放回,也就是说数据集中可能出现相同的数据)n_jobs制定多少核来训练
14.5 Training a Random Forest Regressor
-
训练随机森林的回归模型
-
RandomForestRegressor -
random_forest_regressor.py
# Load libraries from sklearn.ensemble import RandomForestRegressor from sklearn import datasets # Load data with only two features boston = datasets.load_boston() features = boston.data[:,0:2] target = boston.target # Create random forest classifier object randomforest = RandomForestRegressor(random_state=0, n_jobs=-1) # Train model model = randomforest.fit(features, target)
Discussion
- 类比
RandomForestClassifier和DecisionTreeClassifier和RandomForestRegressor和DecisionTreeRegressor的关系:- max_features:默认 p \sqrt p p
- bootstrap默认是true
- n_estimators默认是10
14.6 Identifying Important Features in Random Forests
- 获得森林中最终要的特征
- 使用importace_指标排序
- feature_importance.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# 莺尾花数据集
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 随机森林分类器
randomforest = RandomForestClassifier(random_state=0, n_jobs=-1)
# 模型训练
model = randomforest.fit(features, target)
# 计算特征的重要程度
importances = model.feature_importances_
# 排序
indices = np.argsort(importances)[::-1]
# 重排
names = [iris.feature_names[i] for i in indices]
plt.figure()
plt.title("Feature Importance")
plt.bar(range(features.shape[1]), importances[indices])
# 添加特征名到X轴
plt.xticks(range(features.shape[1]), names, rotation=0)
# 显示图
plt.show()
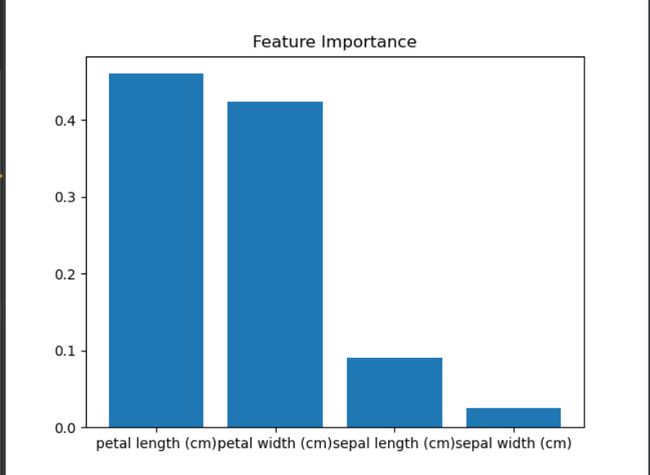
怎么结果还和书上有点不一样,可能还是有点随机性的
Discussion
-
随机森林是可解释的,这意味着我们可以计算出什么样的特征是对于模型最重要的
-
scikit-learn的内部实现随机森林有两点需要注意:
- 将多分类特征分解为多个二进制特征。
- 如果两个特征高度线性相关,那么他会默认让一个特征很重要,另个特征的重要性很低
-
feature_importances_访问模型各个特征的重要性
- 值越大越重要
14.7 Selecting Important Features in Random Forests
- 通过随机森林进行特征选择
- 使用14.6节的方式选择最重要的几项特征
- feature_selection.py
# 库
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn.feature_selection import SelectFromModel
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 随机僧林分类器
randomforest = RandomForestClassifier(random_state=0, n_jobs=-1)
# 设置阈值
selector = SelectFromModel(randomforest, threshold=0.3)
# 新的特征矩阵
features_important = selector.fit_transform(features, target)
# 训练
model = randomforest.fit(features_important, target)
Discussion
- 特征选择在前面的章节已经介绍过很多方法了,往往是通过方差的方式来选择最好的训练特征
- scikit通常使用两步骤的工作流(two-stage workflow)创建模型
- 第一步使用原始的特征矩阵训练,得到初始的决策树,通过这棵决策树计算出每个特征的重要程度
- 第二步使用
SelectFromModel通过指定阈值threshold来筛选特征的重要性 - 最后使用新的特征来训练决策树
- 警告:
- one-hot编译的特征会被多分类特征使用二进制而稀释,理解起来就是假设8个分类的特征要创建3组二进制特征表示,而one-hot编码的特征需要创建8个特征,此时因为one-hot很稀疏,他的重要性显得很低
- 线性相关的特征,他们的重要性会集中在一个特征上,而不是平分在两个特征上
14.8 Handling Imbalanced Classes
- 使用不平衡的类来训练数据
- 参数
class_weight=balanced - imbalance_classes.py
# 库
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# 数据
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 高度不平衡的数据(让除了0以外的类为1类)
features = features[40:, :]
target = target[40:]
# 除了0其他都是1
target = np.where((target == 0), 0, 1)
# Create random forest classifier object
randomforest = RandomForestClassifier(
random_state=0, n_jobs=-1, class_weight="balanced")
# 训练模型
model = randomforest.fit(features, target)
Discussion
-
使用class_weight参数来为每个类加权
- 可以接受字典dict作为参数{“male”: 0.2, “female”: 0.8}
- 也可以指明是balanced
-
ω j = n k n j \omega_j = \frac{n}{kn_j} ωj=knjn
- $\omega_j $表示类的系数
- n表示总的样本数,k表示总共的类数, n j n_j nj表示第j类有多少个样本
-
这样的话系数和该类的样本数成反比,那么小的类会获得更高的权重
14.9 Controlling Tree Size
-
控制树的大小
-
通过结构参数来控制
-
tree_size.py
# Load libraries from sklearn.tree import DecisionTreeClassifier from sklearn import datasets # Load data iris = datasets.load_iris() features = iris.data target = iris.target # Create decision tree classifier object decisiontree = DecisionTreeClassifier(random_state=0, max_depth=None, # 最大深度 min_samples_split=2, # 内部有节点最小的样本数 min_samples_leaf=1, # 叶子节点最小的样本数 min_weight_fraction_leaf=0, max_leaf_nodes=None, # 最大叶子节点数 min_impurity_decrease=0) # 最小脏度 # Train model model = decisiontree.fit(features, target)
Discussion
主要介绍了scikit-learn’s DecisionTreeClassifier(Regessor)的一些限制参数
-
max_depth
树的最大深度。
None就说明决策树的所有叶子都是纯类 -
min_samples_split
非叶子节点最小的样本数量。
- 整数值表示最小样本数量
- 浮点数表示最小样本占总数据集的比例
-
min_samples_leaf
叶子节点最小的样本数量
- 整数值
- 浮点数表示最小样本占比
-
max_leaf_nodes
最大叶子节点数量数量
-
min_impurity_split
节点分裂所需的最小脏度(这里应该指的是诸如交叉信息熵等)
14.10 Improving Performance Through Boosting
-
性能更优秀的学习模型
-
AdaBoostClassifierAdaBoostRegressor -
boosting.py
# Load libraries
from sklearn.ensemble import AdaBoostClassifier
from sklearn import datasets
# Load data
iris = datasets.load_iris()
features = iris.data
target = iris.target
# Create adaboost tree classifier object
adaboost = AdaBoostClassifier(random_state=0)
# Train model
model = adaboost.fit(features, target)
Discussion
-
相对于随机森林,提升(集成)(Boosting)往往有更好的性能
-
常用的boosting方法叫做AdaBoost
- 迭代训练一组weak models(常见的就是一组深度较浅的决策树,通常被称为stump)
- 将之前预测错的样本赋予更高的优先级(权重更高)
-
AdaBoost:
- 为每一个样本赋予一个权重 w i = 1 n w_i= \frac{1}{n} wi=n1,n是样本总数
- 预先训练一个“weak model"
- 对于每一次预测:
- 弱模型预测正确,那么增加 w i w_i wi的大小
- 弱模型预测错误,减小 w i w_i wi的大小
- 使用上一轮带权重的数据集来重新训练一个“weak model”
- 重复步骤4-5直到数据集训练完成或者或者预先设置的数量的模型被训练完成
-
这里感觉原文并没有写很清楚,实际上有两个权值,弱模型和样本都有权值
-
样本权值更新:
对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突显出来,从而得到一个新的样本分布。
-
弱分类器权值更新:
对于准确率较高的弱分类器,加大其权重;对于准确率较低的弱分类器,减小其权重。
-
-
AdaBoostClassifierAdaBoostRegressor- base_estimator 如训练集的模型,默认参数是决策树(性能几乎是最好的)
- n_estimators(预先设定的期望的模型个数)
- learning_rate(学习率,描述的是每一次模型变化的速率)
- loss AdaBoostRegressor特有,设置损失函数来评估当前 w i w_i wi,默认的是线性损失函数,常用的有square和exponential
14.11 Evaluating Random Forests with Out-ofBag Errors
- 评估当前的随机森林模型
- 使用
out-of-bag评分
# Load libraries
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# Load data
iris = datasets.load_iris()
features = iris.data
target = iris.target
# Create random tree classifier object
randomforest = RandomForestClassifier(
random_state=0, n_estimators=1000, oob_score=True, n_jobs=-1)
# Train model
model = randomforest.fit(features, target)
# View out-of-bag-error
randomforest.oob_score_
![]()
Discussion
- out-of-bag (OOB)
- 使用自助法(boostraped)自集训练,总有样本可能没有在训练集合中,我们将这种样本成为out-of-bag(OOB)
- 我们可以用OOB来评估决策树的训练结果
- OOB是交叉检验(cv)的替代方法
oob_score=True来设置随机森林使用OOB评估,通过访问randomforest.oob_score_查看最后的oob得分