【读点论文】Image Style Transfer Using Convolutional Neural Networks(将卷积特征图提取语义信息,融合内容和风格的做法)
Image Style Transfer Using Convolutional Neural Networks
- 以不同风格呈现图像的语义内容是一项困难的图像处理任务。可以说,以前的方法的一个主要限制因素是缺乏明确表示语义信息的图像表示,从而允许将图像内容与样式分开。在这里,本文使用的图像表示来自卷积神经网络优化对象识别,使高层次的图像信息明确。
- 本文介绍了一种艺术风格的神经算法,可以分离和重组自然图像的图像内容和风格。该算法允许产生高感知质量的新图像,该图像将任意照片的内容与众多知名艺术品的外观相结合。产生的结果为卷积神经网络学习的深层图像表示提供了新的见解,并展示了它们在高级图像合成和处理方面的潜力。
- 2016年的CVPR论文,本文章用CNN网络来做图像风格迁移,作者是Gatys。Gatys在2015年的时候就发过一篇关于图像风格迁移的文章:A Neural Algorithm of Artistic Style,这两篇文章的内容很相似。
Introduction
- 将样式从一幅图像转移到另一幅图像可以被认为是纹理转移的问题。在纹理传递中,目标是从源图像合成纹理,同时约束纹理合成,以便保留目标图像的语义内容。
- 对于纹理合成,存在大量强大的非参数算法,这些算法可以通过对给定源纹理的像素进行重采样来合成照片般逼真的自然纹理。大多数先前的纹理传递算法依赖于这些用于纹理合成的非参数方法,同时使用不同的方法来保持目标图像的结构。
- Efros和Freeman引入了一个对应图,其中包括目标图像的特征,如图像强度,以约束纹理合成过程。Hertzman等人使用图像类比将纹理从已经样式化的图像转移到目标图像上。Ashikhmin专注于传输高频纹理信息,同时保留目标图像的粗糙尺度。Lee等人通过向纹理传递额外通知边缘方向信息来改进该算法。
- 尽管这些算法取得了显著的效果,但它们都有相同的基本限制:它们只使用目标图像的低层图像特征来实现纹理传递。然而,理想地,风格迁移算法应该能够从目标图像(例如,对象和一般场景)中提取语义图像内容,然后实现纹理转移过程以源图像的风格呈现目标图像的语义内容。
- 因此,一个基本的先决条件是找到图像表示,独立地模拟语义图像内容及其呈现风格的变化。这种因式分解的表示以前仅针对自然图像的受控子集实现,例如不同照明条件下的人脸和不同字体风格的字符或手写数字和门牌号。
- 从自然图像中分离内容和风格仍然是一个极其困难的问题。然而,深度卷积神经网络的最新进展已经产生了强大的计算机视觉系统,该系统可以学习从自然图像中提取高级语义信息。研究表明,在特定任务(如对象识别)中使用足够的标记数据进行训练的卷积神经网络可以学习提取通用特征表示中的高级图像内容,这些特征表示可以概括数据集,甚至可以用于其他视觉信息处理任务,包括纹理识别和艺术风格分类。
- 在这项工作中,本文展示了高性能卷积神经网络学习的通用特征表示如何用于独立处理和操作自然图像的内容和风格。本文介绍了一种艺术风格的神经算法,一种新的图像风格转换算法。从概念上讲,它是一种纹理传递算法,通过来自最新卷积神经网络的特征表示来约束纹理合成方法。
- 由于纹理模型也基于深度图像表示,风格转移方法优雅地简化为单个神经网络内的优化问题。通过执行前图像搜索以匹配示例图像的特征表示来生成新图像。这种通用方法以前已经在纹理合成的环境中使用过,用于提高对深层图像表示的理解。事实上,本文的风格迁移算法结合了基于卷积神经网络的参数纹理模型和反转其图像表示的方法。
Deep image representations
-
在VGG网络的基础上生成的,该网络被训练来执行对象识别和定位,并且在原始工作中被广泛描述。本文使用由VGG-19网络的16个卷积层和5个池层的标准化版本提供的特征空间。
-
通过缩放权重来归一化网络,使得每个卷积滤波器在图像和位置上的平均激活等于1。可以在不改变其输出的情况下对VGG网络进行这种重新缩放,因为它仅包含校正线性激活函数,而没有归一化或池化特征图。不使用任何完全连接的层。
-
该模型是公开可用的,可以在caffe框架中进行研究。对于图像合成,发现用平均池替换最大池操作会产生稍微更吸引人的结果,这就是为什么显示的图像是用平均池生成的(和A Neural Algorithm of Artistic Style表述一模一样)。
-
Content representation(和A Neural Algorithm of Artistic Style运用的方法一模一样)
-
通常,网络中的每一层都定义了一个非线性滤波器组,其复杂度随着该层在网络中的位置而增加。因此,给定的输入图像 x → \overrightarrow{x} x通过对该图像的滤波器响应而在卷积神经网络的每一层中被编码。具有 N l N_l Nl个不同过滤器的图层具有 N l N_l Nl个大小为 M l M_l Ml的特征图,其中 M l M_l Ml是特征图的高度乘以宽度。第L层中的响应可以存储在矩阵 F l ∈ R N l × M l F_l∈R_{N_l×M_l} Fl∈RNl×Ml中,其中 F i j l F^l_{ij} Fijl是层l中位置j处的第i个滤波器的激活。
-
为了可视化在层级的不同层编码的图像信息,可以对白噪声图像执行梯度下降,以找到与原始图像的特征响应相匹配的另一个图像。设 p → \overrightarrow{p} p和 x → \overrightarrow{x} x是原始图像和生成的图像, P l P_l Pl和 F l F_l Fl是它们在层l中各自的特征表示。然后定义两个特征表示之间的平方误差损失
-
L c o n t e n t ( p → , x → , l ) = 1 2 ∑ i , j ( F i j l − P i j l ) 2 L_{content}(\overrightarrow{p},\overrightarrow{x},l)=\frac{1}{2}\sum_{i,j}(F_{ij}^l-P_{ij}^l)^2 Lcontent(p,x,l)=21i,j∑(Fijl−Pijl)2
-
def _content_loss(self, P, F): """ 计算content loss :param P: 内容图像的feature map :param F: 合成图片的feature map """ self.content_loss = tf.reduce_sum(tf.square(F - P)) / (4.0 * P.size) #reduce_sum() 是求和函数,为压缩求和,用于降维
-
-
这个损失相对于层l中的激活的导数等于
- ∂ L c o n t e n t ∂ F i j l = { ( F l − P l ) i j i f F i j l > 0 0 i f F i j l < 0 \frac{\partial{L_{content}}}{\partial{F_{ij}^l}}=\begin{cases} (F^l-P^l)_{ij} &{if \space F^l_{ij}>0}\\ 0 &{if \space F^l_{ij}<0}\\ \end{cases} ∂Fijl∂Lcontent={(Fl−Pl)ij0if Fijl>0if Fijl<0
-
由此可以使用标准误差反向传播来计算相对于图像 x → \overrightarrow{x} x的梯度。因此,可以改变最初的随机图像 x → \overrightarrow{x} x,直到它在卷积神经网络的某一层中产生与原始图像 p → \overrightarrow{p} p相同的响应。
-
当卷积神经网络在对象识别上被训练时,它们开发了图像的表示,使得对象信息沿着处理层级越来越明显。因此,沿着网络的处理层次,输入图像被转换成对图像的实际内容越来越敏感的表示,但是对其精确的外观变得相对不变。
-
因此,网络中的较高层根据对象及其在输入图像中的排列来捕获高级内容,但是不太约束重建的精确像素值。相比之下,较低层的重建只是复制了原始图像的精确像素值。因此,将网络高层中的特征响应称为内容表示。
-
-
Style representation
-
为了获得输入图像风格的表示,使用了一个被设计用来捕捉纹理信息的特征空间。这个特征空间可以建立在网络的任何层中的滤波器响应之上。它由不同滤波器响应之间的相关性组成,其中期望是在特征图的空间范围上获得的。这些特征相关性由Gram矩阵 G l ∈ R N l × N l G_l∈R^{N_l×N_l} Gl∈RNl×Nl给出,其中 G i j l G^l_{ij} Gijl是层l中的矢量化特征图i和j之间的内积:
-
G i j l = ∑ k F i k l F j k l G_{ij}^l=\sum_k{F^l_{ik}F^l_{jk}} Gijl=k∑FiklFjkl
-
def _gram_matrix(self, F, N, M): """ 构造F的Gram Matrix(格雷姆矩阵),F为feature map,shape=(widths, heights, channels) :param F: feature map :param N: feature map的第三维度 :param M: feature map的第一维 乘 第二维 :return: F的Gram Matrix """ F = tf.reshape(F, (M, N)) return tf.matmul(tf.transpose(F), F)
-
-
通过包括多层的特征相关性,获得了输入图像的静态、多尺度表示,其捕获了其纹理信息,但没有捕获全局排列。可以通过构建一个与给定输入图像的风格表示相匹配的图像,将这些建立在网络不同层上的风格特征空间捕获的信息可视化。这是通过使用来自白噪声图像的梯度下降来最小化来自原始图像的Gram矩阵和要生成的图像的Gram矩阵的条目之间的均方距离来实现的。
-
设 a → \overrightarrow{a} a和 x → \overrightarrow{x} x是原始图像和生成的图像, A l A_l Al和 G l G_l Gl是它们在层l中各自的风格表示。则该层对总损失的贡献 E l E_l El和总损失L如下
-
E l = 1 4 N l 2 M l 2 ∑ i , j ( G i j l − A i j l ) 2 L s t y l e ( a → , x → ) = ∑ l = 0 L w l E l E_l=\frac{1}{4N^2_lM^2_l}\sum_{i,j}(G_{ij}^l-A_{ij}^l)^2\\ L_{style}(\overrightarrow{a},\overrightarrow{x})=\sum_{l=0}^L{w_lE_l} El=4Nl2Ml21i,j∑(Gijl−Aijl)2Lstyle(a,x)=l=0∑LwlEl
-
def _single_style_loss(self, a, g): """ 计算单层style loss :param a: 当前layer风格图片的feature map :param g: 当前layer生成图片的feature map :return: style loss """ N = a.shape[3] M = a.shape[1] * a.shape[2] # 生成feature map的Gram Matrix A = self._gram_matrix(a, N, M) G = self._gram_matrix(g, N, M) return tf.reduce_sum(tf.square(G - A)) / ((2 * N * M) ** 2)
-
-
其中 w l w_l wl是每层对总损失的贡献的加权因子。 E l E_l El相对于层l中激活的导数可以解析地计算:
- ∂ E L ∂ F i j l = { 1 N l 2 M l 2 ( ( F l ) T − ( G l − A l ) ) i j i f F i j l > 0 0 i f F i j l < 0 \frac{\partial{E_L}}{\partial{F_{ij}^l}}=\begin{cases} \frac{1}{N^2_lM^2_l}((F^l)^T-(G^l-A^l))_{ij} &{if \space F^l_{ij}>0}\\ 0 &{if \space F^l_{ij}<0}\\ \end{cases} ∂Fijl∂EL={Nl2Ml21((Fl)T−(Gl−Al))ij0if Fijl>0if Fijl<0
-
使用标准误差反向传播可以容易地计算 E l E_l El相对于像素值 x → \overrightarrow{x} x的梯度
-
-
Style transfer
-
为了将艺术作品 a → \overrightarrow{a} a的风格转移到照片 p → \overrightarrow{p} p上,合成了一个新的图像,它同时匹配 p → \overrightarrow{p} p的内容表示和 a → \overrightarrow{a} a的风格表示(见下图)。
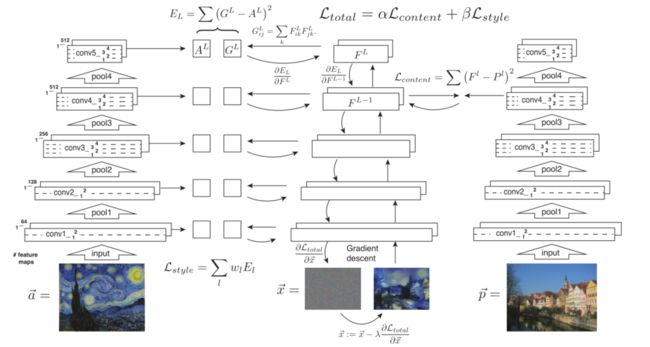
- Style transfer algorithm.首先提取并存储内容和风格特征。样式图像 a → \overrightarrow{a} a通过网络传递,并且计算和存储它在包括的所有层上的样式表示 A l A^l Al(左图)。内容图像 p → \overrightarrow{p} p通过网络传递,存储一层中的内容表示 P l P^l Pl(右图)。
- 然后,使随机白噪声图像 x → \overrightarrow{x} x通过网络,并计算其风格特征 G l G^l Gl和内容特征 F l F^l Fl。在包括在样式表示中的每个层上,计算 G l G^l Gl和 A l A^l Al之间的元素方式均方差,以给出样式损失 L s t y l e L_{style} Lstyle(左图)。此外,计算 F l F^l Fl和 P l P^l Pl之间的均方差,以给出内容损失 L c o n t e n t L_{content} Lcontent(右图)。
- 总损失 L t o t a l L_{total} Ltotal是内容和风格损失之间的线性组合。它相对于像素值的导数可以使用误差反向传播来计算(中间)。这个梯度用于迭代更新图像 x → \overrightarrow{x} x,直到它同时匹配样式图像 a → \overrightarrow{a} a的样式特征和内容图像 p → \overrightarrow{p} p的内容特征(中间,底部)。
-
联合最小化白噪声图像的特征表示与卷积神经网络的一层中的照片的内容表示和多层上定义的绘画的风格表示之间的距离。最小化的损失函数是:
-
L t o t a l ( p → , a → , x → ) = α L c o n t e n t ( p → , x → ) + β L s t y l e ( a → , x → ) L_{total}(\overrightarrow{p},\overrightarrow{a},\overrightarrow{x})=αL_{content}(\overrightarrow{p},\overrightarrow{x})+βL_{style}(\overrightarrow{a},\overrightarrow{x}) Ltotal(p,a,x)=αLcontent(p,x)+βLstyle(a,x)
-
def losses(self): """ 模型总体loss """ with tf.variable_scope("losses"): # contents loss with tf.Session() as sess: sess.run(self.input_img.assign(self.content_img)) #tensorflow的 构建视图、构建操作... 都只是在预定义一些操作/一些占位,并没有实际的在跑代码,一直要等到 session.run 才会 实际的去执行某些代码 gen_img_content = getattr(self.vgg, self.content_layer) content_img_content = sess.run(gen_img_content) self._content_loss(content_img_content, gen_img_content) # style loss with tf.Session() as sess: sess.run(self.input_img.assign(self.style_img)) style_layers = sess.run([getattr(self.vgg, layer) for layer in self.style_layers]) self._style_loss(style_layers) # 加权求得最终的loss self.total_loss = self.content_w * self.content_loss + self.style_w * self.style_loss
-
-
其中α和β分别是内容和风格重建的加权因子。相对于像素值 ∂ L t o t a l ∂ x → \frac{∂Ltotal}{∂\overrightarrow{x}} ∂x∂Ltotal的梯度可以用作一些数值优化策略的输入。这里我们使用L-BFGS [32],发现它最适合图像合成。
-
为了在可比较的尺度上提取图像信息,在计算其特征表示之前,总是将样式图像调整到与内容图像相同的大小。最后,注意与[Understanding Deep Image Representations by Inverting Them.]不同的是,没有用图像先验来正则化合成结果。然而,来自网络中较低层的纹理特征充当风格图像的特定图像先验。此外,由于本文使用不同的网络架构和优化算法,预计图像合成会有一些差异。
-
-
Results
-
本文的主要发现是卷积神经网络中内容和风格的表示是很好分离的。也就是说,可以独立地操作这两种表征来产生新的、感知上有意义的图像。为了演示这一发现,本文生成了混合了来自两个不同源图像的内容和样式表示的图像。特别是,将一张描绘德国图宾根内卡河河岸的照片的内容表示与取自不同艺术时期的几幅著名艺术作品的风格表示进行了匹配(见下图【与2015年的论文一模一样】)。

- 将一张照片的内容与几幅著名艺术作品的风格相结合的图像。通过找到同时匹配照片的内容表示和艺术品的风格表示的图像来创建图像。
- 描绘德国图宾根Neckarfront的原始照片显示在A中(摄影:Andreas Praefcke)。为相应生成的图像提供样式的绘画显示在每个面板的左下角。B是J.M.W. Turner于1805年所作的《弥诺陶洛斯的沉船》。C是文森特·梵高1889年创作的《星夜》。D是爱德华·蒙克1893年的《画报》。E是巴勃罗·毕加索1910年创作的《被遗弃的女人》。F是瓦西里·康丁斯基1913年创作的Composition VII。
-
上图所示的图像是通过匹配层conv4_2上的内容表示和层conv1_1、conv2_1、conv3_1、conv4_1和conv5_1上的风格表示合成的(在这些层中wl = 1/5,在所有其他层中wl = 0)。比值α/β为 1 × 1 0 − 3 1×10^{-3} 1×10−3(B)、 8 × 1 0 − 4 8×10^{-4} 8×10−4©、 5 × 1 0 − 3 5×10^{-3} 5×10−3(D), 5 × 1 0 − 4 5×10^{-4} 5×10−4(E、F)。
-
# 定义提取特征的层(与论文的内容呼应) self.content_layer = "conv4_2" self.style_layers = ["conv1_1", "conv2_1", "conv3_1", "conv4_1", "conv5_1"] ##匹配了层“conv4_2”上的内容表示和层conv1_1、conv2_1、conv3_1、conv4_1和conv5_1上的样式表示 # 定义content loss和style loss的权重,根据论文可自调整 self.content_w = 0.001 self.style_w = 1 ##可自调整测试实验效果 self.style_layer_w = [0.5, 1.0, 1.5, 3.0, 4.0] #不同style layers的权重,层数越深权重越大
-
-
Trade-off between content and style matching
- 当然,图像内容和风格不能完全分开。当合成将一个图像的内容与另一个图像的风格相结合的图像时,通常不存在同时完美匹配两个约束的图像。
- 然而,由于在图像合成过程中最小化的损失函数是分别针对内容和风格的损失函数之间的线性组合,所以可以平滑地调节对重建内容或风格的强调(见下图)。

- 各个源图像的匹配内容和风格的相对权重。匹配内容和匹配样式之间的比率α/β从左上到右下增加。**对风格的高度强调有效地产生了风格图像的纹理版本(左上)。对内容的高度强调产生了一个只有很少风格化的图像(右下)。**实际上,人们可以在两个极端之间平滑地插值。
- 对风格的强烈强调将产生与艺术品外观相匹配的图像,有效地给出其纹理版本,但几乎不显示照片的任何内容(α/β= 1 × 1 0 − 4 1×10^{-4} 1×10−4,上图,左上角)。当重点强调内容时,人们可以清楚地识别照片,但绘画风格不太匹配(α/β= 1 × 1 0 − 1 1×10^{-1} 1×10−1,上图,右下方)。对于特定的一对内容和样式图像,可以调整内容和样式之间的折衷,以创建视觉上吸引人的图像。
-
Effect of different layers of the Convolutional Neural Network
- 图像合成过程中的另一个重要因素是选择与内容和风格表示相匹配的层。如上所述,风格表示是包括多层神经网络的多尺度表示。这些层的数量和位置决定了风格匹配的局部尺度,导致不同的视觉体验。
- 将样式表示匹配到网络中的更高层会在越来越大的范围内保持局部图像结构,从而导致更平滑和更连续的视觉体验。因此,视觉上最吸引人的图像通常是通过将样式表示与网络中的高层相匹配来创建的,这就是为什么对于所示的所有图像,本文都在网络的层“conv1_1”、“conv2_1”、“conv3_1”、“conv4_1”和“conv5_1”中匹配样式特征。
- 为了分析使用不同图层来匹配内容特征的效果,提供了一个样式转换结果,该结果是通过使用相同的插图和参数配置(α/β= 1 × 1 0 − 3 1×10^{-3} 1×10−3)对照片进行样式化而获得的,但其中一个图层与图层“conv2_2”上的内容特征相匹配,另一个图层与图层“conv4_2”上的内容特征相匹配(见下图)。

- 在网络的不同层中匹配内容表示的效果。匹配图层“conv2_2”上的内容保留了原始照片的大部分精细结构,合成图像看起来好像绘画的纹理简单地混合在照片上(中间)。
- 匹配图层“conv4_2”上的内容时,绘画的纹理和照片的内容会融合在一起,这样照片的内容就会以绘画的风格显示出来(上图底部)。两幅图像均采用相同的参数选择(α/β= 1 × 1 0 − 3 1×10^{-3} 1×10−3)生成。左下角显示的是作为风格图像的画作,由利奥尼·法宁格于1915年命名为耶稣会士三世。
- 当在网络的较低层上匹配内容时,该算法匹配照片中的许多细节像素信息,并且生成的图像看起来好像艺术品的纹理仅仅混合在照片上(上图,中间)。相比之下,当在网络的较高层上匹配内容特征时,照片的详细像素信息没有被强烈地约束,并且艺术作品的纹理和照片的内容被适当地合并。也就是说,改变图像的精细结构,例如边缘和彩色图,使得它在显示照片内容时与艺术品的风格一致(上图,底部)。
-
Initialisation of gradient descent
- 已经用白噪音初始化了目前显示的所有图像。然而,也可以用内容图像或风格图像来初始化图像合成。研究了这两种选择(见下图 A,B):虽然它们使最终图像偏向初始化的空间结构,但是不同的初始化似乎对合成过程的结果没有强烈的影响。应该注意的是,只有带噪声的初始化才允许生成任意数量的新图像(见下图 C)。用固定图像初始化总是确定地导致相同的结果(直到梯度下降过程中的随机性)。

- 梯度下降的初始化。A:从内容映像初始化的。B:从样式图像初始化。C:从不同的白噪声图像初始化的四个图像样本。对于所有图像,比值α/β等于 1 × 1 0 − 3 1×10^{-3} 1×10−3。
- 已经用白噪音初始化了目前显示的所有图像。然而,也可以用内容图像或风格图像来初始化图像合成。研究了这两种选择(见下图 A,B):虽然它们使最终图像偏向初始化的空间结构,但是不同的初始化似乎对合成过程的结果没有强烈的影响。应该注意的是,只有带噪声的初始化才允许生成任意数量的新图像(见下图 C)。用固定图像初始化总是确定地导致相同的结果(直到梯度下降过程中的随机性)。
-
Photorealistic style transfer
- 到目前为止,本文的重点是艺术风格的转移。不过一般来说,该算法可以在任意图像之间转换风格。作为一个例子,把纽约夜晚的照片风格转换成伦敦白天的图像(见下图)。虽然照片真实感没有完全保留,但合成的图像类似于风格图像的许多颜色和闪电,并在某种程度上显示了伦敦的夜景。

- 照片真实感风格转移。这种风格从一张展示纽约夜景的照片转移到一张展示伦敦夜景的照片上。图像合成从内容图像初始化,比率α/β等于 1 × 1 0 − 2 1×10^{-2} 1×10−2.
- 到目前为止,本文的重点是艺术风格的转移。不过一般来说,该算法可以在任意图像之间转换风格。作为一个例子,把纽约夜晚的照片风格转换成伦敦白天的图像(见下图)。虽然照片真实感没有完全保留,但合成的图像类似于风格图像的许多颜色和闪电,并在某种程度上显示了伦敦的夜景。
Discussion
- 本文演示了如何使用高性能卷积神经网络的特征表示来在任意图像之间传递图像风格。虽然能够显示高感知质量的结果,但是该算法仍然存在一些技术限制。
- 可能最大的限制因素是合成图像的分辨率。优化问题的维数以及卷积神经网络中的单元数量都随着像素数量线性增长。因此,合成过程的速度很大程度上取决于图像分辨率。本文中展示的图像是以大约512 × 512像素的分辨率合成的,合成过程可能需要在Nvidia K40 GPU上花费长达一个小时的时间(取决于确切的图像大小和梯度下降的停止标准)。虽然这种性能目前阻碍了本文的风格转移算法的在线和交互式应用,但很可能深度学习的未来改进也将提高这种方法的性能。
- 另一个问题是,合成图像有时会受到一些低水平噪声的影响。虽然这在艺术风格转换中不是什么大问题,但是当内容和风格图像都是照片并且合成图像的真实感受到影响时,问题就变得更加明显了。然而,噪声是非常典型的,看起来像网络中单元的滤波器。因此,有可能构建有效的去噪技术来在优化过程之后对图像进行后处理(从问题提出未来研究方向)。
- 传统上,图像的艺术风格化是在非真实感渲染的标签下在计算机图形学中研究的。除了在纹理传递方面的工作,普通的方法在概念上与我们的工作有很大的不同,因为它们给出了专门的算法来以一种特定的风格渲染源图像。关于该领域的最新综述,可以参阅[A Taxonomy of Artistic Stylization Techniques for Images and Video.]。
- 图像内容与风格的分离不一定是一个明确定义的问题。这主要是因为不清楚到底是什么定义了图像的风格。它可能是绘画中的笔触、彩色地图、某些主要的形式和形状,也可能是场景的构成和图像主题的选择——可能是所有这些的混合,甚至更多。
- 因此,通常不清楚图像内容和风格是否可以完全分离——如果可以,如何分离?例如,如果没有类似星星的图像结构,就不可能以梵高的《星夜》的风格来呈现图像。在本文的工作中,如果生成的图像“看起来”像样式图像,但显示了内容图像的对象和风景,则样式转换是成功的。但是,充分意识到,这一评估标准在数学上既不精确,也没有得到普遍认可。
- 然而,发现真正令人着迷的是,一个被训练来执行生物视觉核心计算任务之一的神经系统自动学习图像表示,这种表示允许——至少在某种程度上——图像内容与风格的分离。一种解释可能是,当学习对象识别时,网络必须变得对保持对象身份的所有图像变化不变。分解图像内容的变化和图像外观的变化的表示对于这项任务来说是非常实用的。
- 鉴于性能优化的人工神经网络和生物视觉之间惊人的相似性,因此很容易推测,人类从风格中提取内容的能力——以及我们创造和欣赏艺术的能力——也可能主要是人类视觉系统强大推理能力的卓越标志。
代码复现调试
##main文件 # coding: utf-8 import os os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" ##TF_CPP_MIN_LOG_LEVEL=0,输出所有信息,0也是默认值 ##TF_CPP_MIN_LOG_LEVEL=1,屏蔽通知信息 ##TF_CPP_MIN_LOG_LEVEL=2,只显示warning和error ##TF_CPP_MIN_LOG_LEVEL=3,只显示error import numpy as np ##数值计算库 import tensorflow.compat.v1 as tf tf.disable_v2_behavior() ##由于本机装的是Tensorflow2.0+,源程序是Tensorflow1.0版本,为了兼容相关操作进行的修改 import load_vgg #工程自编写的文件 import utils #工程自编写的工具文件 import ssl ssl._create_default_https_context = ssl._create_unverified_context #urllib.error.URLError:##取消SSL的证书验证。 def setup(): """ 新建存储模型的文件夹 checkpoints 和存储合成图片结果的文件夹 outputs """ utils.safe_mkdir("checkpoints") utils.safe_mkdir("outputs") class StyleTransfer(object): def __init__(self, content_img, style_img, img_width, img_height): """ 初始化 :param content_img: 待转换风格的图片(保留内容的图片) :param style_img: 风格图片(保留风格的图片) :param img_width: 图片的width :param img_height: 图片的height """ # 获取基本信息 self.content_name = str(content_img.split("/")[-1].split(".")[0]) # 获取内容图片的文件名,去掉图片文件的后缀 self.style_name = str(style_img.split("/")[-1].split(".")[0]) # 获取样式图片的文件名,去掉图片文件的后缀 self.img_width = img_width self.img_height = img_height # 规范化图片的像素尺寸 self.content_img = utils.get_resized_image(content_img, img_width, img_height) self.style_img = utils.get_resized_image(style_img, img_width, img_height) self.initial_img = utils.generate_noise_image(self.content_img, img_width, img_height) # 定义提取特征的层(与论文的内容呼应) self.content_layer = "conv4_2" self.style_layers = ["conv1_1", "conv2_1", "conv3_1", "conv4_1", "conv5_1"] ##匹配了层“conv4_2”上的内容表示和层conv1_1、conv2_1、conv3_1、conv4_1和conv5_1上的样式表示 # 定义content loss和style loss的权重,根据论文可自调整 self.content_w = 0.001 self.style_w = 1 ##可自调整测试实验效果 self.style_layer_w = [0.5, 1.0, 1.5, 3.0, 4.0] #不同style layers的权重,层数越深权重越大 # global step和学习率 self.gstep = tf.Variable(0, dtype=tf.int32, trainable=False, name="global_step") # global step self.lr = 2.0 utils.safe_mkdir("outputs/%s_%s" % (self.content_name, self.style_name)) def create_input(self): """ 初始化图片tensor """ with tf.variable_scope("input"): self.input_img = tf.get_variable("in_img", shape=([1, self.img_height, self.img_width, 3]), dtype=tf.float32, initializer=tf.zeros_initializer()) def load_vgg(self): """ 加载vgg模型并对图片进行预处理 """ self.vgg = load_vgg.VGG(self.input_img)#实例化load_vgg self.vgg.load()#调用其中的load方法 # mean-center,内容图片和风格图片去均值 self.content_img -= self.vgg.mean_pixels self.style_img -= self.vgg.mean_pixels def _content_loss(self, P, F): """ 计算content loss :param P: 内容图像的feature map :param F: 合成图片的feature map """ self.content_loss = tf.reduce_sum(tf.square(F - P)) / (4.0 * P.size) #reduce_sum() 是求和函数,为压缩求和,用于降维,乘数4与论文本身呼应 def _gram_matrix(self, F, N, M): """ 构造F的Gram Matrix(格雷姆矩阵),F为feature map,shape=(widths, heights, channels) :param F: feature map :param N: feature map的第三维度 :param M: feature map的第一维 乘 第二维 :return: F的Gram Matrix """ F = tf.reshape(F, (M, N)) return tf.matmul(tf.transpose(F), F) #将矩阵 a 乘以矩阵 b,生成a * b def _single_style_loss(self, a, g): """ 计算单层style loss :param a: 当前layer风格图片的feature map :param g: 当前layer生成图片的feature map :return: style loss """ N = a.shape[3] M = a.shape[1] * a.shape[2] # 生成feature map的Gram Matrix A = self._gram_matrix(a, N, M) G = self._gram_matrix(g, N, M) return tf.reduce_sum(tf.square(G - A)) / ((2 * N * M) ** 2) def _style_loss(self, A): """ 计算总的style loss :param A: 风格图片的所有feature map """ # 层数(我们用了conv1_1, conv2_1, conv3_1, conv4_1, conv5_1) n_layers = len(A) # 计算loss E = [self._single_style_loss(A[i], getattr(self.vgg, self.style_layers[i])) for i in range(n_layers)] # 加权求和 self.style_loss = sum(self.style_layer_w[i] * E[i] for i in range(n_layers)) def losses(self): """ 模型总体loss """ with tf.variable_scope("losses"): # contents loss with tf.Session() as sess: sess.run(self.input_img.assign(self.content_img)) #tensorflow的 构建视图、构建操作... 都只是在预定义一些操作/一些占位,并没有实际的在跑代码,一直要等到 session.run 才会 实际的去执行某些代码 gen_img_content = getattr(self.vgg, self.content_layer) content_img_content = sess.run(gen_img_content) self._content_loss(content_img_content, gen_img_content) # style loss with tf.Session() as sess: sess.run(self.input_img.assign(self.style_img)) style_layers = sess.run([getattr(self.vgg, layer) for layer in self.style_layers]) self._style_loss(style_layers) # 加权求得最终的loss self.total_loss = self.content_w * self.content_loss + self.style_w * self.style_loss def optimize(self): self.optimizer = tf.train.AdamOptimizer(self.lr).minimize(self.total_loss, global_step=self.gstep) #AdamOptimizer是TensorFlow中实现Adam算法的优化器。Adam即Adaptive Moment Estimation(自适应矩估计),是一个寻找全局最优点的优化算法,引入了二次梯度校正。 def create_summary(self): with tf.name_scope("summary"): tf.summary.scalar("contents loss", self.content_loss) #用来显示标量信息 tf.summary.scalar("style loss", self.style_loss) tf.summary.scalar("total loss", self.total_loss) self.summary_op = tf.summary.merge_all() def build(self): self.create_input() self.load_vgg() self.losses() self.optimize() self.create_summary() def train(self, epoches=300): skip_step = 1 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #初始化模型的参数。 writer = tf.summary.FileWriter("graphs/style_transfer", sess.graph) #用于在给定目录中创建事件文件并向其添加摘要和事件。该类异步更新文件内容。这允许训练程序调用方法,直接从训练循环将数据添加到文件中,而不会减慢训练速度。 sess.run(self.input_img.assign(self.initial_img)) saver = tf.train.Saver() ckpt = tf.train.get_checkpoint_state(os.path.dirname("checkpoints/%s_%s_style_transfer/checkpoint" % (self.content_name, self.style_name))) #通过checkpoint文件找到模型文件名。 #其中model_checkpoint_path保存了最新的tensorflow模型文件的文件名,all_model_checkpoint_paths则有未被删除的所有tensorflow模型文件的文件名。 if ckpt and ckpt.model_checkpoint_path: print("You have pre-trained model, if you do not want to use this, please delete the existing one.") saver.restore(sess, ckpt.model_checkpoint_path) #restore()只是保存了session中的相关变量对应的值,并不涉及模型的结构 #Restore则是将训练好的参数提取出来。Saver类训练完后,是以checkpoints文件形式保存。提取的时候也是从checkpoints文件中恢复变量。 initial_step = self.gstep.eval() for epoch in range(initial_step, epoches): # 前面几轮每隔10个epoch生成一张图片 if epoch >= 5 and epoch < 20: skip_step = 10 # 后面每隔20个epoch生成一张图片 elif epoch >= 20: skip_step = 20 sess.run(self.optimizer) if (epoch + 1) % skip_step == 0: gen_image, total_loss, summary = sess.run([self.input_img, self.total_loss, self.summary_op]) # 对生成的图片逆向mean-center,即在每个channel上加上mean gen_image = gen_image + self.vgg.mean_pixels writer.add_summary(summary, global_step=epoch) print("Step {}\n Sum: {:5.1f}".format(epoch + 1+" Loss: {:5.1f}".format(total_loss), np.sum(gen_image))) #print(" Loss: {:5.1f}".format(total_loss)) filename = "outputs/%s_%s/epoch_%d.png" % (self.content_name, self.style_name, epoch) utils.save_image(filename, gen_image) # 存储模型 if (epoch + 1) % 20 == 0: saver.save(sess, "checkpoints/%s_%s_style_transfer/style_transfer" % (self.content_name, self.style_name), epoch) if __name__ == "__main__": setup() # 指定图片 content_img = "contents/scenery.jpg" style_img = "styles/pattern.jpg" # 指定像素尺寸 img_width = 400 img_height = 300 # style transfer style_transfer = StyleTransfer(content_img, style_img, img_width, img_height) style_transfer.build() style_transfer.train(100)
- 下载vgg预训练模型,从零开始训练对算力和数据的要求相对比较高
""" This file is used to load pre-trained VGG model """ # coding: utf-8 import numpy as np import scipy.io #import tensorflow as tf import tensorflow.compat.v1 as tf tf.disable_v2_behavior() import utils # VGG-19 parameters file VGG_DOWNLOAD_LINK = "http://www.vlfeat.org/matconvnet/models/imagenet-vgg-verydeep-19.mat" VGG_FILENAME = "imagenet-vgg-verydeep-19.mat" EXPECTED_BYTES = 534904783 # 文件大小 #自设置模型的大小,通过查找网页中size参数获得 class VGG(object): def __init__(self, input_img): # 下载文件 utils.download(VGG_DOWNLOAD_LINK, VGG_FILENAME, EXPECTED_BYTES) # 加载文件 self.vgg_layers = scipy.io.loadmat(VGG_FILENAME)["layers"] #加载 MAT文件。mat 文件的名称(如果 appendmat==True,则不需要 .mat 扩展名)。也可以通过打开的file-like 对象。 self.input_img = input_img # VGG在处理图像时候会将图片进行mean-center,所以我们首先要计算RGB三个channel上的mean self.mean_pixels = np.array([123.68, 116.779, 103.939]).reshape((1, 1, 1, 3)) def _weights(self, layer_idx, expected_layer_name): """ 获取指定layer层的pre-trained权重 :param layer_idx: VGG中的layer id :param expected_layer_name: 当前layer命名 :return: pre-trained权重W和b """ W = self.vgg_layers[0][layer_idx][0][0][2][0][0] #从预训练模型中读取权重 b = self.vgg_layers[0][layer_idx][0][0][2][0][1] # 从预训练模型中读取偏置 layer_name = self.vgg_layers[0][layer_idx][0][0][0][0] # 从预训练模型中读取当前层的名称 assert layer_name == expected_layer_name, print("Layer name error!") #assert当表达式为真时,程序继续往下执行;当表达式为假时,抛出AssertionError错误,并将参数输出 return W, b.reshape(b.size) def conv2d_relu(self, prev_layer, layer_idx, layer_name): """ 采用relu作为激活函数的卷积层 :param prev_layer: 前一层网络 :param layer_idx: VGG中的layer id :param layer_name: 当前layer命名 """ with tf.variable_scope(layer_name): # 获取当前权重(numpy格式) W, b = self._weights(layer_idx, layer_name) # 将权重转化为tensor(由于我们不需要重新训练VGG的权重,因此初始化为常数)创建数值常量 W = tf.constant(W, name="weights") b = tf.constant(b, name="bias") # 卷积操作 conv2d = tf.nn.conv2d(input=prev_layer, filter=W, strides=[1, 1, 1, 1], padding="SAME") # 激活 out = tf.nn.relu(conv2d + b) setattr(self, layer_name, out) #用于设置属性值,该属性不一定是存在的。object -- 对象。name -- 字符串,对象属性。value -- 属性值。 def avgpool(self, prev_layer, layer_name): """ average pooling层(这里参考了原论文中提到了avg-pooling比max-pooling效果好,所以采用avg-pooling) :param prev_layer: 前一层网络(卷积层) :param layer_name: 当前layer命名 """ with tf.variable_scope(layer_name): # average pooling out = tf.nn.avg_pool(value=prev_layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") setattr(self, layer_name, out) #加载模型本身 def load(self): """ 加载pre-trained的数据 """ self.conv2d_relu(self.input_img, 0, "conv1_1") self.conv2d_relu(self.conv1_1, 2, "conv1_2") self.avgpool(self.conv1_2, "avgpool1") self.conv2d_relu(self.avgpool1, 5, "conv2_1") self.conv2d_relu(self.conv2_1, 7, "conv2_2") self.avgpool(self.conv2_2, "avgpool2") self.conv2d_relu(self.avgpool2, 10, "conv3_1") self.conv2d_relu(self.conv3_1, 12, "conv3_2") self.conv2d_relu(self.conv3_2, 14, "conv3_3") self.conv2d_relu(self.conv3_3, 16, "conv3_4") self.avgpool(self.conv3_4, "avgpool3") self.conv2d_relu(self.avgpool3, 19, "conv4_1") self.conv2d_relu(self.conv4_1, 21, "conv4_2") self.conv2d_relu(self.conv4_2, 23, "conv4_3") self.conv2d_relu(self.conv4_3, 25, "conv4_4") self.avgpool(self.conv4_4, "avgpool4") self.conv2d_relu(self.avgpool4, 28, "conv5_1") self.conv2d_relu(self.conv5_1, 30, "conv5_2") self.conv2d_relu(self.conv5_2, 32, "conv5_3") self.conv2d_relu(self.conv5_3, 34, "conv5_4") self.avgpool(self.conv5_4, "avgpool5")
- 在vgg模型需要使用一些网络文件爬取的准备,以及对数据进行预处理的操作
# coding: utf-8 import os from PIL import Image, ImageOps import numpy as np import scipy.misc import imageio from six.moves import urllib def download(download_link, file_name, expected_bytes): """ 下载pre-trained VGG-19 :param download_link: 下载链接 :param file_name: 文件名 :param expected_bytes: 文件大小 """ #检查VGG预训练模型是否下载完成,如果已经完成了下载,那么就不用再次下载, if os.path.exists(file_name): print("VGG-19 pre-trained model is ready") return print("Downloading the VGG pre-trained model. This might take a while ...") file_name, _ = urllib.request.urlretrieve(download_link, file_name) #urlretrieve自动的将求请地址得到的响应体保存到指定文件中 file_stat = os.stat(file_name) #os.stat() 方法用于在给定的路径上执行一个系统 stat 的调用。返回值的内容很丰富 if file_stat.st_size == expected_bytes: print('Successfully downloaded VGG-19 pre-trained model', file_name) else: raise Exception('File ' + file_name + ' might be corrupted. You should try downloading it with a browser.') #建议直接到load_vgg文件中的VGG_DOWNLOAD_LINK的网址下在,然后把预训练模型直接放在工程目录下 def get_resized_image(img_path, width, height, save=True): """ 对图片进行像素尺寸的规范化 :param img_path: 图像路径 :param width: 像素宽度 :param height: 像素高度 :param save: 存储路径 :return: """ image = Image.open(img_path) # PIL is column major so you have to swap the places of width and height image = ImageOps.fit(image, (width, height), Image.ANTIALIAS) #返回图像的大小和裁剪后的版本,裁剪为请求的宽高比和大小。method是用于重采样的方法。默认值为Image.NEAREST。 if save: image_dirs = img_path.split('/') image_dirs[-1] = 'resized_' + image_dirs[-1] out_path = '/'.join(image_dirs) if not os.path.exists(out_path): image.save(out_path) image = np.asarray(image, np.float32) return np.expand_dims(image, 0) def generate_noise_image(content_image, width, height, noise_ratio=0.6): """ 对原图片增加白噪声 :param content_image: 内容图片 :param width: 图片width :param height: 图片height :param noise_ratio: 噪声比例 :return: 带有噪声的内容图片 """ noise_image = np.random.uniform(-20, 20, (1, height, width, 3)).astype(np.float32) #这个方法就是生成一个随机数,这个随机数>=第一个参数,小于第二个参数 ,(1, height, width, 3)3通道 return noise_image * noise_ratio + content_image * (1 - noise_ratio) def save_image(path, image): image = image[0] image = np.clip(image, 0, 255).astype('uint8') #截取,超出的部分就把它强置为边界部分。 imageio.imsave(path, image) def safe_mkdir(path): """ Create a directory if there isn't one already. """ try: os.mkdir(path) except OSError: pass本文主要是对代码的一些调试和对与本机兼容的一些代码调整及部分的注释,整体逻辑框架来自朋友分享内容
- 内容图片
- 风格图片
- 第10轮训练结果
- 第100轮训练结果



