经典论文阅读(9)——XLNET

由于具有双向上下文建模的能力,BERT等基于自编码的预训练方法比基于自回归语言建模的预训练方法具有更好的性能然而。但由于依赖于用mask破坏输入,BERT忽略了mask位置之间的依赖关系,并遭受了训练前微调的差异。本文提出了一种广义的自回归预训练方法XLNet,该方法(1)通过最大化所有分解顺序排列的期望似然来实现双向上下文学习,(2)由于其自回归公式,克服了BERT的局限性。此外,XLNet集成了Transformer-XL的思想,这是最先进的自回归模型。
AR自回归语言模型寻求用自回归模型估计文本语料库的概率分布,具体的,给定一个文本序列![]() ,自回归模型将可能性分解为正向的
,自回归模型将可能性分解为正向的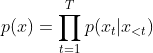 或反向的
或反向的 。由于AR语言模型只被训练成对单向上下文进行编码,它无法对深层上下文建模,而下游的语言理解任务往往需要双向的上下文信息,这导致了AR模型和有效的预训练之间的差距。
。由于AR语言模型只被训练成对单向上下文进行编码,它无法对深层上下文建模,而下游的语言理解任务往往需要双向的上下文信息,这导致了AR模型和有效的预训练之间的差距。
AE自编码模型是从损坏的输入数据中重建原始数据。给定输入的标记序列,特定部分的标记被一个特殊的符号[MASK]代替,然后训练模型从被破坏的数据中恢复原始token。这消除了前面提到的AR语言建模中的双向信息差距,从而提高了性能。然而,BERT在预训练时使用的[MASK]等人工符号在微调时的真实数据中是缺失的,导致了预训练和微调时的差异。此外,BERT假设预测的标记与未被隐藏的标记是相互独立的。
本文提出了XLNet,它是一种广义的自回归方法,利用增强现实语言建模和AE的优点,同时避免它们的局限性。
-
与传统AR模型中使用固定的正向或向后分解顺序不同,XLNet将序列的期望对数似然最大化。
-
其次,作为一种通用的AR语言模型,XLNet不依赖于数据损坏。因此XLNet没有BERT预训练和微调间的差异。
-
受AR语言建模的最新进展的启发,XLNet将片段递归机制和Transformer-XL的相对编码方案集成到预训练中,这从经验上提高了性能,特别是涉及较长的文本序列的任务。
-
重新参数化Transformer(-XL)网络。
提出的方法
背景
给定一个文本序列![]() ,AR语言模型通过前向自回归分解下的最大似然来进行预训练:
,AR语言模型通过前向自回归分解下的最大似然来进行预训练:

其中![]() 是由神经模型(如RNN、Trasformer等)产生的上下文表示,e(x)为x的embedding表示。相比而言,BERT是去躁自编码的。具体来说,对于一个文本序列x, BERT首先通过随机设置x中的一部分符号(例如15%)为一个特殊符号[MASK]来构造一个已损坏的版本
是由神经模型(如RNN、Trasformer等)产生的上下文表示,e(x)为x的embedding表示。相比而言,BERT是去躁自编码的。具体来说,对于一个文本序列x, BERT首先通过随机设置x中的一部分符号(例如15%)为一个特殊符号[MASK]来构造一个已损坏的版本 。将被屏蔽的符号设为
。将被屏蔽的符号设为 。训练目标是从恢复:
。训练目标是从恢复:
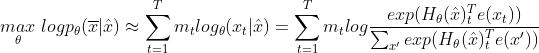
其中![]() 表示
表示 被屏蔽,而
被屏蔽,而![]() 是一个将长度为T的文本序列x映射为一个。从以下几个方面可以比较这两种方法的优劣:
是一个将长度为T的文本序列x映射为一个。从以下几个方面可以比较这两种方法的优劣:
-
独立性假设:BERT在联合条件概率
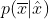 分解时基于独立假设,即所有被屏蔽的符号都分别被重建。作为对比,AR语言模型在分解
分解时基于独立假设,即所有被屏蔽的符号都分别被重建。作为对比,AR语言模型在分解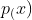 时使用乘积法则,没有这样的独立性假设。
时使用乘积法则,没有这样的独立性假设。 -
输入噪声:BERT的输入包含了像[MASK]这样的人工符号,这些符号在下游任务中从未出现过,这就造成了预训练和微调的差异。将[MASK]替换为原始符号并不能解决问题,因为原始符号仅以很小的概率被使用,因此上述公式的优化非常小。相比之下,AR语言建模不依赖任何输入损坏,也没有这个问题。
-
上下文依赖:AR表征
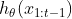 仅依赖于位置t之前的token,但BERT表征
仅依赖于位置t之前的token,但BERT表征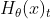 能够捕获双向上下文。
能够捕获双向上下文。
目标:排列语言建模
我们提出了排列语言建模目标,该目标不仅保留了AR模型的优点,而且允许模型捕获双向上下文。具体来说,对于长度为T的序列x,有T!不同的顺序来执行有效的自回归分解。
令![]() 表示T长度的index序列[1,...,T]的所有排列可能,用
表示T长度的index序列[1,...,T]的所有排列可能,用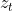 和
和![]() 表示第t个元素和一个排列z的前t-1个元素。我们提出的排列语言建模目标可以表示为:
表示第t个元素和一个排列z的前t-1个元素。我们提出的排列语言建模目标可以表示为:
![\underset{\theta}{max}~E_{z}[\sum_{t=1}^Tlog~p_{\theta}(x_{z_t}|x_{z_{<t}})]](http://img.e-com-net.com/image/info8/f128cc88c32249599348c4cd0f1445df.gif)
对于一个文字序列x,我们每次采样一个z并将似然 按分解顺序分解。由于模型参数
按分解顺序分解。由于模型参数 在训练过程中在所有分解顺序中被共享,
在训练过程中在所有分解顺序中被共享,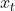 可以看到每个序列中可能的元素
可以看到每个序列中可能的元素![]() ,因此能够捕获双向上下文。由于这个目标符合AR结构,它自然地避免了独立性假设和预训练-微调的差异。
,因此能够捕获双向上下文。由于这个目标符合AR结构,它自然地避免了独立性假设和预训练-微调的差异。
所提出的目标只排列因子分解顺序,而不排列序列顺序。也就是说,我们保持原序列顺序,使用原序列对应的位置编码,并在transformer中通过适当的注意掩模实现分解顺序的排列。
框架:目标感知表示的两流自注意

虽然置换语言建模目标具有期望的属性,经典的Transformer参数化可能不起作用。假设我们用Softmax参数化下一个token的分布![]() ,即,
,即,![]() ,其中
,其中![]() 表示由共享Transformer在合适的屏蔽之后产生的
表示由共享Transformer在合适的屏蔽之后产生的![]() 的隐藏表征。表征
的隐藏表征。表征![]() 不取决于它的位置,即
不取决于它的位置,即![]() 的值。因此,无论目标位置如何,预测的分布都是相同的,这就无法学习有用的表征。为了避免这个问题,我们建议重新参数化下一个token分布,使其能够感知目标位置,其中
的值。因此,无论目标位置如何,预测的分布都是相同的,这就无法学习有用的表征。为了避免这个问题,我们建议重新参数化下一个token分布,使其能够感知目标位置,其中![]() 表示一种新的表征,:
表示一种新的表征,:
![]()
-
两流自注意力:我们提出“站在”目标位置
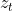 依赖于位置以通过注意力从上下文
依赖于位置以通过注意力从上下文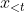 中聚集信息。要使这个参数化起作用,在Transformer架构中有两个矛盾的需求:(1)为了预测token
中聚集信息。要使这个参数化起作用,在Transformer架构中有两个矛盾的需求:(1)为了预测token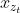 ,
,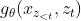 需要仅使用位置而不是内容
需要仅使用位置而不是内容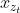 ,否则目标会变得微不足道;(2)为了预测其他token
,否则目标会变得微不足道;(2)为了预测其他token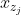 ,有j>t,
,有j>t,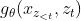 还需要将内容进行编码以提供完整的上下文信息。为了解决该矛盾,我们提出两组而不是一组隐藏表征:
还需要将内容进行编码以提供完整的上下文信息。为了解决该矛盾,我们提出两组而不是一组隐藏表征:-
内容表征
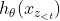 ,或简写为
,或简写为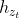 ,其作用类似于Transformer中的标准隐藏状态。该表征将上下文和自身均进行编码。
,其作用类似于Transformer中的标准隐藏状态。该表征将上下文和自身均进行编码。 -
查询表征
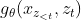 ,或简写为
,或简写为 ,仅包含上下文信息x_{z_{
,仅包含上下文信息x_{z_{
-
第一层查询流被初始化为可训练的向量,![]() ,内容流设置为相应的单词嵌入,
,内容流设置为相应的单词嵌入,![]() 。对每个自注意力层,有:
。对每个自注意力层,有:
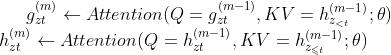
更新规则与标准的自注意力机制完全相同,因此在精调时,我们可以简单得将查询流去掉,并将内容流作为一个简单的Transformer-XL。最后,我们用最后一层查询表征![]() 计算上面的公式。
计算上面的公式。
局部预测
虽然排列语言建模目标有几个优点,但由于排列,它是一个更具挑战性的优化问题,并且在初步实验中收敛缓慢。为了降低优化难度,我们选择只按照分解顺序预测最后一个token。我们将z分割为非目标子序列![]() 以及目标子序列z>c,c是一个分割点。目标是最大化非目标子序列条件下的目标子序列的对数似然,即:
以及目标子序列z>c,c是一个分割点。目标是最大化非目标子序列条件下的目标子序列的对数似然,即:
![\underset{\theta}{max}~E_{z \sim Z_T}[log~p_{\theta}(x_{z>c}|x_{z \leqslant c})]=E_{z \sim Z_T}[\sum_{t=c+1}^{|z|}log~p_{\theta}(x_{z_t}|x_{z_{<t}})]](http://img.e-com-net.com/image/info8/e330bbeaafd34341b4389560970ed178.gif)
注意到、![]() 被选择作为目标,因为在给定当前分解阶z的情况下,它拥有序列中最长的上下文。另外使用超参数K,从而选择约1/K的token进行预测。
被选择作为目标,因为在给定当前分解阶z的情况下,它拥有序列中最长的上下文。另外使用超参数K,从而选择约1/K的token进行预测。
整合Transformer-XL的理念
由于我们的目标函数符合AR框架,我们将最先进的AR语言模型,Transformer-XL,加入到我们的预训练框架中。我们整合了Transformer-XL中两个重要的技术,即相对位置编码方案和段递推机制。
假设我们从一个长序列s中取出两个片段,即,令![]() 和z分别为[1,...,T]和[T+1,...,2T]的排列。接着,基于排列
和z分别为[1,...,T]和[T+1,...,2T]的排列。接着,基于排列![]() ,我们处理第一个片段,接着将获得的层m的内容表征
,我们处理第一个片段,接着将获得的层m的内容表征![]() 进行缓存,然后对于下一段x,使用内存的注意里更新为
进行缓存,然后对于下一段x,使用内存的注意里更新为
![]()
位置编码只依赖于原始序列中的实际位置,因此,一旦获得表征![]() ,上面的注意力更新与
,上面的注意力更新与![]() 独立。这允许缓存和重用内存,而不需要知道前一段的分解顺序。查询流可以以同样的方式计算。
独立。这允许缓存和重用内存,而不需要知道前一段的分解顺序。查询流可以以同样的方式计算。
多段建模
在预训练截断,跟随BERT,我们随机采样两个片段(无论是来自相同的上下文还是不来自相同的上下文),并将两个片段的拼接作为一个序列来进行置换语言建模。我们只重用属于同一上下文的内存。具体来说,我们的模型的输入与BERT相同:[CLS, A, SEP, B, SEP]。我们遵循两段数据格式,XLNet-Large没有使用下一句预测的目标,因为它在我们的消融研究中没有显示出持续的改善。
相对段落编码:在结构上,不同于BERT在每个位置的词嵌入上添加一个绝对段嵌入,我们将Transformer-XL中相对编码的思想进行延伸,也可以对片段进行编码。给定序列中的位置i和j,如果i和j来自同一段,我们使用段编码![]() ,否则
,否则![]() ,
,![]() 和
和![]() 是每个注意力头的可学习参数。换句话说,我们只考虑这两个位置是否在同一段中,而不考虑它们来自哪个特定段。这与相对编码的核心思想是一致的,即只对位置之间的关系进行建模。段落编码
是每个注意力头的可学习参数。换句话说,我们只考虑这两个位置是否在同一段中,而不考虑它们来自哪个特定段。这与相对编码的核心思想是一致的,即只对位置之间的关系进行建模。段落编码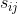 用来计算注意力权重
用来计算注意力权重![]() ,其中q_i为查询向量,b为一个可学习的头部偏倚向量。最后,
,其中q_i为查询向量,b为一个可学习的头部偏倚向量。最后, 被添加到注意力分数。使用相对段落编码的好处有:首先,相对编码的归纳偏差提高了泛化能力;其次,它提供了对具有两个以上输入段的任务进行微调的可能性,而使用绝对段编码是不可能做到这一点的。
被添加到注意力分数。使用相对段落编码的好处有:首先,相对编码的归纳偏差提高了泛化能力;其次,它提供了对具有两个以上输入段的任务进行微调的可能性,而使用绝对段编码是不可能做到这一点的。
讨论
我们观察到BERT和XLNet都执行局部预测,即只预测序列中标记的一个子集。这对于BERT来说是一个必要的选择,因为如果所有的token都被屏蔽,那么就不可能做出任何有意义的预测。此外,对于BERT和XLNet,局部预测通过仅足够的上下文预测token来降低优化难度。然而,独立性假设禁止BERT对目标之间的依赖关系进行建模。以[New, York, is, a, city]为例,假设BERT和XLNet都选择两个token[New, York]作为预测目标,并以最大化![]() 。有:
。有:
![]()
XLNet能够捕获这对(New, York)之间的依赖关系,而BERT忽略了这一点。XLNet总是在给定相同目标的情况下学习更多的依赖项对,并包含“更密集”的有效训练信号。
实验
使用的数据集有BooksCorpus和英文维基用于预训练数据,使用512的全序列长度。经过比较排列语言建模目标、Transformer-XL等,发现Transformer-XL和排列LM都明显为XLNet贡献了优于BERT的性能。