论文笔记 Communication-Efficient Learning of Deep Networks from Decentralized Data
论文题目:《Communication-Efficient Learning of Deep Networks from Decentralized Data》
时间:联邦学习由谷歌在2016年提出,2017年在本文第一次详细描述该概念
地位:联邦学习开山之作
建议有时间先学一下机器学习 o(╥﹏╥)o
如果实在是没有的话,就先了解一下这些东西吧:
非平衡、非IID、鲁棒性、监督学习(标签)、超参数、随机梯度下降SGD、模型平均
梯度下降 可以看一下这篇文章:https://blog.csdn.net/weixin_43235581/article/details/127409877
以下内容蛮详细的,尽量不要在碎片时间看哦,有什么错误劳请大佬指出!
Abstract
背景:现代移动设备可以访问大量适合学习模型的数据,这反过来可以大大改善设备上的用户体验。但是数据数量多,并对隐私敏感。
提出:将训练数据分布在移动设备上,并通过聚合本地计算的更新来学习共享模型,将这种分散的学习方法为联邦学习。
实验:五种不同的模型架构和四个数据集,广泛的经验评估。
实验表明:对非平衡和非IID数据分布(这是该设置的一个决定性特征)具有鲁棒性。
主要限制因素:通信成本。与同步随机梯度下降相比,所需的通信回合数减少了10–100倍。
Introduction
学习任务:一个由中央服务器 server协调的参与设备(我们称之为客户端 clients)组成的松散联合体来解决。
每个客户端都有一个从未上载到服务器的本地训练数据集,每个客户端计算服务器维护的当前全局模型的更新,并且仅传递此更新。
主要优点:将模型训练与直接访问原始训练数据的需要分离开来。仍然需要对协调训练的服务器有一定的信任。
主要贡献:
- 将移动设备分散数据训练问题确定为一个重要的研究方向。
- 选择可应用于此设置的简单实用算法。
- 对提出的方法进行了广泛的实证评估。
即,介绍了 FederatedAveraging 算法:将每个客户端上的本地随机梯度下降(SGD)与执行模型平均的服务器相结合。
实验证明:对不平衡和非IID数据分布具有鲁棒性,并且可以减少在分散数据上训练深层网络所需的通信次数。
联邦学习
联邦学习的数据应该有以下特性:
- 对来自移动设备的真实数据进行训练,比对数据中心中通常可用的代理数据进行训练具有明显的优势。
- 该数据属于隐私敏感数据或数据量较大(相对于模型的大小而言),因此最好不要纯粹为了模型训练而将其记录到数据中心。
- 对于监督任务,数据上的标签可以从用户交互中自然推断出来。
两个例子:
- 图像分类:预测哪些照片在未来最有可能被多次浏览或共享。
- 语言模型:改善语音识别和触摸屏键盘上的文本输入。
这两个例子的潜在训练数据可能是隐私敏感的;分布可能与代理数据集有大不同,比如说聊天的语言跟标准的语法语言差很多;数据标签是可以直接获得的。
隐私
与数据中心的持久化数据训练相比,联邦学习具有明显的隐私优势。
联邦学习传输的信息是改进特定模型所需的最小更新,更新本身可以也应该是短暂的,而且一般会比原始训练数据包含的信息少得多。
聚合算法不需要更新源,因此更新可以在不识别元数据的情况下通过Tor等混合网络或通过可信的第三方进行传输。
联邦优化
将联邦学习中隐含的优化问题称为联邦优化。
联邦优化问题的关键:(与分布式优化的对比)
- ☆Non-IID:在给定客户端上的训练数据通常基于特定用户对移动设备的使用,因此任何特定用户的本地数据集都不能代表总体分布。
- ☆不平衡:类似地,一些用户会比其他用户更频繁地使用服务或应用程序,从而导致不同的本地训练数据数量。
- 大规模分布:我们希望参与优化的客户端数量比每个客户端示例的平均数量要大得多。
- ☆通讯受限:移动设备经常脱机或连接缓慢或昂贵。
其它实际问题:
- 客户端数据集随着数据的添加和删除而更改。
- 客户端(更新)的可用性与其本地数据分布有着复杂的关系。
- 客户端从不响应或发送损坏的更新。
优化步骤:(假设有固定 K 个客户端,每个客户端有固定本地数据集)
- 每一轮随机选择 C-fraction 个客户端。 0≤C≤1,C应该指的是比例
- 服务器将当前的全局算法状态发送给每个客户端(例如,当前的模型参数)。
- 被选中的客户端根据全局状态及其本地数据集执行本地计算,向服务器发送更新。
- 服务器将这些更新应用于其全局状态。
重复以上过程。
对于凸神经网络,目标函数为:

w表示网络参数,i 表示样本索引,n表示所有数据的数量,fi(w)=L(xi,yi;w)表示每个样本的训练损失,f(w)表示聚合所有客户端数据集的全局平均损失。
假设数据分布在K个客户端, Pk表示客户端 k 的数据样本集合, nk表示Pk的数量,Fk(w)表示Pk上的平均损失。(一个客户端可能有多个样本)
则上式可以改写为:
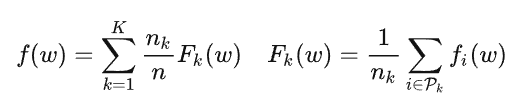
如果划分 Pk 是所有用户数据的随机取样,则目标函数 f(w) 就等价于损失函数关于 Pk 的期望:
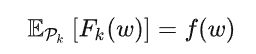
若每个用户k的数据集Pk是均匀分布的,即期望EPk[Fk(w)]=f(w),这意味着Pk符合IID独立同分布。
通信成本
数据中心优化:通信成本相对较小,计算成本占主导地位,最近的重点是使用GPUs来降低这些成本。
联邦优化:
- 通信成本大。
- 通常会受到1 MB / s或更小的上传带宽的限制。
- 客户通常只会在充电和使用wi-fi时自愿参与优化。
- 希望每个客户端每天只参与少量的更新轮。
- 计算成本小。
- 任何单个设备上的数据集与总体数据集大小相比都很小。
- 手机拥有相对较快的处理器。
因此,目标是:使用额外的计算来减少训练模型所需的通信轮数。
增加计算量的两种主要方法:
- 增加并行度,即在每一轮通信中使用更多的客户端独立工作。
- 在每个客户端上增加计算量,而不是执行像梯度计算这样的简单计算,每个客户端在每一轮通信之间执行更复杂的计算。
The FederatedAveraging Algorithm
随机梯度下降SGD
- 最近大量成功的深度学习应用几乎完全依赖于**随机梯度下降(SGD)**的变体进行优化。
- 许多进步可以理解为通过简单的基于梯度的方法使模型的结构(以及损失函数)更易于优化。
因此,构建联邦优化算法从SGD开始。
SGD可以简单地应用于联邦优化问题,因为在每轮通信中进行单个梯度计算(在随机选择的客户端上)。
优点:计算效率很高。
缺点:需要大量的训练才能产生好的模型。
FedSGD
前面提到,目标是:使用额外的计算来减少训练模型所需的通信轮数,
SGD的优点是:计算效率很高,
因此,基线baseline使用:大批量同步SGD (在数据中心中是最先进的,优于异步方法)
每一轮中选择 C-fraction 个客户端,并计算这些客户端持有的所有数据的损失函数梯度。C 控制全局批大小,C = 1对应全批(非随机)梯度下降。
将这个基线算法称为: FederatedSGD(FedSGD)
算法原理
-
被选中的客户端计算自己所有数据损失的平均梯度值

-
传给服务器,服务器进行聚合,并更新全局参数 w

FedAvg
对于FedSGD,进行优化:通过在平均步骤之前多次迭代本地更新来为每个客户端增加更多的计算量。
得到 FederatedAveraging(FedAvg):每个客户端使用其本地数据对当前模型进行梯度下降,然后服务器对结果模型进行加权平均。
算法原理
-
被选中的客户端计算自己所有数据损失的平均梯度值

-
客户端先在本地聚合多次

-
传给服务器,进行最终聚合
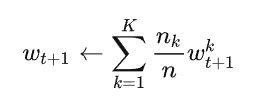
三个关键参数:
-
C:每一轮执行计算的客户端比例(只有一部分客户端参与更新)0≤C≤1
C=1 表示所有用户均参与联邦优化,C ⋅ K 表示参与用户数量,C=0 表示有且仅有1个用户均参与联邦优化
-
E:每一轮更新时,每个客户端对其本地数据集进行训练的次数 E≥1
-
B:客户端每一次更新参数时所用本地数据量大小 B≥1
B = ∞ 表示单个批量处理整个用户本地数据
FedSGD = FedAvg (B = ∞ 且 E = 1)
结论:FedAvg 相当于 FedSGD 在用户本地多次梯度更新
网上一个博主的理解:

& 图片理解来源:https://blog.csdn.net/biongbiongdou/article/details/104358321
平均模型效果
对于一般的非凸目标函数,参数空间中的平均模型可能会产生任意不好的模型结果。
按照Goodfellow等人的方法 ,当平均两个从不同初始条件训练的MNIST数字识别模型时,可以看到这种不良结果(图1,左)。
本文最近的工作表明,在实践中,充分超参数的神经网络效果良好,更不容易出现糟糕的局部极小值。
从相同的随机初始化开始两个模型,然后根据不同的数据子集对每个模型分别进行训练,发现简单的参数平均效果很好(图1,右)。这两个模型的平均值(1/2w+1/2w’)在完整MNIST训练集上获得的损耗显著低于在任何一个小数据集上单独训练得到的最佳模型。

因此:共享相同的随机种子,即采取相同的参数初始化,是个不错的主意。
原文伪代码

Experimental Results
任务:图像分类、语言建模
流程:
-
选择了一个足够小的代理数据集,以便可以彻底研究FedAvg算法的超参数。
虽然每个单独的训练运行相对较小,但为这些实验训练了超过2000个单独的模型。
-
给出基准CIFAR-10图像分类任务的结果。
-
为了证明FedAvg在客户端数据自然分区的实际问题上的有效性,对一个大型语言建模任务进行了评估。
图像分类
两个模型:
- E=1 的MNIST 2NN:一个简单的多层感知器,有2个隐藏层,每个层有200个单元,使用ReLu激活。
- E=5 的CNN:一个具有两个5x5卷积层的CNN(第一层有32个通道,第二层有64个通道,每个层后面都有2x2 max pooling),一个全连接层有512个单元和ReLu激活,最后一个softmax输出层。
两种数据划分:
- IID:其中数据被洗牌,然后划分为100个客户端,每个客户端接收600个示例。
- Non-IID:按数字标签对数据进行排序,将其划分为200个大小为300的碎片,并为100个客户端中的每个分配2个碎片。
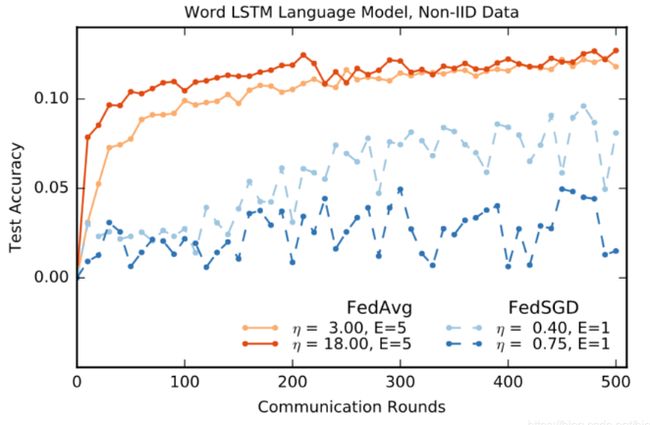
语言建模
数据集:莎士比亚全集
数据划分:为每个剧中的每个说话角色构建一个至少有两行台词的用户数据集。
训练集和测试集:对于每个客户端,将数据划分为一组训练行(针对角色的前80%行)和测试行(最后20%)。
这个数据基本上是不平衡的,许多角色只有几行,而有些角色有很多行。
测试集不是随机的样本,每个剧本按时间顺序将行分为训练集与测试集。
使用相同的训练/测试分离,还形成了数据集的平衡和IID版本。
模型:一个堆叠字符级 LSTM语言模型
任务:在读取一行中的每个字符后,预测下一个字符。
增加并行性(客户端数量)

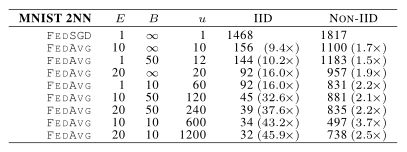
表1:C 在 E = 1的MNIST 2NN 上和 E = 5的CNN 上的影响。C = 0.0 表示每轮一个客户端。由于为MNIST数据使用了100个客户端,所以行分别对应于1、10、20、50和100个客户端。每个表条目给出了 2NN 达到97%和 CNN 达到99%的测试集准确度所需的通信轮数(比如1474),以及相对于 C = 0 基线的加速(应该是指括号里的数据 比如1.0x)。在允许的时间内,批量较大的五次运行没有达到目标精度(应该是指图中的五个—)。
表1显示了不同 C 对两种MNIST模型的影响。报告了达到目标测试集精度所需的通信轮数。
- 当 B = ∞(单个批量处理整个用户本地数据),增加客户端比例 C,只有很小的优势。
- 当 B = 10 :有显著改善,特别是在non-iid的情况下。
基于这些结果,在余下的实验中固定 C = 0.1,在计算效率和收敛速度之间达到了很好的平衡。
增加每个客户端的计算量
固定C = 0.1,并在每一轮中为每个客户端增加更多的计算:减少B、增加E、或者两者都增加。
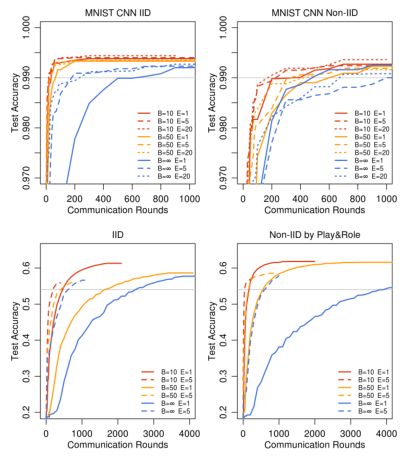
图2:MNIST CNN (IID,non-IID)和莎士比亚LSTM(IID,Play&Role)在 C = 0.1 和优化 η 下的测试集精度与通信轮数。灰线表示表2中使用的目标精度。2NN的图见附录A中的图7。

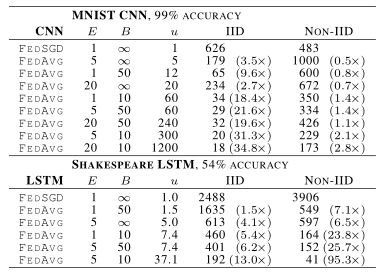
表2:与FedSGD相比,FedAvg达到目标精度的通信轮数(第一行,E = 1, B =∞)。u列给出u = En/(KB),即每轮更新的预期数量。
图2表明,每轮增加更多的本地SGD更新可以显著降低通信成本(增加E或者减小B,达到目标精度所需的通讯次数减小),表2量化了这些加速。
只要B足够大,能够充分利用客户机硬件上可用的并行性,就基本上不需要花费计算时间来降低它,因此在实践中,这应该是第一个调优的参数。
-
对于MNIST数据的IID划分,每个客户端使用更多的计算次数将达到目标精度的轮次减少,CNN减少了35×, 2NN减少了46× (2NN的详细信息见附录A中的表4)。病理分区的non-iid数据的加速较小,但仍然很可观(2.8 - 3.7×)。
当用完全不同的数字对训练出来的模型参数进行平均时,平均可以提供任何优势(实际上是偏离)。因此,我们认为这是该方法稳健性的有力证据。
-
莎士比亚的不平衡和non-iid分布(根据戏剧中的角色)更能代表在现实应用中所期望的那种数据分布。令人鼓舞的是,对于这个问题,学习non-IID和不平衡数据实际上要容易得多(95×加速比平衡IID数据的13×加速)推测这很大程度上是因为一些角色有相对较大的局部数据集,这使得增加的局部训练特别有价值。
-
对于所有三个模型类,FedAvg比基准FedSGD模型收敛到更高水平的测试集精度。这一趋势会持续下去,即使这些线超出了标绘范围。
推测除了降低通信成本之外,模型平均还产生了类似于dropout所获得的正则化收益。
-
主要关注泛化性能,但FedAvg在优化训练损失方面也很有效,甚至超过了测试集精度稳定的点。观察到所有三个模型类的相似行为,并在附录A的图6中给出MNIST CNN的图。

能不能客户端”一直“优化下去?
(这一部分不是很懂,就翻译了一下而已)
当前的模型参数仅通过初始化影响在每个ClientUpdate中执行的优化。因此,当E→∞时,至少对于凸问题,最终初始条件应该是无关的,并且无论初始化与否都会达到全局最小值。即使对于一个非凸问题,人们可能会猜想算法只要初始化在同一盆地,就会收敛到相同的局部最小值。也就是说,虽然一轮平均可能产生一个合理的模型,但额外的几轮通信(和平均)不会产生进一步的改进。
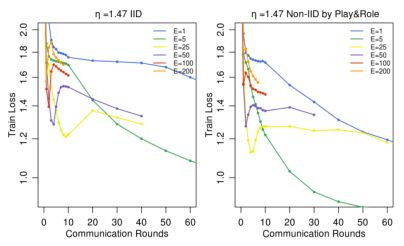
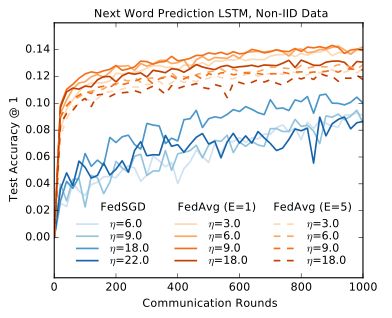
图3:在平均步骤之间训练许多地方时(大E)的效果,固定B = 10和C = 0.1的莎士比亚LSTM与固定的学习速率η = 1.47。
图3显示了初始训练中大E对莎士比亚LSTM问题的影响。事实上,对于非常多的局部时期,FedAvg可以趋于稳定或发散。这一结果表明,对于某些模型,特别是在收敛的后期阶段,以同样的方式衰减学习速率可能有用的方式衰减每轮的局部计算量(向较小的E或较大的B移动)可能是有用的。附录A中的图8给出了MNIST CNN的类似实验。有趣的是,在这个模型中,没有看到大值E的收敛速度有明显的下降。然而,看到在下面描述的大规模语言建模任务中,E = 1比E = 5的性能稍好一些(见附录A中的图10)。

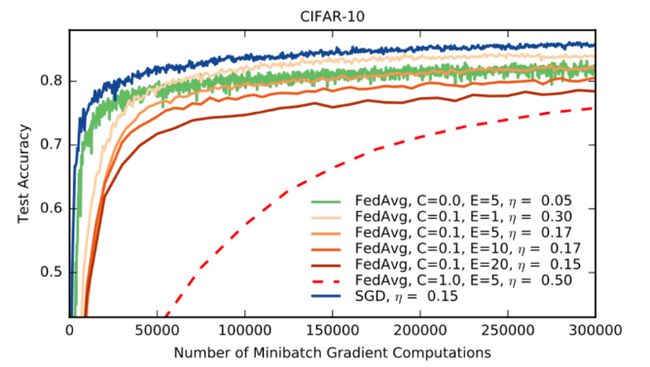
CIFAR实验
目标:进一步验证 FedAvg
数据集:CIFAR-10数据集,由10类 32x32 图像组成,有3个RGB通道。有50,000个训练示例和10,000个测试示例。
数据划分:划分为100个客户端,每个客户端包含500个训练示例和100个测试示例。
模型:取自TensorFlow教程,该教程包括两个卷积层,然后是两个完全连接的层,然后是一个产生logits的线性转换层,总共大约有106个。

表3:在CIFAR10上达到目标测试集精度,基线SGD、FedSGD和 FedAvg 的通信轮数。SGD使用的小批量为100。FedSGD 和 FedAvg采用 C = 0.1, FedAvg 采用 E = 5, B = 50。

图4:CIFAR10实验的测试精度与通信,FedAvg与FedSGD的学习率曲线。FedSGD 每轮的学习率衰减为0.9934。FedAvg 使用B = 50,每轮学习率衰减0.99,E = 5。
其它:通过对 SGD 和 FedAvg 进行 B=50 的小批量实验,可以将精度视为此类小批量梯度计算次数的函数。希望SGD做得更好,因为在每个小批量计算之后都会采取一个顺序步骤。然而,如附录中的图9所示,对于适当的C和E值,FedAvg 在每个小批量计算中取得的进展量相似。此外,每轮只有一个客户的标准SGD和FedAvg(C=0)在准确性上都表现出显著的波动,而多个客户的平均值可以消除这种波动。
大型规模LSTM实验
数据集:一个大型社交网络的1000万条公开帖子。按作者对帖子进行分组,总共有50多万客户。此数据集是现实中用户移动设备上文本输入的代理数据。将每个客户数据集限制为最多5000个单词,并在来自不同作者的1e5篇文章的测试集上测试准确性。
模型:基于10,000个单词的词汇表的256个节点LSTM。每个词的输入和输出嵌入维数为192,并与模型进行协同训练。总共有4950544个参数。用了10个单词展开。
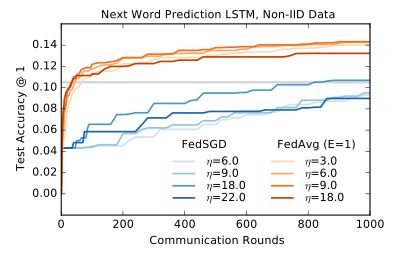
图5:大规模语言模型词LSTM的单调学习曲线
每轮都在200个客户端上进行训练。FedAvg采用B = 8, E = 1。
图5显示了最佳学习率的单调学习曲线。η = 18.0 的 FedSGD 需要820轮才能达到10.5%的准确度,而 η = 9.0 的 FedAvg 仅在35轮通信达到10.5%的准确度(比FedSGD少23倍)。观察到 FedAvg 在测试准确性方面的方差较小,见附录a中的图10。该图还包括E = 5的结果,它的表现略差于E = 1。
Conclusions and Future Work
各种模型架构(一个多层感知器,两种不同的卷积神经网络,一个两层字符LSTM、一个大规模词级LSTM)的实验结果表明:联邦学习是切实可行的,因为FedAvg可以用相对较少的通信轮数来训练高质量的模型。
未来工作的一个有趣方向:差异隐私、安全多方计算或它们的组合。这两类隐私保护技术自然地适用于FedAvg之类的同步算法。