监督学习之广义线性模型
到目前为止,我们已经见到了一个回归的例子和一个分类的例子。在回归的例子里,我们有![]() ,在分类问题中我们有
,在分类问题中我们有![]() ,
,![]() 和
和![]() 是某些合适定义的
是某些合适定义的![]() 和
和![]() 的函数。在这节中,我们将会展示这两个方法都是一个更广泛模型族的特殊情况,(这个模型)被称作广义线性模型(GLMs)。我们也会展示GLM族的其他模型如何推导得出,如何被应用到其他分类和回归问题。
的函数。在这节中,我们将会展示这两个方法都是一个更广泛模型族的特殊情况,(这个模型)被称作广义线性模型(GLMs)。我们也会展示GLM族的其他模型如何推导得出,如何被应用到其他分类和回归问题。
8 指数族
为了走进GLMs,我们将会以定义指数族分布作为开始。我们说一类分布在指数族如果它能被写成这样的形式。这里,
一个固定的
我们现在证明伯努利和高斯分布式指数族分布的例子。均值为
完全变成这类伯努利分布。
我们把伯努利分布写作:

因此,自然参数
 。有趣地是,如果我们根据
。有趣地是,如果我们根据
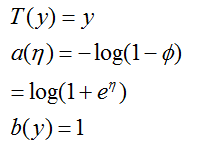
这证明了伯努利分布通过选择合适的
的形式。
现在让我们继续考虑高斯分布。回想一下,当推导线性回归时,

因此,我们可以看到高斯分布属于指数族,并且

还有很多其他的属于指数族的分布:多项式分布(我们稍后会看到),泊松分布(用于计数建模;也看下习题集);伽马分布和指数分布(用来建模连续的,非负的随机变量,比如时间间隔);贝塔分布和狄利克雷分布(概率分布),还有更多的;在下节中,我们将会描述一个构建模型的一般“配方”,在模型中,![]() (给定
(给定![]() 和
和![]() )源自这些分布中的任何一个。
)源自这些分布中的任何一个。
假定你想基于某些特征
一般地说,考虑一个分类或者回归问题,在这些问题中,我们想预测一些作为![]() 的函数的随机变量
的函数的随机变量![]() 的值。为了得到这个问题的一个GLM,我们将会做出以下三个假设,这些假设是关于给定
的值。为了得到这个问题的一个GLM,我们将会做出以下三个假设,这些假设是关于给定![]() 下的
下的![]() 的条件分布和我们的模型:
的条件分布和我们的模型:
2.给定
3.自然参数![]() 和输入值
和输入值![]() 是线性关系:
是线性关系:![]() 。(或者,如果
。(或者,如果![]() 值是一个向量,然后
值是一个向量,然后![]() )
)
9.1 普通最小二乘
为了证明普通最小二乘是GML族的一个特殊情况,考虑这样的环境,目标变量
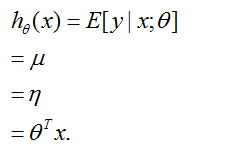
第一个等式由假设2给出;第二个等式由
第三个等式由假设1(我们之前的推导证明了在高斯分布作为一个指数族分布的公式化表示时有![]() )得出。最后一个等式由假设3得到。
)得出。最后一个等式由假设3得到。
我们现在考虑逻辑回归。这里我们对二值分类有兴趣,所以
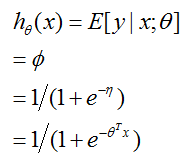
所以,这给出了形式为![]() 的假设函数。如果你之前想知道我们如何想出逻辑函数
的假设函数。如果你之前想知道我们如何想出逻辑函数![]() 这样的形式,这给出了一个答案:一旦我们假定以
这样的形式,这给出了一个答案:一旦我们假定以![]() 为条件的
为条件的![]() 是伯努利,它作为GMLs定义和指数族分布的结果出现。
是伯努利,它作为GMLs定义和指数族分布的结果出现。
多介绍一点术语,以自然参数为自变量的函数![]() 是用分布的均值定义的,这样的函数
是用分布的均值定义的,这样的函数![]() (
(![]() )被称作典型的反应函数(canoical response function)。它的逆(即反函数),
)被称作典型的反应函数(canoical response function)。它的逆(即反函数),![]() ,被称作典型的连接函数(canonical link funtion)。因此,高斯分布族的典型的反应函数恰恰是恒等函数;伯努利的典型反应函数是逻辑函数。
,被称作典型的连接函数(canonical link funtion)。因此,高斯分布族的典型的反应函数恰恰是恒等函数;伯努利的典型反应函数是逻辑函数。
让我们再看一个GLM的例子。考虑一个分类问题,在这个分类问题中,反应变量
让我们堆到一个为这种多项式数据建模的GLM。为了做这个,我们将先从把多项式分布表示成指数族分布开始。
为了参数化一个有k个可能输出结果的多项式分布,我们可以使用k个参数
为了把这个多项式分布表示一个指数族分布,我们将定义

不像我们以前的例子,这里我们不再有
我们再介绍一个非常有用的符号。知识函数1{·}值为1如果它的参数是真的,否则是0(1{True}=1,1{False}=0)。比如,1{2=3}=0,1{3=5-2}=1。所以,我们也可以把
我们现在准备证明多项式分布是一个指数族分布。我们有:

这里
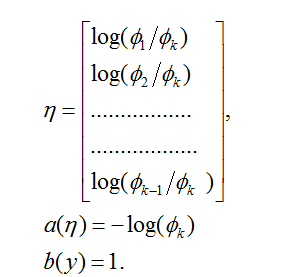
这完成了我们的多项式分布作为指数族分布的公式化表示。
连接函数由

给出。为了方便,我们也定义了
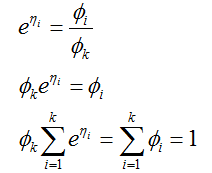
这表明![]() ,并带回到上式,得到反应函数
,并带回到上式,得到反应函数

这个从
 映射到
映射到
 的函数被称作 softmax函数。
的函数被称作 softmax函数。
为了完成我们的模型,我们使用之前给出的假设3,和是线性关系。所以,有![]() ,这里
,这里![]() 是我们模型的参数。为了符号上的方便,我们也可以定义
是我们模型的参数。为了符号上的方便,我们也可以定义![]() ,以致
,以致![]() ,正如之前给出的一样。因此,我们的模型假定给定
,正如之前给出的一样。因此,我们的模型假定给定![]() 下的
下的![]() 的条件分布由
的条件分布由
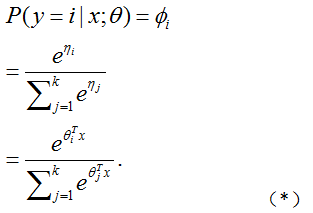
给出。
这个(应用到
我们的假设将输出

换句话说,我们的假设将会输出i=1,2,...,k中的每一个i值的估计概率
最后,让我们讨论参数拟合。类似于我们原来普通最小二乘和逻辑回归的推导,如果我们有一个m个样例的训练集
 ,我们首先写下log似然性
,我们首先写下log似然性

为了得到上式中的第二行,我们使用了等式(*)中的![]() 的定义。通过使用一个诸如梯度上升或者牛顿法的方法就
的定义。通过使用一个诸如梯度上升或者牛顿法的方法就![]() 来最大化
来最大化![]() ,我们现在可以得到参数的最大似然估计。
,我们现在可以得到参数的最大似然估计。