深度学习网络记录——持更
概览:宏观(大型网络、小网络模块)+微观(各组件及相关)
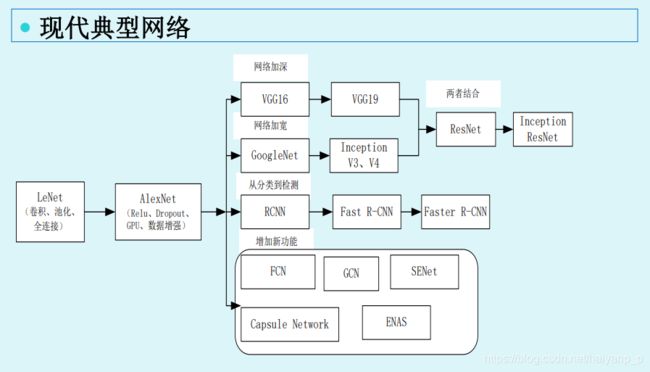
- 经典大型网络
-
-
- LeNet
- AlexNet
- VGG
- Inception
-
- Inception-v1 : 1*1的卷积进行降维减少计算成本
- Inception-v2 : 引入BN(Batch Normalization)优化——加速网络训练,防止梯度消失
- Inception-v3
- Inception-v4
- ResNet
- GAN相关
-
- 经典小网络模块
-
-
- SE网络
-
- 论文复现网络
-
-
- FSRCNN-pytorch 代码注释
- SResnet和SRGAN
-
- SRGAN相关
- SRCNN
-
- 相关组件 与 基本操作
-
-
- 深度学习相关模块
- 模型加载
- 最后一层激活和损失函数的选择
- 反向传播
-
- 迁移学习
-
-
- vgg模型(先说 如何重建网络 再说 如何迁移)
-
- (法一)重建网络:VGG16网络权重直接载入模型
- (法二)重建网络并迁移学习:构造网络模型 并 加载权重参数(以vgg为例)
-
- 算法与思想
-
-
- k折交叉验证
-
经典大型网络
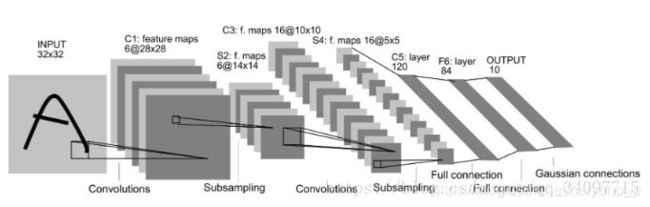
LeNet
共七层:卷积——池化——卷积——池化——全连接(3层)
有全连接层的,INPUT的图像必须是定尺寸的。
AlexNet
共八层,其中有5个卷积层和3个全连接层。
不同于LeNet,使用了Relu激活函数,收敛速度快,但需要做normalization(标准化)。需要dropout,防止过拟合。还增加了data augmentation(数据增强),对图像进行旋转等操作就形成了新的数据,又例如加入噪声可提高泛化能力。
参考文章
VGG
全连接层做了改进 用卷积的形式代替 这样在测试阶段输入的图片可不被限制。
参考文章,写的很好懂!
Inception
Inception-v1 : 1*1的卷积进行降维减少计算成本
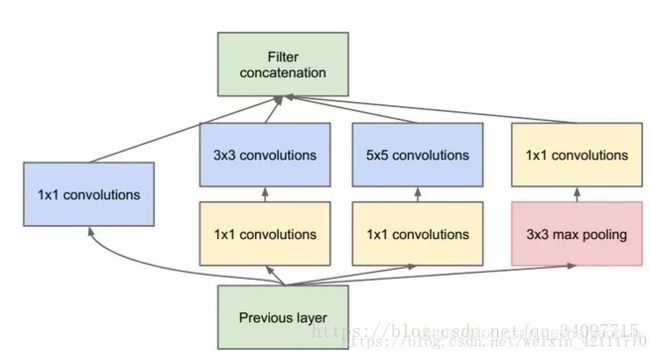
Inception-v2 : 引入BN(Batch Normalization)优化——加速网络训练,防止梯度消失
网络堆叠导致的internal covariate shift(内部协变量偏移) 需要进行batch normalization(批标准化)来加速网络收敛及防止梯度消失.
internal covariate shift在训练过程中,随着网络加深,分布逐渐发生变动,导致整体分布逐渐往激活函数的饱和区间移动,从而反向传播时底层出现梯度消失,也就是收敛越来越慢的原因。
标准化是把分布强行拉回到均值为0方差为1的标准正态分布, 是把大部分激活的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。

参考文章 : Internal Covariate Shift与Normalization
参考文章 : 内部协变量偏移(Internal Covariate Shift)和批归一化(Batch Normalization)
Inception-v3
分解卷积核尺寸,就是VGG中的思想,将55的卷积核替换成2个33的卷积核

上图左边是原来的Inception,右图是改进的Inception。(还有一种方法,详见参考)
兼顾 特征图尺寸降低 与 网络表达能力
pooling层会大量的损失信息,通过增加特征图的厚度就是双倍增加滤波器的个数)来保持网络的表达能力,但是计算量会大大增加。作者在保持pooling层的同时加入卷积层,两条路生成的特征图大小一致,按dim=1(通道Channel的方向)concat在一起即可。
Inception-v4
Inception结合ResNet

添加链接描述
ResNet

(1)左边是identity mapping,右边是residual mapping,网络浅就去用左边的,要是够深用右边的。因为右边那个有一个1*1的conv层,它在这是用来减少计算量的。
(2)加法计算size不一样时使用 projection shortcuts ,一致时使用恒等映射。
inception-v1,v2,v3,v4----论文笔记
GAN相关
一文读懂GAN, pix2pix, CycleGAN和pix2pixHD
经典小网络模块
SE网络
Squeeze-and-Excitation Networks 的理解
示例代码(李重仪Unet里有实现这部分):
先给出结构框图(被红色框起来的是实现SE的部分):
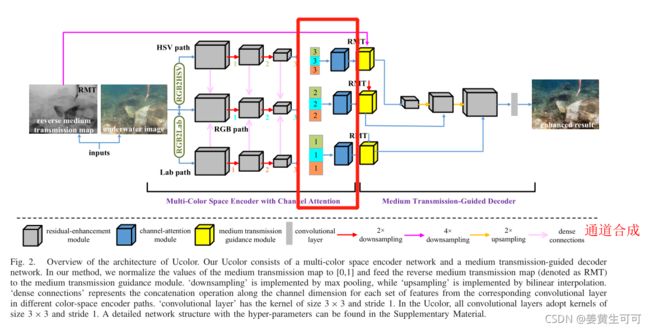
代码如下:
SE网络实现部分
def Squeeze_excitation_layer(self, input_x, out_dim, ratio, layer_name):
with tf.name_scope(layer_name) :
# GlobalAveragePooling2D是平均池化的一个特例,它不需要指定pool_size和strides等参数,操作的实质是将输入特征图的每一个通道求平均得到一个数值。
squeeze = Global_Average_Pooling(input_x)
# 全连接(输入神经元个数为out_dim,输出为out_dim / ratio) 、激励函数ReLu、全连接(输入个数为out_dim / ratio,输出个数为out_dim)、激励函数Sigmoid(结果是每个通道的权重 是概率 因此要用sigmoid 使结果保持在0-1)
excitation = Fully_connected(squeeze, units=out_dim / ratio, layer_name=layer_name+'_fully_connected1')
excitation = Relu(excitation)
excitation = Fully_connected(excitation, units=out_dim, layer_name=layer_name+'_fully_connected2')
excitation = Sigmoid(excitation)
excitation = tf.reshape(excitation, [-1,1,1,out_dim]) # 得到的是每个通道的权重
# 输入每个通道 * 各自通道的权重
scale = input_x * excitation
return scale
SE网络在整个模型中的用法
######################################### concate ##################################################
# 对三个空间第三层的结果在channel方向上合成, 此时的channel维度为512*3=1536
third_con= tf.concat(axis = 3, values = [third_add1,third_add1_HSV,third_add1_YUV])
# 调用SE,都参考文章可知输入是H*W*C 输出是1*1*C 即C不变为1536 因此out_dim=1536 得到的是每个维度的权重
channle_weight_third_con_temp=self.Squeeze_excitation_layer(third_con, out_dim=1536, ratio=16, layer_name='channle_weight_third_con_temp')
# 通过卷积降维
third_con_ff = tf.nn.relu(conv2d(channle_weight_third_con_temp, 1536,512,k_h=3, k_w=3, d_h=1, d_w=1,name="third_con_ff"))
# 第二层的合成同理
second_con= tf.concat(axis = 3, values = [second_add1,second_add1_HSV,second_add1_YUV])
channle_weight_second_con_temp=self.Squeeze_excitation_layer(second_con, out_dim=768, ratio=16, layer_name='channle_weight_second_con_temp')
second_con_ff = tf.nn.relu(conv2d(channle_weight_second_con_temp, 768,256,k_h=3, k_w=3, d_h=1, d_w=1,name="second_con_ff"))
# 第一层的合成同理
first_con= tf.concat(axis = 3, values = [first_add1,first_add1_HSV,first_add1_YUV])
channle_weight_first_con_temp=self.Squeeze_excitation_layer(first_con, out_dim=384, ratio=16, layer_name='channle_weight_first_con_temp')
first_con_ff = tf.nn.relu(conv2d(channle_weight_first_con_temp, 384,128,k_h=3, k_w=3, d_h=1, d_w=1,name="first_con_ff"))
论文复现网络
FSRCNN-pytorch 代码注释
train部分
import argparse
import os
import copy
import torch
from torch import nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
from tqdm import tqdm
from models import FSRCNN
from datasets import TrainDataset, EvalDataset
from utils import AverageMeter, calc_psnr
if __name__ == '__main__':
# 输入参数
parser = argparse.ArgumentParser()
parser.add_argument('--train-file', type=str, required=True)
parser.add_argument('--eval-file', type=str, required=True)
parser.add_argument('--outputs-dir', type=str, required=True)
parser.add_argument('--weights-file', type=str)
parser.add_argument('--scale', type=int, default=2) # 最后一层反卷积放大的倍数,用_x3.h5的时候,scale设为1。
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--num-epochs', type=int, default=20)
parser.add_argument('--num-workers', type=int, default=8)
parser.add_argument('--seed', type=int, default=123)
args = parser.parse_args()
# 创建输出文件夹
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
# 用gpu加速
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(args.seed)
# 实例化网络 定义loss函数 设计优化器并给出待训练的参数以及学习率衰减率
model = FSRCNN(scale_factor=args.scale).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam([ # 第一个参数 为包含所有需要更新可进行迭代优化的参数的 列表;可以指定程序优化特定的选项,例如学习速率lr,权重衰减 momentum等。
{'params': model.first_part.parameters()},
{'params': model.mid_part.parameters()},
{'params': model.last_part.parameters(), 'lr': args.lr * 0.1}
], lr=args.lr) # model.first和mid_part将使用args.lr ; model.last_part将使用0.1*args.lr
# 加载本地数据集并实例化为train_dataset eval_dataset 实例化数据迭代器train_dataloader eval_dataloader(训练 测试)
#
train_dataset = TrainDataset(args.train_file)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.num_workers,
pin_memory=True)
eval_dataset = EvalDataset(args.eval_file)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
# 深拷贝模型参数
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
for epoch in range(args.num_epochs):
############################# 训练 #########################################
model.train()
epoch_losses = AverageMeter()
# tqdm:进度条 拿到数据后 迭代 训练求预测值 loss(并更新) 梯度清零 后向传播 梯度更新 求平均loss
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size), ncols=80) as t:
t.set_description('epoch: {}/{}'.format(epoch, args.num_epochs - 1))
for data in train_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
preds = model(inputs)
loss = criterion(preds, labels)
epoch_losses.update(loss.item(), len(inputs)) # 求每个epoch的loss和 ;用的是AverageMeter()的update方法
optimizer.zero_grad() # 梯度清零
loss.backward() # 后向传播求梯度
optimizer.step() # 梯度更新
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg)) # 求每个epoch的平均loss
t.update(len(inputs))
# 每个epoch后 保存模型参数
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
################################## 测试 ###################################
# 验证 循环迭代验证集 with不求导:运行model网络得到预测结果, 用AverageMeter对象epoch_psnr的update方法更新psnr值(一个batch的和) 然后用.avg求平均
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# with不计算梯度:运行model网络得到预测结果, 用AverageMeter对象epoch_psnr的update方法更新psnr值(一个batch的和)
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0)
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
# 保存最好的模型参数
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
model部分
class FSRCNN(nn.Module):
def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):
super(FSRCNN, self).__init__()
# 把卷积和激活串起来
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),
nn.PReLU(d)
)
# 中间层包括卷积和激活 ,extend和Sequential的作用差不多 都是把网络串起来
self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]
for _ in range(m):
self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])
self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])
self.mid_part = nn.Sequential(*self.mid_part)
# 最后一层反卷积 恢复到hr的尺寸
self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,
output_padding=scale_factor-1)
self._initialize_weights()
# 初始化权重 卷积层的权重用的是均值方差来做的归一化 偏置设为0
def _initialize_weights(self):
for m in self.first_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
for m in self.mid_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.last_part.bias.data)
# 前向传播 show网络是怎么传播的
def forward(self, x):
x = self.first_part(x)
x = self.mid_part(x)
x = self.last_part(x)
return x
Dataset部分
import h5py
import numpy as np
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self, h5_file):
super(TrainDataset, self).__init__()
self.h5_file = h5_file
# lr是input hr是相当于真实值(类比分类网络的标签)
# 分别对其做归一化 并扩充通道 变成能输入网络的tensor形式 【x, c, h, w】
def __getitem__(self, idx):
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][idx] / 255., 0), np.expand_dims(f['hr'][idx] / 255., 0)
def __len__(self):
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])
class EvalDataset(Dataset):
def __init__(self, h5_file):
super(EvalDataset, self).__init__()
self.h5_file = h5_file
def __getitem__(self, idx):
with h5py.File(self.h5_file, 'r') as f:
return np.expand_dims(f['lr'][str(idx)][:, :] / 255., 0), np.expand_dims(f['hr'][str(idx)][:, :] / 255., 0)
def __len__(self):
with h5py.File(self.h5_file, 'r') as f:
return len(f['lr'])
SResnet和SRGAN
-
SRGAN相关
SRGAN重新定义了损失函数,并将其命名为感知损失(Perceptual loss)。感知损失有两部分构成:
感知损失=内容损失+对抗损失
对抗损失——生成器和判别器的差异
内容损失——不仅关心像素亮度值间差异,还关心图像的固有特征间的差异(语义特征)
迁移学习——特征的迁移:将vgg19中特征提取部分拿过来,用来计算内容的损失
vgg19.features.children:返回vgg的feature部分的每一层网络
详解:
class SegNet(nn.Module):
def __init__(self, num_classes):
super(SegNet, self).__init__()
vgg = models.vgg19_bn(pretrained=True)#pretrained=True下载网络的权重
# if pretrained:
# vgg.load_state_dict(torch.load(vgg19_bn_path))
features = list(vgg.features.children())
self.enc1 = nn.Sequential(*features[3:7]) #
VGG模型结构由三部分组成:
VGG(
(features):
(avgpool):
(classifier):
)
vgg.features是提取vgg模型的features网络层部分。children返回的是结构中的每一层网络即 Sequential中的每一层,而module不但返回每一层,而且还返回Sequential[…]这个完整的部分。
引用文章:vgg19.features.children的理解,写的很全面!
VGG16、VGG16_bn、VGG19_bn详解以及使用pytorch进行模型预训练,关注:加载一张图片,然后用于预训练模型训练。
资源传送:vgg19的用法汇总
-
SRCNN
参考文章
相关组件 与 基本操作
深度学习相关模块
待看
模型加载
keras读取h5文件load_weights、load代码详解
最后一层激活和损失函数的选择

反向传播
部分符号说明(详见参考文章)
- L表示层,具有相对意义。
- a表示激活后的,即每层的输出。z表示激活前的,即每层的输入,也就是经过权重与偏置的乘积求和后得到的。
- δ是每层“错误”总和,也就是这一层被用来更新的总梯度值。

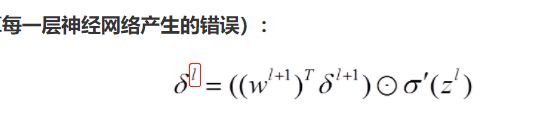
对于L(大、小写)层不同的神经元j有不同的δ
步骤
- 前向传播预测结果并计算损失C
- 反向传播计算每一层每个神经元产生的错误δ(梯度)
- 梯度更新是对w和b!!!(下一层的权重WL+1和偏置BL+1的更新 通过 本层输出aL与下一层δL+1的乘积,每次乘积得到的均是向量,维度是是本层神经元 与 下层连接的神经元个数)
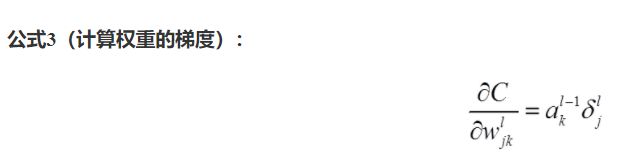


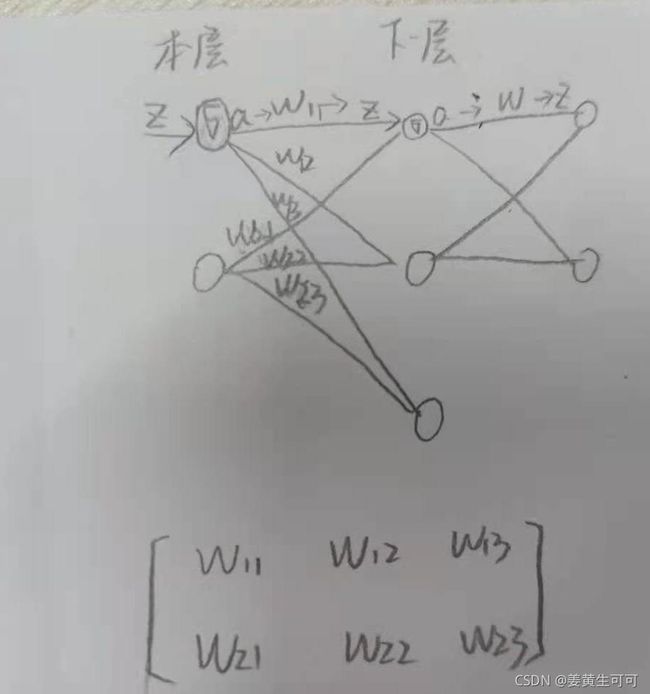
这里可以看出w是个矩阵。因为 δ是向量 a也是向量 。列向量✖行向量是一共矩阵。即本层 j 个神经元 与 下一层 k 个神经元的链接产生的权重,矩阵中的每一列是本层的第 j 个神经元与下一层所有神经元连接产生的权重,每一行是本层所有神经元与下一层第k个神经元连接产生的权重。如下图。
参考文章:反向传播算法(过程及公式推导)
反向传播——通俗易懂 确实通俗易懂
迁移学习
vgg模型(先说 如何重建网络 再说 如何迁移)
(法一)重建网络:VGG16网络权重直接载入模型
import tensorflow as tf
model=tf.keras.applications.vgg16.VGG16(weights=True,include_top=True)
#下载模型及权重,带全连接层权重,缺点:速度慢
(法二)重建网络并迁移学习:构造网络模型 并 加载权重参数(以vgg为例)
权重及网络层的两种常用文件格式:.mat 和 .npy
- .mat文件
很多数据集都是mat格式的标注信息,使用模块scipy.io的函数loadmat和savemat可以实现Python对mat数据的读写。
参考:读取mat数据:scipy.io.loadmat模块使用
如下图所示:保存数据和标签,这种形式十分适用于权重参数的保存(权重与对应层名称)

参考:sicpy官方文档
.mat文件用法如下:读入的数据为字典,包括6个键值对,主要关注‘layers’、‘normalization’
【补充:下图中的vgg也可以在pycharm通过断点调试的方式查看(见本小节最后)】
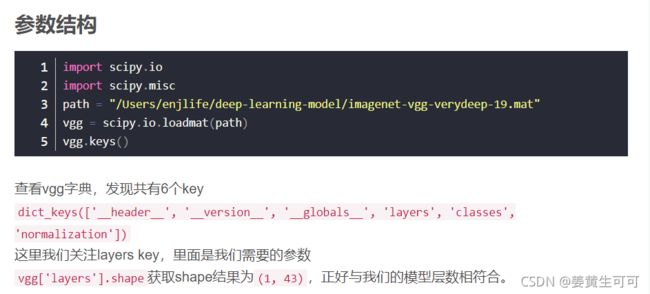
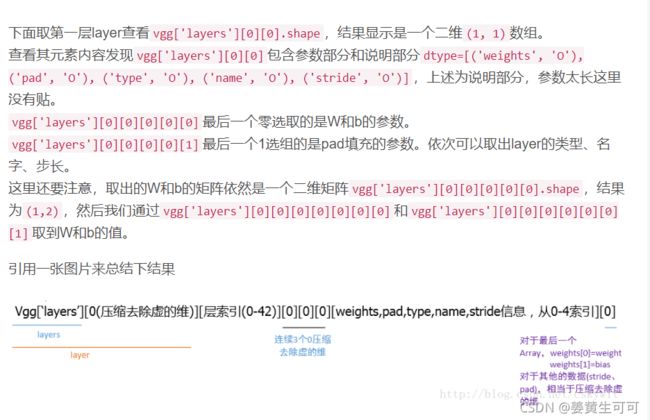

深度学习理解概念系列——VGG模型参数
imagenet-vgg-verydeep-19参数解析
补充:pycharm里ucolor开源代码文件夹下调试: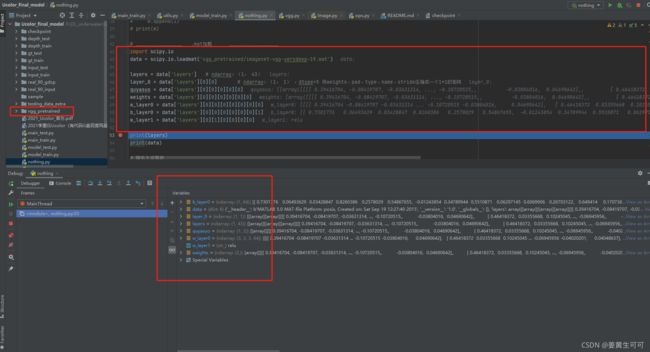
在Ucolor(tensorflow框架下)的vgg.py中是这样用的:
(1)定义网络:
def net(权重参数地址, 输入进网络的图片):
给出网络各层名称 —— 加载权重 —— 遍历将权重赋值给网络

注释:
# Ucolor中有vgg迁移学习的部分
kernels = np.transpose(kernels, (1, 0, 2, 3))
# matconvnet: weights 格式 [width, height, in_channels, out_channels]
# tensorflow: weights 格式 [height, width, in_channels, out_channels]
参考:FCN Tensorflow源码阅读注释和总结
(2)上述网络定义涉及到下面的定义,尤其注意vgg的输入是要经过0均值预处理的(所用均值的计算方法下面已给出)。preprocess()的调用是在model_train.py中的build_model()中
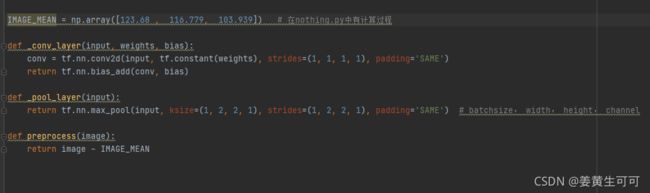
计算0均值操作中的均值: 
这里的build_model()是在定义自己的网络模型,其中损失函数用的是mse(像素级的loss)+vgg_loss(特征级的loss) 【这里就是迁移学习了】

- .npy文件 —— .npy文件是numpy专用的二进制文件
- .npy基本操作 —— 读取与保存
np.save(‘weight.npy’, arr)
loadData = np.load(‘weight.npy’)
python读取npy文件 - 实操(仍以vgg16为例,keras框架下)
载入壳模型 —— 获取本地文件的参数 —— 将参数逐层载入模型
import tensorflow as tf
import numpy as py
# 把VGG16网络的结构设置好,此时网络没有权重,类似一个空壳
model=tf.keras.applications.vgg16.VGG16(weights=None,include_top=True)
# 这是一个储存VGG16权重的字典文件,结果是# {'conv5_4':~~}(list:2)共19个字典
data_dict=np.load('D:/vgg16.npy',encoding='latin1',allow_pickle=True).item()
# 获得了VGG16.npy内部存储的模型各权重层名称
for key in data_dict:
print (key)
# 按层数逐层给模型权重层载入权重系数
model.layers[1].set_weights(data_dict['conv1_1'])
model.layers[2].set_weights(data_dict['conv1_2'])
model.layers[4].set_weights(data_dict['conv2_1'])
model.layers[5].set_weights(data_dict['conv2_2'])
model.layers[7].set_weights(data_dict['conv3_1'])
model.layers[8].set_weights(data_dict['conv3_2'])
model.layers[9].set_weights(data_dict['conv3_3'])
model.layers[11].set_weights(data_dict['conv4_1'])
model.layers[12].set_weights(data_dict['conv4_2'])
model.layers[13].set_weights(data_dict['conv4_3'])
model.layers[15].set_weights(data_dict['conv5_1'])
model.layers[16].set_weights(data_dict['conv5_2'])
model.layers[17].set_weights(data_dict['conv5_3'])
model.layers[20].set_weights(data_dict['fc6'])
model.layers[21].set_weights(data_dict['fc7'])
model.layers[22].set_weights(data_dict['fc8'])
# 本想用循环实现上述功能,但发现文件里的层不是按顺序来的,故只能用手动对应,且注意要留出激活层的位置
############### 无用 ###############
i = 0
for key in data_dict:
i += 1
print(key)
model.layers[i].set_weights(data_dict[key])
# 查看是否赋值对应上了
print("model.layers[{}].data_dict[{}]".format(i , key))
######################################
# 存储VGG16模型和权重
#这样就把VGG16模型存储在当前路径下了(要不要将.npy文件中没有的层补上)
model.save("VGG16.h5")
#把VGG16文件模型权重系数存储在当前路径下,大小约为527M
model.save_weights("VGG16_weights.h5")
参考:使用VGG16.npy文件载入权重
vgg的复现及迁移学习可以看下面的两个文章:
经典网络-使用VGG16进行迁移学习
VGG16学习笔记_韩鼎の个人网站:复现vgg16+原理
算法与思想
k折交叉验证
寻找最优模型—K折交叉验证