ubuntu18.04基于darknet训练YOLOv3目标检测神经网络模型
ubuntu18.04基于darknet训练YOLOv3目标检测神经网络模型
文章目录
- ubuntu18.04基于darknet训练YOLOv3目标检测神经网络模型
-
- 1.什么是目标检测和应用神经网络进行目标检测的基本流程
-
- (1)什么是目标检测
- (2)应用神经网络进行目标检测的基本流程
- 2.什么是YOLOv3和darknet框架
- 3.准备训练集
- 4.训练模型
-
- (1)使用cpu训练
- (2)使用gpu训练
1.什么是目标检测和应用神经网络进行目标检测的基本流程
(1)什么是目标检测
简单来说,目标检测要做的主要是从一副图像上找出要寻找的目标,算法输出目标在图像中的位置和置信度(是目标的可能性)。
(2)应用神经网络进行目标检测的基本流程
第一步模型训练:
对于YOLOv3网络模型而言,本文采取的方法是使用labelImage完成VOC格式训练集的准备,使用darknet框架完成模型训练。
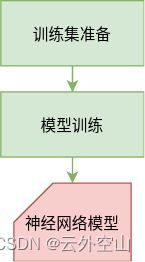
第二步应用模型完成目标检测:
本文采用opencv的DNN库完成模型加载以及推理,此处可直接使用opencv利用cpu完成推理过程,或如果是英伟达系列显卡的话可使用CUDA编译过得opencv使用gpu推理。
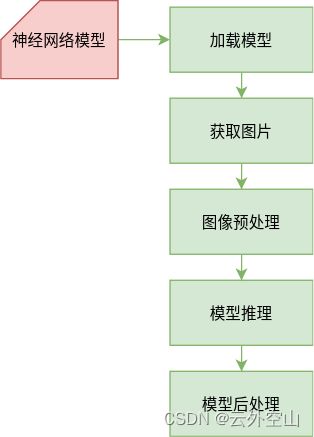
加载模型:加载模型又称为模型初始化,即将模型各个层的权重进行加载。
图像预处理:训练得到的神经网络模型都会有一个固定的图像输入分辨率和固定的数据格式,预处理就是将所得到的图片转换为模型所需格式。
模型推理:将预处理结果输出到模型之中,并使用模型进行推理计算,得到模型输出。
模型后处理:对模型输出结果进行分析整理,得到所需结果。模型输出结果往往因模型特点不同具有不同的结构,后处理首先需要对输出结果进行解析和筛选,然后才能得到所需结果。
2.什么是YOLOv3和darknet框架
YOLOv3是YOLO系列的第三个版本,也是它的作者Joseph Redmon退出CV学术界的最后一个作品。YOLO的全称为You Only Look Once(你只看一次),是一种单级目标检测器,同时也是第一个单级目标检测器。
1,2部分详细介绍请参阅综述:目标检测二十年
darknet框架为YOLOv3作者使用C++编写完成的YOLOv3神经网络训练和推理测试的应用框架,可直接对此项目代码进行编译和应用,进而完成模型训练和相关测试。
3.准备训练集
训练集也有它固定的格式,常用的格式通常为VOC和COCO格式。训练集通常包含训练图片集和标注好的标签集,一张图应包含一组与其对应的标签,标签内容为此图片中目标的位置信息,位置信息包括目标识别框的左上点以及宽高,一组训练集则包含多张照片和与其对应的标签。如下为daraknet框架可直接应用的训练集内容示例:
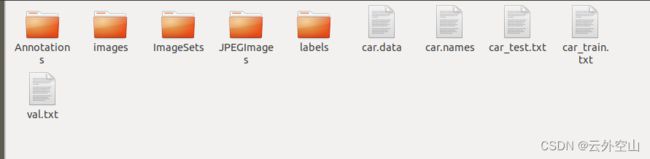
其中发挥主要作用的主要为images、labels文件夹,这两个里面分别为图片集和标签集,以及car.data、car.names、car_train.txt,其内容分别为训练数据路径和重要参数的配置文件、分类标签名称(训练和推理所使用的标签是数字代号,car.name里面所保存的是数字与名称直接的对应关系,其内0-x个存储内容分别与标签数字0-x相对应,每个标签内容以换号隔开),训练集图片路径。
car.data:
classes=1
train=/home/xiejiapeng/Project/learnning/Data/car3_img/train.txt
valid=/home/xiejiapeng/Project/learnning/Data/car3_img/test.txt
names=/home/xiejiapeng/Project/learnning/Data/car3_img/car.names
backup=backup/
car.names:当前仅包含一类“car”
car
car_train:其内容可使用绝对路径也可使用相对路径,推荐使用绝对路径,可减少路径错误的问题,如下为部分内容示例
/home/xiejiapeng/Project/learnning/Data/car3_img/images/162.jpg
/home/xiejiapeng/Project/learnning/Data/car3_img/images/75.jpg
/home/xiejiapeng/Project/learnning/Data/car3_img/images/26.jpg
/home/xiejiapeng/Project/learnning/Data/car3_img/images/32.jpg
......
此部分内容可参考Pytorch实现YOLOv3训练自己的数据集
可从上博文中学习如何使用labelImage标注VOC格式数据,以及将VOC格式训练集转换为darknet可直接使用的格式
4.训练模型
训练模型建议直接参考YOLOv3官网,无需科学上网可直接访问,内容详细可靠,以下内容也是根据官网内容总结。
(1)使用cpu训练
使用cpu训练不需要过多环境依赖,仅需要gcc环境和git支持即可,直接clone项目代码,然后编译,利用编译得到可执行文件即可完成模型训练和相关测试。
下载和编译darknet项目代码:
git clone https://github.com/pjreddie/darknet
cd darknet
make
执行测试:模型的推理测试需要提供神经网络模型、模型配置文件,和测试图片,神经网络模型与模型权重为同一内容,神经网络模型需利用网站链接进行使用wegt命令进行下载,配置文件则在darknet目录下的cfg目录中已存在
#下载已训练好的供测试的模型权重
wget https://pjreddie.com/media/files/yolov3.weights
#使用相对路径执行测试,cfg/yolov3.cfg为模型配置文件,yolov3.weights为模型权重,data/dog.jpg为测试图片
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
成功的话终端将输出如下类似内容:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
并在darknet目录下产生如下predictions.jpg文件:
测试无误则可进行模型训练。
此部分可使用按照以上内容制作好的训练集,也可使用官网或是使用Pytorch实现YOLOv3训练自己的数据集 提供的训练集进行测试,如果出现某个地方路径错误,推荐改为使用绝对路径,对于存储训练集图片路径的文件内容,可使用搜索替换批量修改相对路径为绝对路径。
在darknet中,模型训练需要训练集、模型配置文件和预训练权重,其中训练集需要根据训练内容自行准备,模型配置文件和预训练权重darknet已提供。
使用如下命令进行训练:cfg/voc.data为训练集中提到的.data文件,即为训练集的主要路径和参数的配置文件;cfg/yolov3-voc.cfg为模型配置文件,darknet已提供,darknet53.conv.74为预训练权重,需使用wegt命令或通过官网链接进行下载
#下载预训练权重
wget https://pjreddie.com/media/files/darknet53.conv.74
#执行训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
训练进行中会出现如下大概内容:
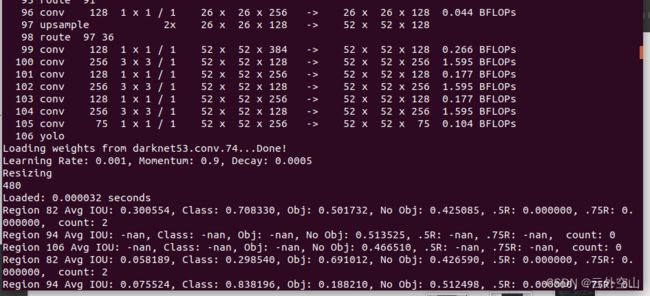
注意模型训练并不会自行停止,而是会不断迭代训练,需要用户自行判断当前训练是否达到完成要求即是否训练已收敛然后停止(在终端窗口按ctrl+c键停止),可根据如下输出内容进行判断:
8: 1284.488037, 1279.109253 avg, 0.000000 rate, 1.183489 seconds, 32 images
Loaded: 0.000038 seconds
对于训练结果含义的解释请查看Darknet训练YOLO V3输出日志log中各参数的意义
模型结果保存在darknet下的backup目录,命名方式为“模型配置文件名称_迭代次数.weight”,例如“yolov3-voc_700.weights”为使用yolov3-voc.cfg配置文件训练迭代700次得到的模型权重文件。
在darknet在默认的训练情况下在1000次之前每100次保存一次模型权重,1000之后则每10000次才保存一次模型权重,如果想对此进行修改可参考:修改darknet训练过程中保存权重文件的频率
需要修改的detector.c文件位置:darknet/examples/detector.c

修改要对darknet进行重新make编译才可生效,利用终端在darknet目录下执行make命令即可。
(2)使用gpu训练
使用gpu训练则需要依赖CUDA环境,darknet的gpu训练只限装载有英伟达显卡的设备可使用。
关于CUDA环境安装可参考:Ubuntu安装cuda
安装CUDA后需要对darknet进行gpu配置,此部分可参考:darknet_ros加速–使用GPU和CUDA
重新make编译后的训练过程的命令配置与cpu相同。