分布式机器学习_分布式机器学习之参数服务器(PS)详解

为了更好的了解分布式机器学习,深入理解参数服务器的理念及设计是必要的。结合最近看的李沐大神参数服务器的论文,加深对PS的理解,故整理此文。
Parameter server 使用缩写PS
提出参数服务器框架来解决分布式机器学习问题,数据和计算工作量都分布到Client节点,而服务器节点维护全局共享的参数,这些参数为稀疏向量和矩阵。PS 维护 Client和Server 之间的异步数据通信。支持灵活的一致性模型、弹性可扩展性和容错性。我们提出了挑战非凸和非光滑问题的算法和理论分析。为了验证该框架的可扩展性,我们给出了数十亿参数的真实数据的实验结果。1. 概述
分布式优化和推理在解决大规模机器学习问题中正变得越来越流行。使用机器集群可以解决以下问题:由于观测数据和参数数量的增长,没有任何一台机器可以足够快地解决这些问题。但是,实现高效的分布式算法并不容易。大量的计算工作量和数据通信量都需要仔细的系统设计。 目前大家比较熟知的通用机器学习系统有Spark MLI、Mahout等,基于Spark的MLI采用迭代MapReduce框架,虽然Spark由于保留了状态并执行了优化策略,因此在很大程度优于Hadoop MapReduce,这种方式使用的是同步迭代通信模型,这使得它们容易受到迭代机器学习算法(即在任何给定时间可能恰好变慢的机器)的非均匀性能分布的影响。基于个人的了解,现有的Angel系统应该也是在paper上实现的,并克服了这些问题。Parameter Server不仅被直接应用在各大公司的机器学习平台上,而且也被集成在TensorFlow,MXNet等主流的深度框架中,作为机器学习分布式训练最重要的解决方案。 许多推理问题在参数化方面有一个有限的结构,比如广义线性模型通常使用单个大参数向量,或者主题模型使用稀疏向量数组 在本文中,我们主要介绍基于参数服务器的分布式优化方法,在此模型中,机器节点分为client和server,每个client拥有一部分数据和计算任务,server端维护全局的共享参数,这种架构思想并不新鲜,它已经被应用于很多的机器学习应用中,包括潜变量模型、分布式图推理和深度学习。但是在这里所阐述的是做一个通用的参数服务器系统,它可以作为分布式机器学习的一个组件。鉴于这样的目标,它应该具备哪些功能特征如下:- 易于使用:全局共享参数可表示为(可能是稀疏的)向量和矩阵,与广泛使用的(键、值)存储或表相比,它们是机器学习应用程序更方便的数据结构。为便于开发应用,提供了参数与局部训练数据向量矩阵相乘等高性能、方便的多线程线性代数运算。
- 性能:节点之间的通信是异步的。重要的是,同步不会阻塞计算。该框架允许算法设计者平衡算法收敛速度和系统效率,其中最佳的权衡取决于数据、算法和硬件。
- 弹性可伸缩可以添加新节点,而无需重新启动正在运行的系统, 这样的特性是需要的,例如使用流式框架,或将参数服务器部署为必须长时间保持可用的在线服务。我们使用分布式哈希表来允许新服务器节点随时动态地插入到集合中。
- 容错相反,节点故障是不可避免的,特别是在使用商用服务器的情况下。例如,3年的MTBF(平均无故障时间)等于每天在1,000个节点上发生一次故障。调度程序抢占可以在工业部署中大大提高该速率。我们使用优化的数据复制体系结构,该体系结构可将数据有效地存储在多个服务器节点上,以实现从节点故障中快速恢复(不到1秒)。此外,由于客户端节点彼此独立,因此当一个客户端发生故障时,可以自动启动新客户端,其方式与MapReduce能够重新计划新映射器的方式相同。

2. 参数服务器设计要点
从上面的参数服务器架构中看出,包含两类节点,每个服务器节点维护全局共享参数的部分区(默认情况下,机器本地参数不同步),它们之间相互通信通过复制、迁移参数以实现可靠性和扩展性。Client节点做计算任务,Server节点做参数的记录保存以及全局聚合,每个client通常会在本地存储一部分训练数据,计算诸如梯度的本地统计数据,client只与server节点进行通信,获取和更新共享参数,可以添加和删除client,这样做需要将训练数据集的适当部分传输到新机器,并查询相应的参数集。 对于不同的算法,参数服务器可以同时支持多个独立的参数向量(即信道)。例如,当服务器可能正在存储一些节点正在主动查询的操作模型的参数时,同时还使用一组不同的client节点来训练新模型以供将来使用时,这很有用。这种方法极大地简化了模型更新和部署,因为这些都只需要由client来切换通道即可。模型应用示例
下面介绍一个简单的模型,
通过分布式次梯度迭代将风险最小化。目的是解决形式的优化问题

训练过程
具体来讲,下图以伪码方式列出了Parameter Server并行梯度下降的主要步骤: PS并行梯度下降过程
PS并行梯度下降过程
可以看到Parameter Server由server节点和worker节点组成,其主要功能分别如下:
server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,push给server节点。
在物理架构上,PS其实是和spark的master-worker的架构基本一致的,如下图:
 PS的物理架构 可以看到,PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
PS的物理架构 可以看到,PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
- server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源;
- 每个worker group对应一个application(即一个模型训练任务),worker group之间,以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
 PS并行训练流程示意图
PS并行训练流程示意图
通过上面的介绍可以清楚的知道PS的并行梯度下降流程,其中最关键的两个操作就是push和pull:
push:worker节点利用本节点上的训练数据,计算好局部梯度,上传给server节点;
pull:为了进行下一轮的梯度计算,worker节点从server节点拉取最新的模型参数到本地。
上面的操作,也是在论文中介绍的接口定义,现有的机器学习平台实现也使用了这样的定义。
下面通过一个Angel的一个示例了解整个PS的分布式训练流程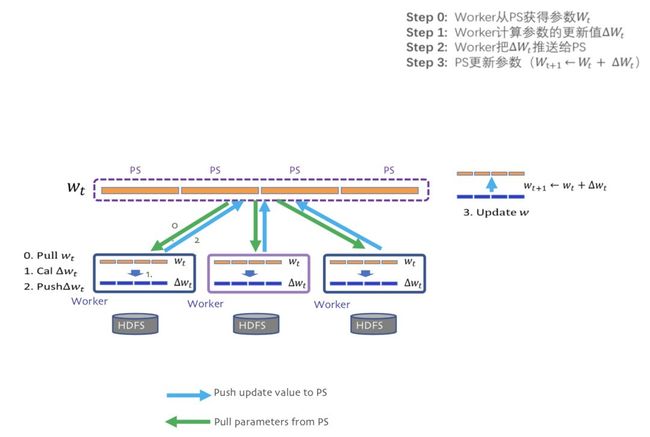
每个worker载入一部分训练数据
worker节点从server节点pull最新的模型参数
worker节点利用本节点数据计算梯度
worker节点将梯度push到server节点
server节点汇总梯度更新模型
goto step2 直到迭代次数上限或模型收敛
Server节点的协同和效率问题
导致Spark MLlib并行训练效率低下的另一原因是每次迭代都需要master节点将模型权重参数的广播发送到各worker节点。这导致两个问题:- master节点作为一个瓶颈节点,受带宽条件的制约,发送全部模型参数的效率不高;
- 同步地广播发送所有权重参数,使系统整体的网络负载非常大。

PS server节点组成的一致性哈希环
PS的server group中应用一致性哈希的原理大致有如下几步:
将模型参数的key映射到一个环形的hash空间,比如有一个hash函数可以将任意key映射到0~(2^32)-1的hash空间内,我们只要让(2^32)-1这个桶的下一个桶是0这个桶,那么这个空间就变成了一个环形hash空间;
根据server节点的数量n,将环形hash空间等分成n*m个range,让每个server间隔地分配m个hash range。这样做的目的是保证一定的负载均衡性,避免hash值过于集中带来的server负载不均;
在新加入一个server节点时,让新加入的server节点找到hash环上的插入点,让新的server负责插入点到下一个插入点之间的hash range,这样做相当于把原来的某段hash range分成两份,新的节点负责后半段,原来的节点负责前半段。这样不会影响其他hash range的hash分配,自然不存在大量的rehash带来的数据大混洗的问题。
删除一个server节点时,移除该节点相关的插入点,让临近节点负责该节点的hash range。
PS server group中应用一致性哈希原理,其实非常有效的降低了原来单master节点带来的瓶颈问题。比如现在某worker节点希望pull新的模型参数到本地,worker节点将发送不同的range pull到不同的server节点,server节点可以并行的发送自己负责的weight到worker节点。
此外,由于在处理梯度的过程中server节点之间也可以高效协同,某worker节点在计算好自己的梯度后,也只需要利用range push把梯度发送给一部分相关的server节点即可。当然,这一过程也与模型结构相关,需要跟模型本身的实现结合起来实现。总的来说,PS基于一致性哈希提供了range pull和range push的能力,让模型并行训练的实现更加灵活。
3. 总结
参数服务器就类似于MapReduce,是大规模机器学习在不断使用过程中,抽象出来的框架之一。重点支持的就是训练数据、参数的分布式,毕竟巨大的模型其实就是巨大的参数。PS成为TensorFlow、MXNet等框架的核心组件,Angel更是以PS为基础衍生出自己的一套生态平台。后面继续从每个核心功能点深入分析。
相关文章:
1. Angel基于参数服务器的规模分布式机器学习平台
2.Angel分布式机器学习平台—LR算法示例
3.Angel中的损失函数详解
4.一文彻底搞懂Angel机器学习平台