吴恩达机器学习逻辑回归章节作业二:利用正则化逻辑回归模型预测来自制造工厂的微芯片是否通过质量保证(python实现)
吴恩达机器学习作业二:利用正则化逻辑回归模型预测来自制造工厂的微芯片是否通过质量保证(python实现)
该文是针对吴恩达机器学习逻辑回归章节作业任务二,利用正则化逻辑回归模型预测来自制造工厂的微芯片是否通过质量保证,区别于任务一中利用逻辑回归模型预测一个学生是否被学校录取见博客:传送门
该模型将对特征进行映射,将二维特征向量隐射为28维,但为了避免模型过拟合问题,需要进行正则化处理。
文章目录
-
- 吴恩达机器学习作业二:利用正则化逻辑回归模型预测来自制造工厂的微芯片是否通过质量保证(python实现)
-
- 任务
-
- 读取数据
- 绘制数据,看下数据分布情况
- 特征映射
- 数据预处理
- Sigmod函数
- 代价函数(Cost function) 正则化处理
- 梯度函数
- 寻找最优化参数(scipy.opt.fmin_tnc()函数)
- 模型评估(准确率计算)
- 全部代码
- 训练数据链接
任务
In this part of the exercise, you will implement regularized logistic regression
to predict whether microchips from a fabrication plant passes quality assur-
ance (QA). During QA, each microchip goes through various tests to ensure
it is functioning correctly.
Suppose you are the product manager of the factory and you have the
test results for some microchips on two different tests. From these two tests,
you would like to determine whether the microchips should be accepted or
rejected. To help you make the decision, you have a dataset of test results
on past microchips, from which you can build a logistic regression model.
利用正则化逻辑回归,以预测来自制造工厂的微芯片是否通过质量保证(QA)。在QA期间,每个微芯片都要经过各种测试,以确保其正常运行。
假设您是工厂的产品经理,您有一些微芯片的两个不同测试的测试结果。从这两项测试中,您想确定微芯片是应该被接受还是被拒绝。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
读取数据
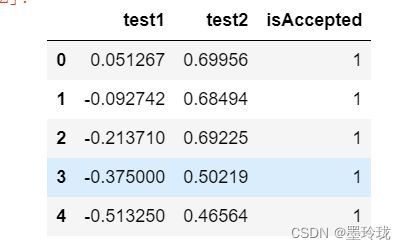
#读取数据
data=pd.read_csv("../code/ex2-logistic regression/ex2data2.txt",delimiter=',',header=None,names=['test1','test2','isAccepted'])
print(data)
data.head()
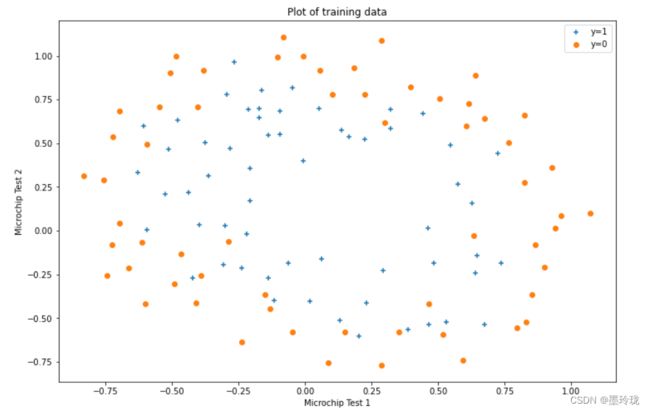
绘制数据,看下数据分布情况
#数据可视化
acceptedData=data[data['isAccepted'].isin([1])]
rejectedData=data[data['isAccepted'].isin([0])]
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(acceptedData['test1'],acceptedData['test2'],marker='+',label='y=1')
ax.scatter(rejectedData['test1'],rejectedData['test2'],marker='o',label="y=0")
ax.legend(loc=1)
ax.set_xlabel('Microchip Test 1')
ax.set_ylabel('Microchip Test 2')
ax.set_title("Plot of training data")
plt.show()
特征映射
观察上面数据分布情况,发现用线性决策边界难以将数据分开,此时需要一种更好的方法,一种更好地拟合数据的方法是从每个数据点创建更多的特征。
将特征映射到所有x1(test1), x2(test2)的六次方的多项式项。
经过下面代码映射后我们的两个特征向量(两个QA测试的分数)被转换为一个28维向量。
在这个高维特征向量上训练的logistic回归分类器将具有更复杂的决策边界,在我们的二维图中绘制时将显示为非线性。
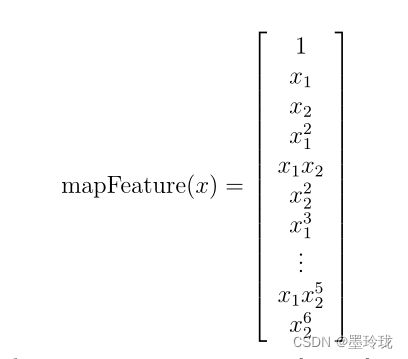
其中Fab 代表x1a x2b
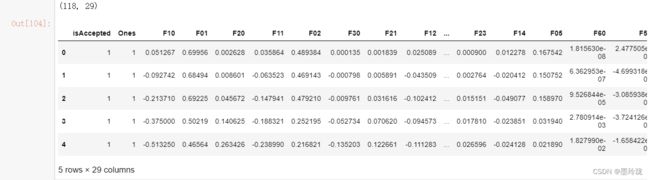
degree = 6
x1 = data['test1']
x2 = data['test2']
data.insert(3, 'Ones', 1)
for i in range(1, degree+1):
for j in range(0, i+1):
data['F' + str(i-j) + str(j)] = np.power(x1, i-j) * np.power(x2, j)
data.drop('test1', axis=1, inplace=True)
data.drop('test2', axis=1, inplace=True)
print(data.shape)
data.head()
数据预处理
loc=data.shape[1]
X=np.array(data.iloc[:,1:loc])
Y=np.array(data.iloc[:,0:1])
theta=np.zeros(X.shape[1])
learningRate=1
X.shape,Y.shape,theta.shape
值得注意的是此处theta初始化值为0,并且使用的是一维数组,这是因为在后面求解最优化theta值时采用的scipy.opt.fmin_tnc()函数传入的参数theta必须是一维数组
Sigmod函数
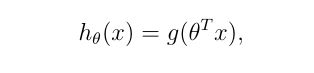
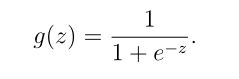
def sigmoid(z):
return 1/(1+np.exp(-z))
代价函数(Cost function) 正则化处理
虽然特征映射允许我们构建一个更有表现力的分类器,但它也更容易发生过拟合。
因此需要通过正则化逻辑回归来拟合数据。
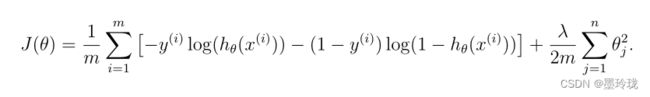
def computeCostReg(theta,X,Y,learningRate):
reg=(learningRate/(2*len(X)))*np.inner(theta,theta)
theta = np.matrix(theta)
h=sigmoid(np.dot(X,(theta.T)))
a=np.multiply(-Y,np.log(h))
b=np.multiply((1-Y),np.log(1-h))
return np.sum(a-b)/len(X)+reg
computeCost(theta,X,Y,learningRate)
0.6931471805599454
梯度函数
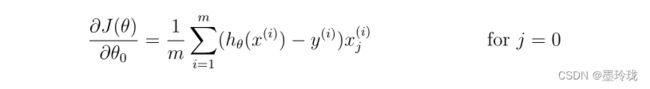
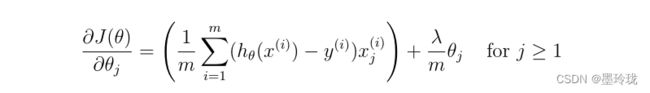
def gradientReg(theta,X,Y,learningRate):
theta = np.matrix(theta)
h=sigmoid(np.dot(X,(theta.T)))
grad=np.dot(((h-Y).T),X)/len(X)
reg=(learningRate/len(X))*theta
reg[:,0]=0 #因为j=0时,不要加(learningRate/m)*θ
temp=reg+grad
return np.array(grad).flatten() #因为下面寻找最优化参数的函数(opt.fmin_tnc())要求传入的gradient函返回值需要是一维数组,因此需要利用flatten()将grad进行转换以下
gradientReg(theta,X,Y,learningRate) #测试一下,当theta值都为为0时,计算一下此时的梯度为多少
array([8.47457627e-03, 1.87880932e-02, 7.77711864e-05, 5.03446395e-02,
1.15013308e-02, 3.76648474e-02, 1.83559872e-02, 7.32393391e-03,
8.19244468e-03, 2.34764889e-02, 3.93486234e-02, 2.23923907e-03,
1.28600503e-02, 3.09593720e-03, 3.93028171e-02, 1.99707467e-02,
4.32983232e-03, 3.38643902e-03, 5.83822078e-03, 4.47629067e-03,
3.10079849e-02, 3.10312442e-02, 1.09740238e-03, 6.31570797e-03,
4.08503006e-04, 7.26504316e-03, 1.37646175e-03, 3.87936363e-02])
寻找最优化参数(scipy.opt.fmin_tnc()函数)
在实现线性回归时,是利用梯度下降的方式来寻找最优参数。
在此处使用scipy.optimize包下的fmin_tnc函数来求解最优参数,该函数利用截断牛顿算法中的梯度信息,最小化具有受边界约束的变量的函数。
import scipy.optimize as opt
result = opt.fmin_tnc(func=computeCostReg, x0=theta, fprime=gradientReg, args=(X, Y,learningRate))
print(result)
theta=result[0]
(array([ 1.60695173, 1.1560198 , 1.96230334, -3.05065126, -1.6570303 ,
-1.91905334, 0.57020797, -0.68153401, -0.71446893, 0.04581306,
-2.05403844, -0.19543688, -1.06002902, -0.50146861, -1.49394725,
0.08870358, -0.37553852, -0.16212869, -0.476704 , -0.4992825 ,
-0.25753319, -1.25322502, 0.0080483 , -0.51945933, -0.03978317,
-0.54273817, -0.21843762, -0.93051019]), 86, 4)
scipy.opt.fmin_tnc()函数
函数常用参数值解释:
func:优化的目标函数 (在这里要优化的是代价函数)
x0:初始值,必须是一维数组 (在这里传的是一维的theta)
fprime:提供优化函数func的梯度函数,不然优化函数func必须返回函数值和梯度,或者设置approx_grad=True (在这里梯度函数是gradient函数,并且要求返回的是一维数组)
args:元组,是传递给优化函数的参数
函数返回值解释:
x : 数组,返回的优化问题目标值 (在这里即优化后,theta的最终取值)
nfeval:整数,功能评估的数量。在进行优化的时候,每当目标优化函数被调用一次,就算一个function evaluation。在一次迭代过程中会有多次function evaluation。这个参数不等同于迭代次数,而往往大于迭代次数。
rc: int,返回码
模型评估(准确率计算)
在求得最优theta值后,利用得到的模型在训练数据中进行预测,并求准确率。
由逻辑回归的假设模型可知:
当hθ(x)>=0.5时,预测y=1;
当hθ(x)<0.5时,预测y=0;
predict函数:通过训练数据以及theta值进行预测,并且把预测结果使用列表返回;
hypothesis=[1 if a==b else 0 for (a,b)in zip(predictValues,Y)] 目的是将预测值与实际值进行比较,如果二者相等,则为1,否则为0;
accuracy=hypothesis.count(1)/len(hypothesis) 计算hypothesis中1的个数然后除以总的长度,得到准确率
def predict(theta, X):
theta = np.matrix(theta)
temp = sigmoid(X * theta.T)
#print(temp)
return [1 if x >= 0.5 else 0 for x in temp]
predictValues=predict(theta,X)
hypothesis=[1 if a==b else 0 for (a,b)in zip(predictValues,Y)]
accuracy=hypothesis.count(1)/len(hypothesis)
print ('accuracy = {0}%'.format(accuracy*100))
accuracy = 84.7457627118644%
全部代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
#sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#代价函数
def computeCostReg(theta,X,Y,learningRate):
reg=(learningRate/(2*len(X)))*np.inner(theta,theta)
theta = np.matrix(theta)
h=sigmoid(np.dot(X,(theta.T)))
a=np.multiply(-Y,np.log(h))
b=np.multiply((1-Y),np.log(1-h))
return np.sum(a-b)/len(X)+reg
#梯度函数
def gradientReg(theta,X,Y,learningRate):
theta = np.matrix(theta)
h=sigmoid(np.dot(X,(theta.T)))
grad=np.dot(((h-Y).T),X)/len(X)
reg=(learningRate/len(X))*theta
reg[:,0]=0 #因为j=0时,不要加(learningRate/m)*θ
temp=reg+grad
return np.array(grad).flatten() #因为下面寻找最优化参数的函数(opt.fmin_tnc())要求传入的gradient函返回值需要是一维数组,因此需要利用flatten()将grad进行转换以下
#模型预测
def predict(theta, X):
theta = np.matrix(theta)
temp = sigmoid(X * theta.T)
#print(temp)
return [1 if x >= 0.5 else 0 for x in temp]
#读取数据
data=pd.read_csv("../code/ex2-logistic regression/ex2data2.txt",delimiter=',',header=None,names=['test1','test2','isAccepted'])
#数据可视化,看一下数据分布情况
#数据可视化
acceptedData=data[data['isAccepted'].isin([1])]
rejectedData=data[data['isAccepted'].isin([0])]
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(acceptedData['test1'],acceptedData['test2'],marker='+',label='y=1')
ax.scatter(rejectedData['test1'],rejectedData['test2'],marker='o',label="y=0")
ax.legend(loc=1)
ax.set_xlabel('Microchip Test 1')
ax.set_ylabel('Microchip Test 2')
ax.set_title("Plot of training data")
plt.show()
degree = 6
x1 = data['test1']
x2 = data['test2']
#特征映射
data.insert(3, 'Ones', 1)
for i in range(1, degree+1):
for j in range(0, i+1):
data['F' + str(i-j) + str(j)] = np.power(x1, i-j) * np.power(x2, j)
data.drop('test1', axis=1, inplace=True)
data.drop('test2', axis=1, inplace=True)
#数据预处理
loc=data.shape[1]
X=np.array(data.iloc[:,1:loc])
Y=np.array(data.iloc[:,0:1])
theta=np.zeros(X.shape[1])
learningRate=1
X.shape,Y.shape,theta.shape
#寻找最优化参数theta
result = opt.fmin_tnc(func=computeCostReg, x0=theta, fprime=gradientReg, args=(X, Y,learningRate))
theta=result[0]
#模型评估(准确率计算)
predictValues=predict(theta,X)
hypothesis=[1 if a==b else 0 for (a,b)in zip(predictValues,Y)]
accuracy=hypothesis.count(1)/len(hypothesis)
print ('accuracy = {0}%'.format(accuracy*100))
训练数据链接
链接:https://pan.baidu.com/s/1kwQjf8cEa7b8H7EpARszjg
提取码:dghs