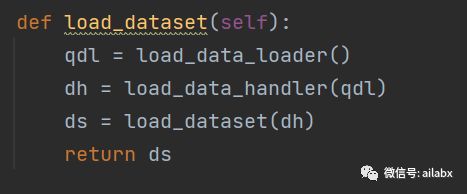
拆解qlib的dataset,使用代码方式加载数据集
"qlib ailabx量化投资平台" 建设第 16 篇。
这是100天小目标中的第16天。
今天的主题是手动特征工程,qlib的特征工程是基于表达式的,不像传统策略使用pandas的dataframe里的计算函数,或者Ta-lib来计算——传统方式适合因子数比较少,比如一个策略不会超过3-5个因子,而AI量化动辄上百个因子,如果一个个写那维护成本太高了(qlib自身就内置了两个handler, 一个158个因子,另一个360个因子)。
01 dataset数据集的加载方式拆解
config = {
"class": "DatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": {
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config,
},
"segments": {
"train": ("2008-01-01", "2014-12-31"),
"valid": ("2015-01-01", "2016-12-31"),
"test": ("2017-01-01", "2020-08-01"),
},
},
}
ds = init_instance_by_config(config)
官方的例子使用了大量的init_instance_by_config,我们可以跟进代码看看细节。
主要我们需要把handler变成我们自己的。
DatasetH(带Handler的Dataset)的初始化函数如下:
def __init__(
self, handler: Union[Dict, DataHandler], segments: Dict[Text, Tuple], fetch_kwargs: Dict = {}, **kwargs
):
参数handler, segments,fetch_kwargs以及**kwargs。
一般我们只管前两个参数:handler和segments。
我们可以把handler由dict变成DataHandler来加载:
def load_dataset(data_handler):
ds = DatasetH(data_handler, segments={"train": ('20180101', '20181231'), "valid": ('20190101', '20191231')})
return ds
02 Handler的加载方式
data_handler_config = {
"start_time": "2008-01-01",
"end_time": "2020-08-01",
"fit_start_time": "2008-01-01",
"fit_end_time": "2014-12-31",
"instruments": self.market,
}
{
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config,
}
在路径qlib.contrib.data.handler下的Alpha158类,参数kwargs是一个dict。
Alpha158继承自DataHandlerLP(带处理器的Handler的意思)
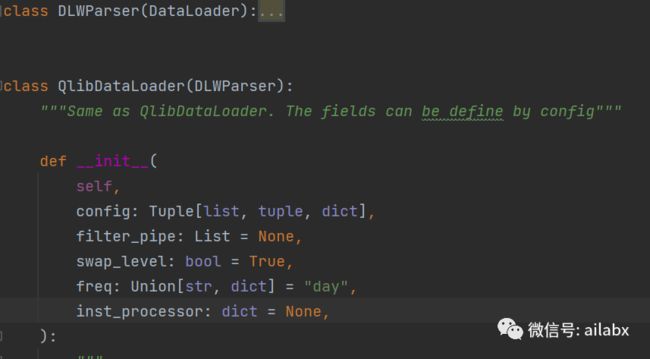
class Alpha158(DataHandlerLP):
def __init__(
self,
instruments="csi500",
start_time=None,
end_time=None,
freq="day",
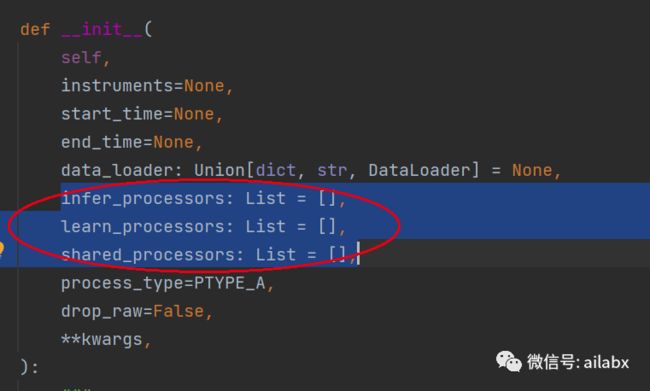
infer_processors=[],
learn_processors=_DEFAULT_LEARN_PROCESSORS,
fit_start_time=None,
fit_end_time=None,
process_type=DataHandlerLP.PTYPE_A,
filter_pipe=None,
inst_processor=None,
**kwargs,
):
在初始化的函数里,一是训练和推理的预处理器, 二是初始化了一个QlibDataLoader,传给
infer_processors = check_transform_proc(infer_processors, fit_start_time, fit_end_time)
learn_processors = check_transform_proc(learn_processors, fit_start_time, fit_end_time)
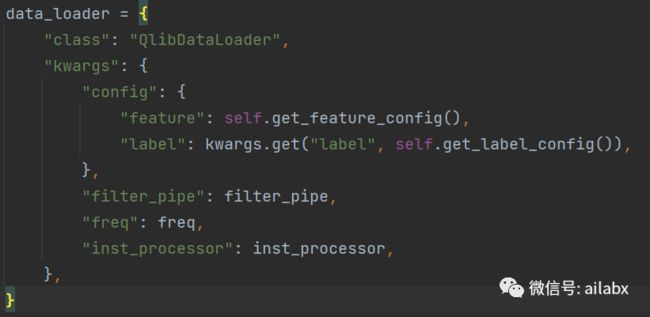
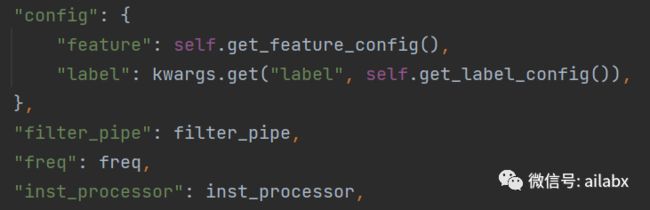
data_loader = {
"class": "QlibDataLoader",
"kwargs": {
"config": {
"feature": self.get_feature_config(),
"label": kwargs.get("label", self.get_label_config()),
},
"filter_pipe": filter_pipe,
"freq": freq,
"inst_processor": inst_processor,
},
}
super().__init__(
instruments=instruments,
start_time=start_time,
end_time=end_time,
data_loader=data_loader,
infer_processors=infer_processors,
learn_processors=learn_processors,
process_type=process_type,
)
我们简化为直接调用基类是可以的:

这段是初始化data_loader的参数:
03 QlibDataLoader的初始化
外部传入的参数如下:
04 总体代码:
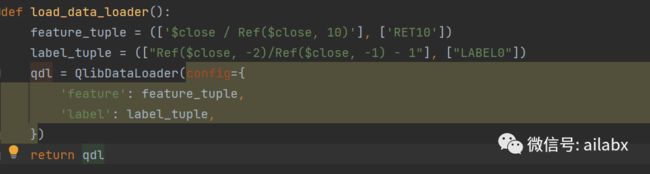
加载dataset数据集是分层独立的,
dataloader加载数据,并负责特征与标注。
datahandler加上了预处理,比如数据标准化,填充不存在的值之类的。dataset用于数据集划分,比如训练集,测试集,回测集等。
05 预处理器
顾名思义,infer=推理, learn=训练。都是处理器,但使用的阶段不同而已。
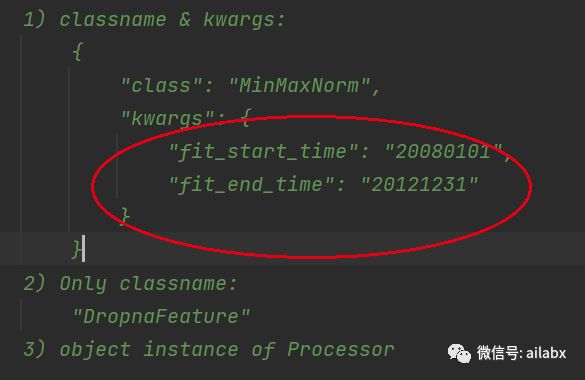
MinMax正则,这是机器学习里常用的数据预处理,简单理解就是数据“归一化”,(X-Xmin) /(Xmax -Xmin),这里就与量纲无关了。
两上小问题:
为何训练阶段与测试阶段使用的处理器不同?
在官方示例里的alpha158里,默认的处理器如下:

为何正则化需要fit_start_time给定日期范围?
小结:
今天我们主要关注的是dataset如何构建,在官方完全一个config配置之余,通过代码去看背后具体发生了什么,以及这些参数的意义。
在一开始学习及后续使用,不建议用alpha158或者alpha360。
初学用这个计算量太大,太慢;
后续实战重点就是建立自己的alpha因子。
这两者作为一个benchmark是可以的。
明天要使用bigquant里的特征来建立策略。