NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
5.5 实践:基于ResNet18网络完成图像分类任务
- 5.5.1 数据处理
-
- 5.5.1.1 数据集介绍
- 5.5.1.2 数据读取
- 5.5.1.3 构造Dataset类
- 5.5.2 模型构建
- 必做题
-
- 什么是“预训练模型”?什么是“迁移学习”?
- 比较“使用预训练模型”和“不使用预训练模型”的效果。
- 5.5.3 模型训练
- 5.5.4 模型评价
- 5.5.5 模型预测
- 思考题
-
- 1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
- 2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
- 总结
- 参考链接
在本实践中,我们实践一个更通用的图像分类任务。
图像分类(Image Classification)是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务也可以转换为图像分类任务。比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
这里,我们使用的计算机视觉领域的经典数据集:CIFAR-10数据集,网络为ResNet18模型,损失函数为交叉熵损失,优化器为Adam优化器,评价指标为准确率。
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×32像素。CIFAR-10数据集的示例如下图 所示。

数据集:CIFAR-10数据集,
网络:ResNet18模型,
损失函数:交叉熵损失,
优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
评价指标:准确率。
5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
训练集:40 000条样本。
验证集:10 000条样本。
测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import torch
from torchvision.transforms import transforms
import torchvision
from torch.utils.data import DataLoader
transformer=transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])])
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True, transform=transformer)
devset=torchvision.datasets.CIFAR10(root='./cifar10',train=False,download=True,transform=transformer)
testset=torchvision.datasets.CIFAR10(root='./cifar10',train=False,download=True,transform=transformer)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
可视化观察其中的一张样本图像和对应的标签,代码如下所示:
image,label=trainset[0]
print(image.size())
image, label = np.array(image), int(label)
plt.imshow(image.transpose(1,2,0))
plt.show()
print(classes[label])
运行结果:
torch.Size([3, 32, 32])
frog

5.5.1.3 构造Dataset类
构造一个CIFAR10Dataset类,其将继承自paddle.io.DataSet类,可以逐个数据进行处理。代码实现如下:
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision.transforms as transforms
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='train'):
if mode == 'train':
#加载batch1-batch4作为训练集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate([self.labels, labels_batch])
elif mode == 'dev':
#加载batch5作为验证集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
#加载测试集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transforms = transforms.Compose([transforms.Resize(32),transforms.ToTensor(), transforms.Normalize(mean=[0.4914,0.4822,0.4465], std=[0.2023, 0.1994, 0.2010])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='test')
5.5.2 模型构建
使用torchvision API中的Resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18(pretrained=True)
必做题
什么是“预训练模型”?什么是“迁移学习”?
1.迁移学习
迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。
为了对迁移学习产生一个直观的认识,不妨拿老师与学生之间的关系做类比。
一位老师通常在ta所教授的领域有着多年丰富的经验,在这些积累的基础上,老师们能够在课堂上教授给学生们该领域最简明扼要的内容。这个过程可以看做是老手与新手之间的“信息转移”。
这个过程在神经网络中也适用。我们知道,神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。
2.预训练
预训练模型,则是使自然语言处理由原来的手工调参、依靠 ML 专家的阶段,进入到可以大规模、可复制的大工业施展的阶段。而且预训练模型从单语言、扩展到多语言、多模态任务。
预训练通过自监督学习从大规模数据中获得与具体任务无关的预训练模型。
1) 预训练模型就是已经用数据集训练好了的模型。
2) 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数
3 ) 正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
比较“使用预训练模型”和“不使用预训练模型”的效果。
resnet18_model = resnet18(pretrained=False)
运行结果:
[Train] epoch: 24/30,step: 15000/18750,loss: 0.38762
[Evaluate] dev score: 0.70030,dev loss: 0.89444
[Evaluate] best accuracy performence has been updated: 0.69470 --> 0.70030
[Train] epoch: 28/30,step: 18000/18750,loss: 0.47557
[Evaluate] dev score: 0.68210,dev loss: 0.99598
[Evaluate]dev score: 0.69590,dev loss: 0.92128
[Train] Training done!
理论上来说,没有预训练的模型在足够的epoch训练后是可以和预训练模型相媲美的,有时候甚至会跟好点。而此处不使用预训练模型的准确率和误差都不如使用预训练模型的效果。
此处预训练模型指分类模型,将预训练模型作为检测模型主干网络
优点:
1、开源模型多,可以直接用于目标检测
2、可以快速地得到最终模型,需要的训练数据少
缺点:
1、预训练模型大、参数多、模型结构灵活性差、难以改变网络结构,计算量大,限制应用场景
2、分类和检测任务损失函数和类别分布不同,优化空间存在差异
3、尽管微调可以减少不同目标类别分布差异性,差异太大时,微调效果不明显
5.5.3 模型训练
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
from Runner import RunnerV3
from metric import Accuracy
#指定运行设备
torch.cuda.set_device('cuda:0')
# 学习率大小
lr = 0.001
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(devset, batch_size=batch_size)
test_loader = DataLoader(testset, batch_size=batch_size)
# 定义网络
model = resnet18_model
# 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.Adam(lr=lr, params=model.parameters(), weight_decay=0.005)
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
# 实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
运行结果:
[Train] epoch: 0/30, step: 0/23460, loss: 7.09256
[Train] epoch: 3/30, step: 3000/23460, loss: 0.68586
[Evaluate] dev score: 0.65970, dev loss: 0.99221
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.65970
[Train] epoch: 7/30, step: 6000/23460, loss: 0.57793
[Evaluate] dev score: 0.68040, dev loss: 0.93663
[Evaluate] best accuracy performence has been updated: 0.65970 --> 0.68040
[Train] epoch: 11/30, step: 9000/23460, loss: 0.90398
[Evaluate] dev score: 0.72970, dev loss: 0.80892
[Evaluate] best accuracy performence has been updated: 0.68040 --> 0.72970
[Train] epoch: 15/30, step: 12000/23460, loss: 0.54963
[Evaluate] dev score: 0.70290, dev loss: 0.89479
[Train] epoch: 19/30, step: 15000/23460, loss: 0.73634
[Evaluate] dev score: 0.73600, dev loss: 0.80622
[Evaluate] best accuracy performence has been updated: 0.72970 --> 0.73600
[Train] epoch: 23/30, step: 18000/23460, loss: 0.47213
[Evaluate] dev score: 0.73230, dev loss: 0.80564
[Train] epoch: 26/30, step: 21000/23460, loss: 0.52694
[Evaluate] dev score: 0.72850, dev loss: 0.81326
[Evaluate] dev score: 0.73140, dev loss: 0.79042
[Train] Training done!
在本实验中,使用了第7章中介绍的Adam优化器进行网络优化,如果使用SGD优化器,会造成过拟合的现象,在验证集上无法得到很好的收敛效果。可以尝试使用第7章中其他优化策略调整训练配置,达到更高的模型精度。
5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果:
[Test] accuracy/loss: 0.7360/0.8062
5.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
#获取测试集中的一个batch的数据
for X, label in test_loader:
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
label = label[2].data.numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(classes[label], classes[pred_class]))
#可视化图片
X=np.array(X)
X=X[1]
plt.imshow(X.transpose(1, 2, 0))
plt.show()
break
运行结果:
The true category is ship and the predicted category is ship

思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
通过引入深度残差学习框架解决了退化问题。让这些层拟合残差映射,而不是希望每几个堆叠的层直接拟 合期望的基础映射。形式上,将期望的基础映射表示为 H(x),我们将 堆叠的非线性层拟合另一个映射 F(x) = H(x) − x。原始的映射重写为 F(x) + x。我们假设残差映射比原始的、未参考的映射更容易优化。在 极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过 一堆非线性层来拟合恒等映射更容易。
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
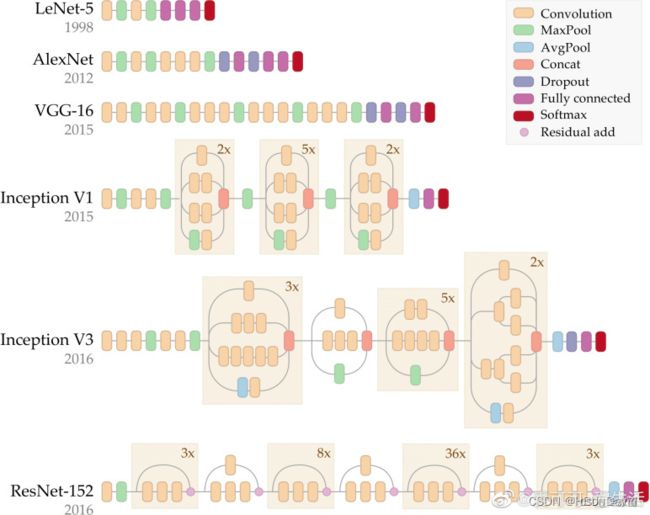
1.lenet:LeNet是最早的卷积神经网络之一。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如下图所示

2.alexnet:AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
1)数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
2)使用Dropout抑制过拟合
3)使用ReLU激活函数减少梯度消失现象
3.vgg:真正的优点是 a.feature-map不变则conv-kenel-width这些不变 b.用一次pooling,width提升一倍
VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
4.googlenet:用了split and merge 结构,但是不太容易设置,遇到新问题,需要设置的超参数多
GoogLeNet的主要特点是网络不仅有深度,还在横向上具有“宽度”。
5.resnet:主流网络,在vgg基础上提升了长度,而且加入了res-block结构,还有resnext
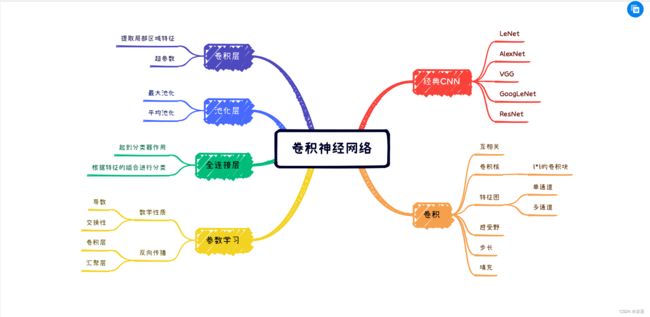
总结
使用思维导图全面总结CNN
参考链接
4、迁移学习和预训练模型
预训练模型优缺点
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
vgg和alexnet,lenet resnet等网络简要评价和使用体会
一文读懂LeNet、AlexNet、VGG、GoogleNet、ResNet到底是什么?