Prompt-Tuning的鼻祖--PET
PET(Pattern-Exploiting Training)出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021),是一种半监督的训练方法。

目标
由于大量的language、domain和task以及人工标注数据的成本,在NLP的实际使用中,通常只有少量带标签的示例,所以few-shot是值得研究的部分;如果依然使用传统的监督学习方法,容易过拟合,效果会非常差,因为当仅有很少的样本时,仅有的文本无法让模型知道要具体如何进行分类
在本文中,作者提出了Pattern-Exploiting Training(PET),一种半监督的训练方法,将一句完整的输入样本构造成完形填空的语句后再进行输入预处理模型。
先前的预训练模型
BERT的预训练其中一个任务是MLM,就是去预测被【MASK】掉的token,采用的是拿bert的最后一个encoder(base版本,就是第12层的encoder的输出,也即下图左图蓝色框)作为输入,然后接全连接层,做一个全词表的softmax分类(这部分就是左图的红色框)。但在fine tuning的时候,我们是把MLM任务的全连接层抛弃掉,在最后一层encoder后接新的初始化层来做具体的下游任务。
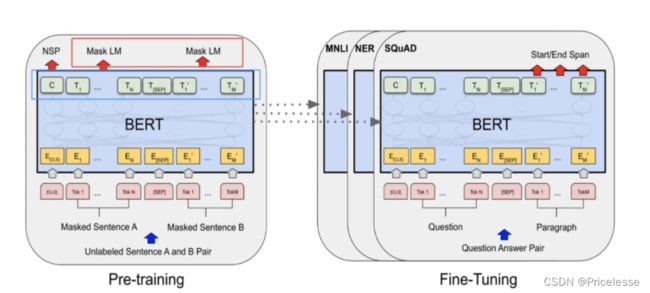
能不能通过某些巧妙的设计,把MLM层学习到的参数也利用上?
举例:
输入一条汽车论坛的评论,输出这个评论是属于【积极】or【消极】每个类别如果只有10个labeled数据,1K条unlabeled数据。
现在通过改造输入,如下图,

model对下划线__部分进行预测。BERT预训练时MLM任务是预测整个词表,而这里把词表限定在{好,差},cross entropy交叉熵损失训练模型。预测时,假如预测出好,即这个样例预测label就为积极,预测为差,这个样例就是消极。
「BERT预训练时的MLM层的参数能利用上」。而且「即使model没有进行fine tunning,这个model其实就会含有一定的准确率
参数说明
Pattern-Verbalizer-Pair
定义函数P(pattern):输入x,输出包含掩码标记的句子或短语,使得输出可以被看作是一个完形填空问题。可以理解为“模板构造”。输入x=“Best pizza ever!” P(x)="Best pizza ever! It was___.” P ( X )表示将 X 转化为带有[MASK]的phrase
映射V(verbalizer):将PLM预测标签映射为词表中的一个单词。比如预测结果为负向标签0,将0映射为单词“bad”,可以理解为“答案映射”的逆过程。
M 表示一个预训练语言模型
词汇表记做 V
[MASK](原文作者用下划线表示)_
L表示目标任务 A的所有标签集合
T表示标签数据集
D表示无标签数据集(往往比T大很多)
任务 A 的输入记做 X = ( s 1 , s 2 , . . . , s k ) 。其中 s i 表示一个句子。如果 k = 2,则输入的 X 是两个句子
PET的训练与推理
定义一个 M ( w ∣ Z ) 表示给定带有一个[MASK]标记的序列 Z,语言模型可以在该[MASK]位置填入词 w ∈ L 的得分,其次通过softmax操作定义概率分布:
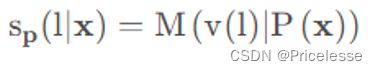

通过计算真实标签和q之间的cross-entropy得到损失。将整个训练集的损失总和即为该PVP在模型M上的损失。
Auxilliary Language Modeling
作者在这里引入无标签数据一起来训练MLM模型
这里的[MASK]可以采用BERT的方法,随机对句子的15%token进行【MASK】。

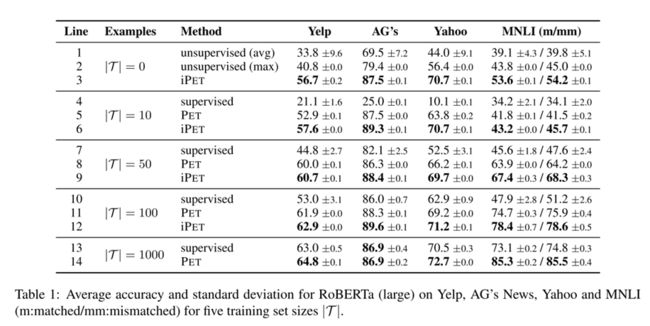
作者发现,由于这是在非常少的样本集合 T 上进行训练,可能会导致灾难性遗忘,因此作者引入预训练模型的loss作为辅助损失(Auxiliary MLM loss),两个损失通过加权方式结合。
作者根据先前的工作,取了一个经验值 α = 1 0 − 4 。
评价PVP定义的性能

作者采用的方法是知识蒸馏。选取20个labeled数据训练4个PVP模型,然后拿这四个PVP模型对1K条unlabeled数据进行预测,预测的结果用下式进行平均。

Uniform:所有PVP权重为1
Weighted:PVP权重设置为label数据集训练上的准确率
经过这样处理后,噪声减少了,利用多个PVP平均的思想把某些本来单个PVP预测偏差比较大的进行平均后修正。
总结流程

•第一步:先定义PVPs,然后对每个PVP用labeled数据通过M进行单独的训练,该步可以加入上面提到的Auxiliary Language Modeling一起训练;
•第二步:用训练好的PVPs,对unlabled数据进行预测,并知识蒸馏,得到大量的soft label;
•第三步:用第二步得到的带有soft label的data,用传统的fine tuning方法训练model。
从20条labeled数据扩充到1K条有带有soft label的数据,labeled数据量大大增加
iPET
由于一些模式的表现(可能要比其他模式差得多),因此我们最终模型的训练集可能包含许多错误标记的示例。在每个PVP训练的过程中,互相之间是没有耦合的,就是没有互相交换信息,因此作者提出了iPET(在原始数据集中加入随机的PET模型产生的labeled example,example∈D),IPET的就是想通过迭代,不断扩充上面训练PVP的数据集。

-
随机从前一步的迭代中选取λ*(n-1)的模型
-
用选到的模型创建labeled dataset

-
对每个类别 l 从
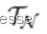 选取
选取 个样本,选择的概率为每个样本获得的
个样本,选择的概率为每个样本获得的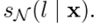
-
将样本合并(不断用准确率高的label dataset来填充)
数据集
Yelp:任务是根据顾客的评论文本估计顾客给一家餐厅的1-5星评分


AG’s News:新闻分类数据集

Yahoo:是一个文本分类数据集。 给定一个问题A和一个答案B,必须指定十个可能的类别之一。 我们使用与AG的新闻相同的模式,但我们将P5中的“news”替换为“question”。 我们定义了一个动词,将类别1-10映射到“社会”、“科学”、“健康”、“教育”、“计算机”、“体育”、“商业”、“娱乐”、“关系”和“政治”。
MNLI:提供很多句子对,任务是找出A是否暗示B,A和B是否相互矛盾或两者都不矛盾

训练结果
消融实验
模型蒸馏

辅助语言模型
iPET迭代
总结
文章表明,为预先训练的语言模型提供任务描述可以与标准监督训练相结合。 提出的方法PET包括定义成对的完形填空问题模式和映射词,帮助利用预先训练的语言模型中包含的知识来完成下游任务。 通过用所有pattern-verbalizer来调整语言模型,并使用它们创建大型注释数据集,在这些数据集上可以训练标准分类器。 当初始训练数据量有限时,PET比标准监督训练和强半监督方法有很大的改进。
训练过程总结
•对于每个pattern,分别使用一个语言模型(PLM)在小规模的数据集上进行微调;
•集成所有的语言模型并为unlabeled数据集上进行标注,标注结果为soft-label(即每个label的概率分布);
•使用带有soft-label的数据,使用标准的classifier进行分类。
参考博客
NLP文本分类大杀器:PET范式
论文解读:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference