YOLOv5-Shufflenetv2
YOLOv5中修改网络结构的一般步骤:
models/common.py:在common.py文件中,加入要修改的模块代码
models/yolo.py:在yolo.py文件内的parse_model函数里添加新模块的名称
models/new_model.yaml:在models文件夹下新建模块对应的.yaml文件
一、Shufflenetv2
[Cite]Ma, Ningning, et al. “Shufflenet v2: Practical guidelines for efficient cnn architecture design.” Proceedings of the European conference on computer vision (ECCV). 2018.
旷视轻量化卷积神经网络Shufflenetv2,通过大量实验提出四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC(Memory Access Cost)的影响进行了详细分析:
准则一:输入输出通道数相同时,内存访问量MAC最小
Mobilenetv2就不满足,采用了拟残差结构,输入输出通道数不相等
准则二:分组数过大的分组卷积会增加MAC
Shufflenetv1就不满足,采用了分组卷积(GConv)
准则三:碎片化操作(多通路,把网络搞的很宽)对并行加速不友好
Inception系列的网络
准则四:逐元素操作(Element-wise,例如ReLU、Shortcut-add等)带来的内存和耗时不可忽略
Shufflenetv1就不满足,采用了add操作
针对以上四条准则,作者提出了Shufflenetv2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。
模型概述
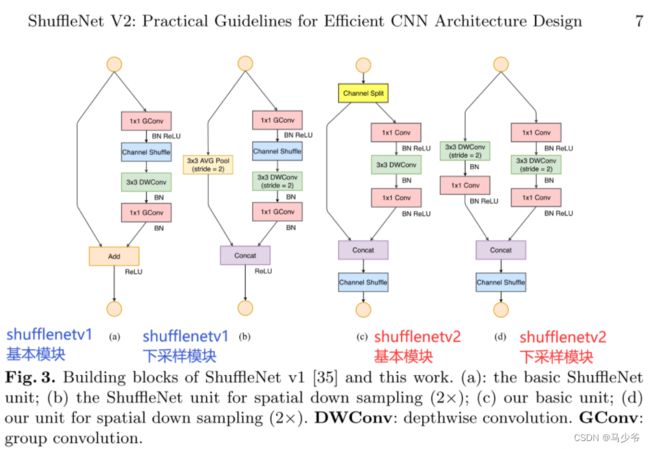
Shufflenetv2有两个结构:basic unit和unit from spatial down sampling(2×)
basic unit:输入输出通道数不变,大小也不变
unit from spatial down sample :输出通道数扩大一倍,大小缩小一倍(降采样)
Shufflenetv2整体哲学要紧紧向论文中提出的轻量化四大准则靠拢,基本除了准则四之外,都有效的避免了。
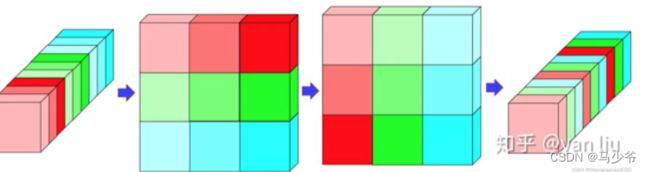
为了解决GConv(Group Convolution)导致的不同group之间没有信息交流,只在同一个group内进行特征提取的问题,Shufflenetv2设计了Channel Shuffle操作进行通道重排,跨group信息交流
class ShuffleBlock(nn.Module):
def __init__(self, groups=2):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,W] -> [N,C,H,W]'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, C//g, H, W).permute(0, 2, 1, 3, 4).reshape(N, C, H, W)
加入YOLOv5
common.py文件修改:直接在最下面加入如下代码
# ---------------------------- ShuffleBlock start -------------------------------
# 通道重排,跨group信息交流
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class conv_bn_relu_maxpool(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(conv_bn_relu_maxpool, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
# ---------------------------- ShuffleBlock end --------------------------------
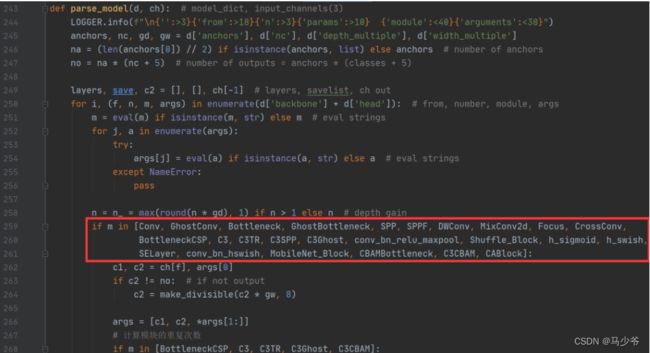
yolo.py文件修改:在yolo.py的parse_model函数中,加入conv_bn_relu_maxpool, Shuffle_Block两个模块(如下图红框所示)
新建yaml文件:在model文件下新建yolov5-shufflenetv2.yaml文件,复制以下代码即可
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# Shuffle_Block: [out, stride]
[[ -1, 1, conv_bn_relu_maxpool, [ 32 ] ], # 0-P2/4
[ -1, 1, Shuffle_Block, [ 128, 2 ] ], # 1-P3/8
[ -1, 3, Shuffle_Block, [ 128, 1 ] ], # 2
[ -1, 1, Shuffle_Block, [ 256, 2 ] ], # 3-P4/16
[ -1, 7, Shuffle_Block, [ 256, 1 ] ], # 4
[ -1, 1, Shuffle_Block, [ 512, 2 ] ], # 5-P5/32
[ -1, 3, Shuffle_Block, [ 512, 1 ] ], # 6
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 10
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 14 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 17 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 7], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 20 (P5/32-large)
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
参考文献:https://blog.csdn.net/weixin_43799388/article/details/123597320