mobilenet系列论文解读:从v1-v3
一文看遍mobilenet,毫无疑问,移动端的轻量级网络中mobienet肯定是首当其冲,从v1-v3,有着相当的提升和改进,但究其核心,最主要的还是引入了深度可分离卷积的计算,确实很有代表性,不过在v3中引入了NAS,这就比较玄学了,v3我没有直接复现过,只玩过基于它实现的目标检测网络,v3的yolov3我记得可以在voc上做到74%左右,效果挺好的,v1和v2的目标检测网络,比如mobilenet-ssd、mobilenet-yolo在部署的时候的确相当轻量化,尤其是当年mobilenetv1-ssd结合tensorflow的object-detection api来做,可以同时完成模型缩放和量化,模型大小只有几M,非常轻量化,本文详细解读mobilenetv1-v3的技术要点和变化,但不按照论文的结构和格式来叙述。
code:本文不提供code,详见各个框架的backbone
1、mobilenet-v1
paper:https://arxiv.org/pdf/1704.04861.pdf
v1中创新式的提出了构建mobilenet的核心层,称之为深度可分离卷积(depthwise separable filters),为整个mobilenet系列奠定了基础。
depthwise separable convolutionds是分解卷积的一种形式,可以将其拆解为深度卷积和点卷积(1*1卷积),如下图所示:

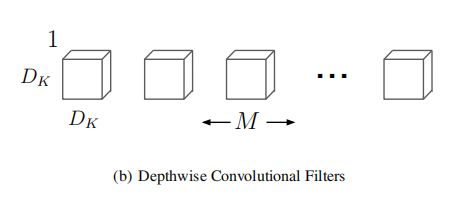

如上图所示,图a代表着Dk*Dk*M的conv layer,我们将其拆分为图b和图c两个卷积,这样得到的输出维度是一致的,但计算量和模型大小却明显得到减少,具体原理如下:
一个标准的卷积输入Batch*Df*Df*M的特征图,其中Df是输入特征图的宽度和高度,M是输入通道,假定输出特征图为Batch*Df*Df*N,N为输出通道。那么,对于标准卷积的计算量为:
Batch*Df*Df*M*N*Dk*Dk
怎么理解标准卷积计算量?简单说一下,可以理解为Df*Df的特征图与Dk*Dk的卷积进行计算,计算量为Df*Df*Dk*Dk,输入特征图有M个通道,对应卷积核也有M个输入通道,则由M个Df*Df的特征图与Dk*Dk卷积进行计算,则此时计算量为Df*Df*Dk*Dk*M,最后,有N个输出通道,则再将上一步的计算重复N次,最终计算量就变成了Df*Df*M*N*Dk*Dk。
拆分后,depthwise conv的计算量为:Batch*Df*Df*Dk*Dk*M,这里要注意一下,拆分后,卷积相乘时维度是对不上的,因此其实depthwish卷积是对每个输入通道单独使用1个卷积核来处理,并且结果不累加(常规卷积会累加输入通道的结果变成一个通道输出),那么此时输出特征维度依旧为batch*Df*Df*M。
进一步的,中间输出特征图再与点卷积相乘,此时的计算量为batch*Df*Df*M*N,输出特征维度为batch*Dk*Dk*N。
此时,计算量对比如下:

上面为mobilenet v1提出来的depthwise separable 卷积,下面是mobilenet v1的网络结构(注意:深度卷积只是起到了常规卷积的作用,但并不是直接替换常规卷积就能够跟常规卷积一样的效果,同样需要依赖于特定的网络结构,举例:darknet53如果你直接替换为depthwise separable darknet53,网络是不会收敛的!!!!)
v1的基本block(与常规3*3卷积的区别):
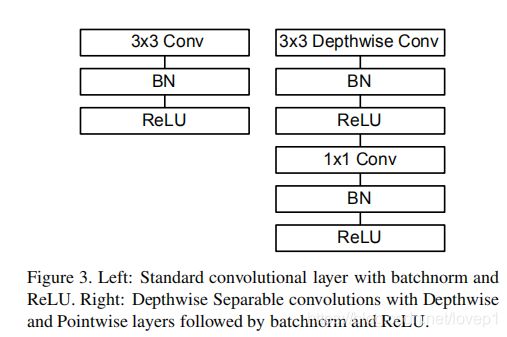
v1的网络结构如下:

v1的网络宽度和深度的参数调整:
上面的网络结构可以将其作为mobilenet的baseline,在这个基础上,我们进一步的引入两个参数width multiplier和resolution multiplier来对backbone进行进一步压缩裁剪。第一个参数width multiplier主要是按比例减少通道数,该参数记为  ,其取值范围为(0,1],那么输入与输出通道数将变成 M 和N ,应用于depthwise separable convolution,其计算量变为:
,其取值范围为(0,1],那么输入与输出通道数将变成 M 和N ,应用于depthwise separable convolution,其计算量变为:
![]()
第二个参数 用于减小分辨率,即按照比例减小特征图的大小,加上这个参数,则整体计算量为:
用于减小分辨率,即按照比例减小特征图的大小,加上这个参数,则整体计算量为:
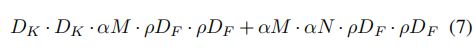
注意,resolution multiplier仅仅影响计算量,但是不改变参数量(因为没裁剪啥卷积核什么的)。
v1总结:主要是提出了可分离卷积这个结构,然后顺势提出了mobilenet这个backbone结构,更进一步的,由于是google本身提出的,google将其应用到了object/face detection,取得了不错的效果,但是值得注意的是,不要随便修改那两个通道数和分辨率的超参数,都选择为1.0是比较好的,否则精度下降莫名其妙,相信我,都选择1是最好的,而且在cpu上跑的贼快,越烂的cpu越能够看到明显的加速效果,在gpu上加速倍数就没那么明显了,有时甚至还不如我剪枝后的网络。
2、mobilenet-v2
v1的主要思想是在于提出了深度可分离卷积和与之配套的backbone这2点,v2的核心在于在v1的基础上,发现v1的不足,基本上就是relu带来的,针对这些不足,进一步的调整基本的卷积结构,从而达到更好的效果。
paper:https://arxiv.org/abs/1801.04381
首先分析v1的不足:
1、 Relu本身会破坏高维featuremap
2、relu负半轴为0的特性带来的神经元dead。
我们看看原文怎么说:



如上图figure1所示,input是一个2维度数据,文中有一个称之为manifold of interest的东西就是蓝色的螺旋线,文中使用矩阵T将数据映射到多维空间,然后接了relu,再使用T的逆矩阵,将其映射回2d平面,我们可以看到,当维度为2、3时,映射回来信息丢失很严重,中心点坍塌了,当维度为15、30左右,损失的信息才会变得少起来。这意味着在低维的时候,relu会导致很多信息的丢失(由于负值直接映射为0的机制)
1、 relu能够保留输入manifold 的完整信息,但前提是输入manifold 位于输入空间的低维子空间中。(如上面Figure 1的示意图-哎不懂就算了,写的啥玩意,又写论文就写得让人看不懂,翻译过来更看不懂)
2、如果经过ReLU变换输出是非零的,那输入和输出之间是做了一个线性变换的,即将输入空间中的一部分映射到全维输出,换句话来说,relu的作用是线性分类器。
从上面这个实验得到,我们设计网络结构的时候,想要减少运算量,就需要尽可能将网络维度设计的低一些,但是维度如果低的话,激活变换ReLU函数可能会滤除很多有用信息。然后我们就想到了,反正ReLU另外一部分就是一个线性映射。那么如果我们全用线性分类器,会不会就不会丢失一些维度信息,同时可以设计出维度较低的层呢?
然后文章针对这个问题使用了linear bottleneck(即不使用relu激活,直接做线性变换)来代替原本的非线性激活,则思路为:在卷积模块中插入linear bottleneck来捕获manifold of interest,然后再进一步引入从linear bottlenect到深度卷积之间的维度比称之为Expansion factor(扩展系数)。
v2的模块结构(Inverted residuals)-此图来源https://zhuanlan.zhihu.com/p/98874284 侵删

如上图所示,中间层依旧为深度可分离卷积,但在前面是用了expansion layer和在后面加了projection layer:
expansion layer:使用1*1的卷积结构,目的是将低维空间映射到高维空间,上文提到该结构中包含扩展系数这个超参数,设定将维度扩展几倍(6)
projection layer:使用1*1的卷积结构,将高维空间映射到低维空间去。
Inverted residuals通道升降维示意图如下图所示:

从上图可以看出,v2的网络结构便是先对输入特征进行升维,经过深度分离卷积后,再进行降维到与原来一致的通道,同时,不再使用relu函数而改使用relu6函数,最后的线性层直接使用线性激活函数(说白了就是1*1的点卷积后面不加激活层。。。害我理解了半天代码)。
v2与v1的对比(图来源:https://zhuanlan.zhihu.com/p/33075914 侵删):
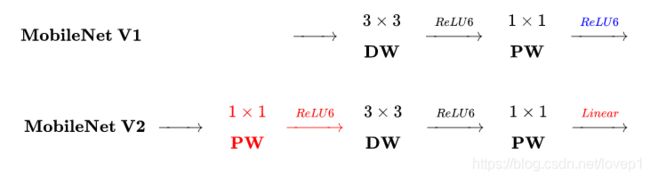
简单来说,v2在深度卷积前新加了一个pw卷积,因为dw卷积无法升降维度,通过pw卷积升维获取更多的特征(expand factor),v2去掉了最后的非线性激活函数(不加激活函数)。
v2与resnet的对比:

简答来说,v2使用的是dw卷积,而非标准卷积;resnet先降维,再升维,v2先升维,再降维。
v2的整体网络结构如下:
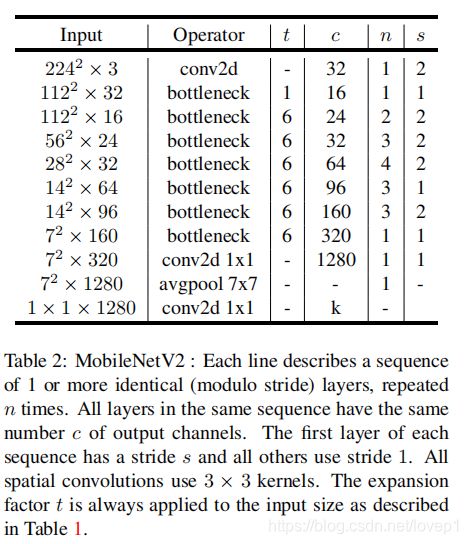
参数意义:t-扩张系数(Expansion factor) c-原始通道数 n-当前residual block的block数 s 下采样stride
测试结果:
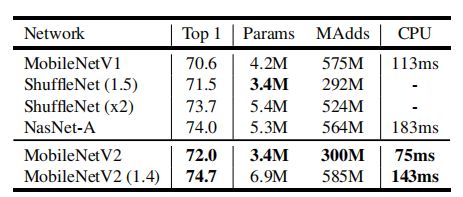

v2总结:基本上就是分析了relu的问题,认为既要在高维处理特征保证特征提取,又要在低维防止特征丢失,因此采用先升维后降维的方式,修改了一个新的block,然后又提出了新的backbone。
注意:v2的速度比v1慢?这个实际测试好像是存在这个问题,唯一可以确定是,v2精度比v1高,速度测试慢一点,不知道移动端是否会变得快一些。
参考文章:https://zhuanlan.zhihu.com/p/33075914
3、mobilenet-v3
paper:https://arxiv.org/pdf/1905.02244.pdf
回顾一下mobilenet系列,v1主要是提出了深度卷积和backbone,v2主要是提出了residual block和线性分类器(不用激活层),而到了v3,v3用重新结合了v1和v2的优点,重新设计了1个block,然后再使用nas搜索,得到一个新的网络结构v3-large/small,称之为mobilenet v3。
直接看v3的改进:
1、基本block的改进
直接看原文的改进示意图:

在DW卷积之后引入了Mnasnet的SE结构,由于SE结构会消耗时间,将expansion layer的channel变为原来的1/4。
特定看一下SE结构(下图的源码是mnasnet的源码,并非v3的),如下图所示,对然后求通道的均值(并不是pool-v3中写的是pool),然后输入特征图进行挤压降维后,加入relu激活函数,再对输出特征进行维度扩张(conv操作),最后对输出的特征执行sigmod,得到注意力参数(hard-sigmod原文),将其乘以最原始的input_tensor,
code:https://github.com/tensorflow/tpu/blob/da262fcba1d0598321d4eb9aa1954fcbf84d1807/models/official/mnasnet/mnasnet_model.py


2、nas的搜索我就不写了,不会,不理解,很难受,这种高级领域我完全不懂(没卡?)
简单提一下这个流程:先使用nas永华每一个block,得到答题的网络结构,在使用netAdapt来确定每个filter的channel数量,因此提出了v3 small和v3 large两个级别的网络。(我根本不懂,完全抄自别人的博客)
3、尾部改进
作者发现v2网络的最后阶段计算量很大,重新设计了结构,如下图所示:

在v2中,在avg pooling之前,存在在avg pooling之前,存在一个1x1的卷积层,目的是提高特征图的维度,更有利于结构的预测,但是这其实带来了一定的计算量了,所以这里作者修改了,将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。并且为了进一步的降低计算量,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量,就变成了如下图第二行所示的结构,作者将其中的3x3以及1x1去掉后,精度并没有得到损失。这里降低了大约15ms的速度。
4、网络结构-修改channels的数量
修改了整体网络卷积核的数量,v2中使用的是32*3*3,v3中变小了,改成了16,降低了3ms的速度·1,如下所示:


5、激活函数的变化
使用了hard-swish来替换swish。swish在嵌入式中并不友好,但发现在嵌入式中大部分芯片都会使用relu6,因此将swish修改为hard-swish,公式如下:

如上,利用relu6魔改为hard-swish,计算成本很小且方便模型的量化,据说推理速度增快15%(也不知道googl怎么测试的)
最后,直接看v3的结果:


总结:v3的改进点在于在v1、v2的基础上,加入了SE模块,更进一步的修改了block的结构;然后修改了尾部结构,减少了计算量;同时利用nas搜索了最佳backbone组合;然后基于嵌入式提出了hard-swish的非线性激活。
综上,便是mobilenetv1、v2、v3的细节概述了,其中v3我没那么上心,因为涉及到了nas,这有点让人无奈,v1、v2的backbone我在目标检测上也做了相当的实验,但不得不承认,如果只考虑性能,其实针对目标检测算法,剪枝和量化是不是更加实用,毕竟从我的经验来看,一般的模型剪枝一半基本上精度差异不会太大,主要还是mobilenet的移动端的速度确实有优势,复杂的网络即使剪枝到很小,深层的网络仍然需要大的计算量,但是剪枝的算法通常会比轻量化backbone精度要高(不要做到极限压缩)。