视觉SLAM十四讲——ch7










视觉SLAM十四讲——ch7
ch7视觉里程计
本章目标:
1.理解图像特征点的意义,并掌握在单副图像中提取出特征点及多副图像中匹配特征点的方法
2.理解对极几何的原理,利用对极几何的约束,恢复出图像之间的摄像机的三维运动
3.理解PNP问题,以及利用已知三维结构与图像的对应关系求解摄像机的三维运动
4.理解ICP问题,以及利用点云的匹配关系求解摄像机的三维运动
5.理解如何通过三角化获得二维图像上对应点的三维结构
本章目的:基于特征点法的vo,将介绍什么是特征点,如何提取和匹配特征点,以及如何根据配对的特征点估计运动和场景结构,从而实现两帧间视觉里程计。
1 特征点
角点、SIFT(尺度不变特征变换)、SURF、ORB(后三者为人为设计,具有更多优点)。
1.1 特征点的组成
1 关键点:指特征点在图像里的位置
2 描述子:通常是一个向量,按照某种人为设计的方式,描述了该关键点周围像素的信息。相似的特征应该有相似的描述子(即当两个特征点的描述子在向量空间上的距离相近,认为这两个特征点是一样的)。
1.2 ORB特征
ORB特征:OrientedFAST关键点+BRIEF描述子。提取ORB特征的步骤:
1 .2.1提取FAST角点:
找出图中的角点,计算特征点的主方向,为后续BRIEF描述子增加了旋转不变特性。(FAST角点主要检测局部像素灰度变化明显的地方)。它的检测过程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C6zkqAV4-1647311685760)(视觉SLAM十四讲——ch7.assets/14d5abad89ab841faeebd7534c42e42-16462760426531.png)]
特点:速度快
缺点: 1).FAST特征点数量很大且不确定,但是我们希望对图像提取固定数量的特征
2).FAST角点不具有方向信息,并且存在尺度问题
解决方式:1).指定要提取的角点数量N,对原始FAST角点分别计算Harris响应值,然后选取前N个具有最大响应值的角点作为最终的角点集合
2).添加尺度和旋转的描述
尺度不变性的实现:构建图像金字塔,并在金字塔的每一层上检测角点(金字塔:指对图像进行不同层次的降采样,以获得不同分辨率的图像)
特征旋转的实现:灰度质心法(质心:指以图像块灰度值作为权重的中心)
1.2.2.计算BRIEF描述子
对前一步提取出的特征点周围图像区域进行扫描
特点:使用随机选点的比较,速度非常快,由于使用了二进制表达,存储起来也十分方便,适用于实时的图像匹配。
在不同图像之间进行特征匹配的方法:
1.暴力匹配:浮点类型的描述子,使用欧式距离度量
二进制类型的描述子(比如本例中的BRIEF描述子),使用汉明距离度量
缺点:当特征点数量很大时,暴力匹配法的运算量会变得很大
2.快速近似最近邻(FLANN):适合匹配特征点数量极多的情况。
1.2.3 图像特征提取代码详解
#include1.2.4 结果分析
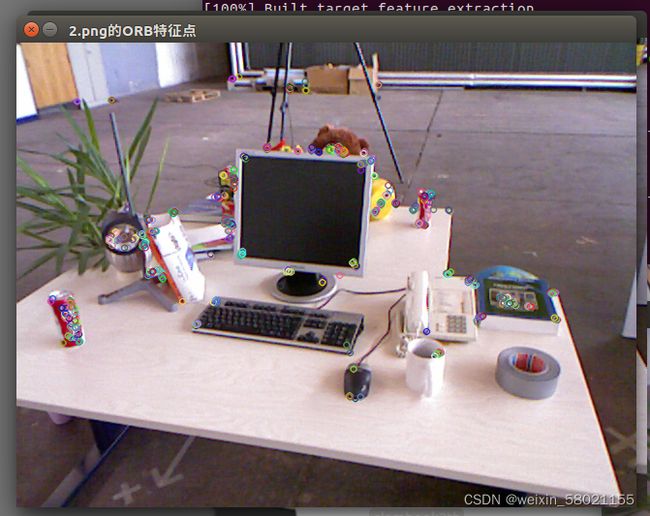
图片1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UecP7jPi-1647311685761)(视觉SLAM十四讲——ch7.assets/1372381-20180727153341182-1525732735-16462766616633.png)]
图片2
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gR0Rrr8H-1647311685762)(视觉SLAM十四讲——ch7.assets/1372381-20180727153414203-226154175-16462766676635.png)]
暴力匹配:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V4DLqjl6-1647311685762)(视觉SLAM十四讲——ch7.assets/1372381-20180727153506919-387915385-16462767832818.png)]
设置30为下限的经验值匹配:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-370Tx8F1-1647311685762)(视觉SLAM十四讲——ch7.assets/1372381-20180727153635299-359755985-16462767875569.png)]
结果分析:筛选的依据是汉明距离小于最小距离的两倍,这是工程经验方法,但还是有误匹配,所以后面在估计运动时,需要去除误匹配的算法。
2 2D-2D :对极几何约束
从两张图片中得到一对匹配好的特征点,如果有若干对这样的匹配点,就可以通过二维图像对应的点,计算出两帧之间相机的运动(R、t)。
2.1单目相机——对极几何求解
如果是单目相机:只能得到2D的像素坐标->根据两组2D点估计运动,方法:对极几何
步骤如下: 1).根据配对点的像素位置求出本质矩阵E或基础矩阵F
2).根据E或F求出R,t。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y4DJKzn0-1647311685763)(视觉SLAM十四讲——ch7.assets/c1407a05f0d0e6a9ed05d717a2ab762-164627824431811-164627824612812.png)]
2.1.1本质矩阵E:
1).E在不同尺度下是等价的
2).本质矩阵的内在性质:E的奇异值一定是[σ,σ,0]T的形式
3).由于尺度等价性,E实际上有5个自由度。
求解方法:八点法(Eight-point -algorithm)。求出E后,对其分解->R,t
2.1.2 单应矩阵(Homograohy)H:
描述了两个平面之间的映射关系。如果场景中的特征点都落在同一个平面上(墙、地面等),可通过单应性来估计运动
求解方法:直接线性变换法(Direct Linear Transform)。求出H后,对其分解(分解方法:数值法、解析法)->R,t
2.2 对极约束求解相机运动代码详解
#include2.3 结果分析
-- Max dist : 95.000000
-- Min dist : 4.000000
一共找到了79组匹配点
fundamental_matrix is
[4.844484382466111e-06, 0.0001222601840188731, -0.01786737827487386;
-0.0001174326832719333, 2.122888800459598e-05, -0.01775877156212593;
0.01799658210895528, 0.008143605989020664, 1]
essential_matrix is
[-0.02036185505234771, -0.4007110038118444, -0.033240742498241;
0.3939270778216368, -0.03506401846698084, 0.5857110303721015;
-0.006788487241438231, -0.5815434272915687, -0.01438258684486259]
homography_matrix is
[0.9497129583105288, -0.143556453147626, 31.20121878625771;
0.04154536627445031, 0.9715568969832015, 5.306887618807696;
-2.81813676978796e-05, 4.353702039810921e-05, 1]
R is
[0.9985961798781877, -0.05169917220143662, 0.01152671359827862;
0.05139607508976053, 0.9983603445075083, 0.02520051547522452;
-0.01281065954813537, -0.02457271064688494, 0.9996159607036126]
t is
[-0.8220841067933339;
-0.0326974270640541;
0.5684264241053518]
t^R=
[-0.02879601157010514, -0.5666909361828475, -0.0470095088643642;
0.5570970160413605, -0.04958801046730488, 0.8283204827837457;
-0.009600370724838811, -0.8224266019846685, -0.02034004937801358]
epipolar constraint = [0.002528128704106514]
epipolar constraint = [-0.001663727901710814]
epipolar constraint = [-0.0008009088410885212]
epipolar constraint = [0.0001705869410470254]
epipolar constraint = [-0.0003338015008984979]
epipolar constraint = [0.0003385525272308065]
epipolar constraint = [0.0001729349818584552]
epipolar constraint = [-9.552408320477601e-06]
epipolar constraint = [-0.0008834408754688165]
epipolar constraint = [-0.000444586092781381]
epipolar constraint = [-0.000156067923593961]
epipolar constraint = [0.001512967129777068]
epipolar constraint = [-0.0002644334828964742]
epipolar constraint = [-3.514414351252562e-06]
epipolar constraint = [-0.0004170632811044614]
epipolar constraint = [-0.0007749589896892117]
epipolar constraint = [0.002091463454860276]
epipolar constraint = [-0.001016195254389909]
epipolar constraint = [0.0005870797511206075]
epipolar constraint = [0.0002701337927295891]
epipolar constraint = [-0.0008153290073634545]
epipolar constraint = [0.005595329855570208]
epipolar constraint = [0.004456949384590653]
epipolar constraint = [-0.00109225844630996]
epipolar constraint = [-0.00122027527435923]
epipolar constraint = [0.0001206258081121597]
epipolar constraint = [-0.0007167735646266809]
epipolar constraint = [0.002034045481378033]
epipolar constraint = [-0.001256283161205782]
epipolar constraint = [-2.841028832301085e-06]
epipolar constraint = [-0.0009452266349239957]
epipolar constraint = [-0.0003143393086872948]
epipolar constraint = [-0.003421410506807192]
epipolar constraint = [0.0006511227496003788]
epipolar constraint = [-0.001310996225762057]
epipolar constraint = [-0.0001590978941137114]
epipolar constraint = [-0.002209031974010213]
epipolar constraint = [-0.0007840664639768846]
epipolar constraint = [-0.00219092181574767]
epipolar constraint = [0.002922765516590181]
epipolar constraint = [-0.0002852488690396338]
epipolar constraint = [0.001288650990044271]
epipolar constraint = [0.002981122529430141]
epipolar constraint = [0.001104024767925333]
epipolar constraint = [0.0005839797440089639]
epipolar constraint = [-0.002811645087152688]
epipolar constraint = [-0.001723388366795087]
epipolar constraint = [0.0001541481260837613]
epipolar constraint = [0.0006004071491191379]
epipolar constraint = [-0.001728591166312573]
epipolar constraint = [-0.0007782250239872224]
epipolar constraint = [-0.001075058873840032]
epipolar constraint = [0.004654782908027483]
epipolar constraint = [-0.00145774661621554]
epipolar constraint = [0.0003259585394422768]
epipolar constraint = [-9.139514634399354e-06]
epipolar constraint = [2.094089762112034e-06]
epipolar constraint = [-0.00122725042555329]
epipolar constraint = [-0.0008551935807612487]
epipolar constraint = [0.001650773210968584]
epipolar constraint = [0.00116044245491314]
epipolar constraint = [0.001879717958470126]
epipolar constraint = [-5.97742462742773e-06]
epipolar constraint = [-0.0003369336336238871]
epipolar constraint = [0.004360922097753794]
epipolar constraint = [-0.005310637569393865]
epipolar constraint = [-0.0006060103678098214]
epipolar constraint = [1.216121374464363e-06]
epipolar constraint = [-0.003401336870289186]
epipolar constraint = [0.002238878760289525]
epipolar constraint = [0.001475291883444502]
epipolar constraint = [-0.003206338609952966]
epipolar constraint = [-0.001462525388296471]
epipolar constraint = [-0.0007503932332671159]
epipolar constraint = [0.00384724837206624]
epipolar constraint = [6.646617176919722e-07]
epipolar constraint = [0.0007123827789497824]
epipolar constraint = [-0.0005911111586385312]
epipolar constraint = [-0.004921591124588801]
结果分析:其中求出来的本质矩阵和通过E=t^R的出来的结果有差异,对极约束中精度在0.001,
2.4 单目相机的不足
2.4.1 尺度不确定性
单目视觉slam:尺度不确定性。即对轨迹和地图缩放任意倍数,得到的图像依然是一样的
固定尺度的做法:1.对两张图像的t归一化
2.令所有的特征点平均深度为1(相比较而言,特征点深度归一化可控制场景的规模大小,使得计算在数值上更稳定)
2.4.2 初始化的旋转问题
单目初始化不能只有纯旋转,必须要有一定程度的平移,才可进行单目的初始化.
2.4.3 对于多8点的情况
对于本质矩阵E中的元素构建最小二乘法,通过优化方法来求解R和t,但当存在误匹配的情况下,不适用。更加倾向于随机采样一致性(RANSAC)
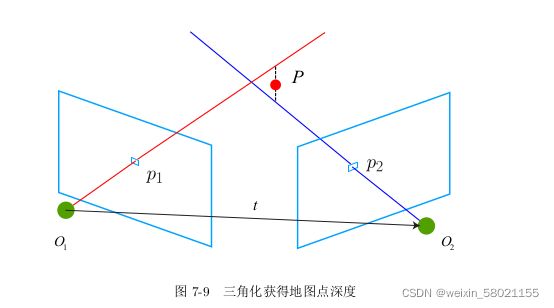
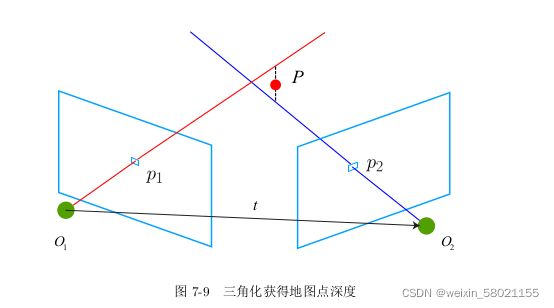
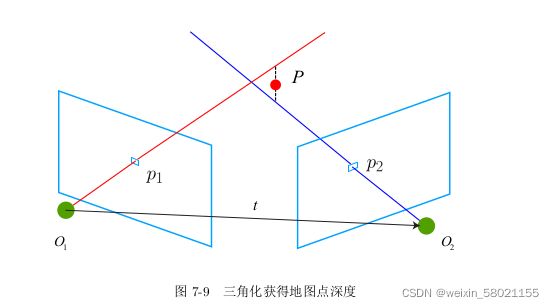
3 三角测量
通过ORB特征匹配,进行图片之间的关联,得到特征点之间的关系,在通过对极约束
x 2 T E x 1 = 0 x^T_2Ex_1=0 x2TEx1=0
计算本质矩阵E,在将E分解为R和t,即可得到相机的运动,下一步需要使用相机的运动来估计特征点的空间位置。即估计地图点的深度。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cMaD82e8-1647311685763)(视觉SLAM十四讲——ch7.assets/838f7c5485b6efb0b861be20951997a-16463096450793-16463096465574.png)]
三角测量:通过对不同位置对同一个路标点进行观测,从观测位置推断路标点的距离,按照对极几何定义,设 x 1 , x 2 x_1,x_2 x1,x2为两个特征点的的归一化坐标,满足
s 2 x 2 = s 1 R x 1 + t s_2x_2=s_1Rx_1+t s2x2=s1Rx1+t
对上式两侧左乘 x 2 x_2 x2的反对称矩阵,就可以求得 s 1 s_1 s1。
3.1代码详解
#include
//计算本质矩阵
Point2d principal_point(325.1, 249.7); //相机光心,//把内参K中的cx ,cy放进一个向量里面 =相机的光心
double focal_length = 521; // 相机焦距
//之所以取上面的principal_point、focal_length是因为计算本质矩阵的函数要用
//得到本质矩阵essential_matrix
Mat essential_matrix;
essential_matrix = findEssentialMat(points1,points2,focal_length,principal_point,RANSAC);
cout<<"essential matrix" <<essential_matrix<<endl;
//计算单应矩阵
//Mat homography_matrix;
//homography_matrix = findHomography(points1,points2,RANSAC,3);
//cout<<"homography matrix" <
//从本质矩阵中恢复旋转和平移信息
//此函数仅在opencv3中提供
recoverPose(essential_matrix,points1,points2,R,t,focal_length,principal_point);
cout<< "R is"<< R << endl;
cout<< "t is"<< t << endl;
}
void triangulation(
const vector<KeyPoint> &keypoint_1,
const vector<KeyPoint> &keypoint_2,
const std::vector<DMatch> &matches,
const Mat &R, const Mat &t,
vector<Point3d> &points){
Mat T1 = (Mat_<float>(3,4)<<//定义图1在世界坐标系下的位姿
1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0);
Mat T2 = (Mat_<float>(3,4) <<
R.at<double>(0, 0), R.at<double>(0, 1), R.at<double>(0, 2), t.at<double>(0, 0),
R.at<double>(1, 0), R.at<double>(1, 1), R.at<double>(1, 2), t.at<double>(1, 0),
R.at<double>(2, 0), R.at<double>(2, 1), R.at<double>(2, 2), t.at<double>(2, 0)
);
Mat K = (Mat_<double>(3, 3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1);
//容器 pts_1、pts_2分别存放图1和图2中特征点对应的自己相机归一化坐标中的 x与 y
vector<Point2f> pts_1, pts_2;
for (DMatch m:matches) {//这样的遍历写起来比较快
// 将像素坐标变为相机下的归一化坐标
pts_1.push_back(pixel2cam(keypoint_1[m.queryIdx].pt, K));
pts_2.push_back(pixel2cam(keypoint_2[m.trainIdx].pt, K));
}
Mat pts_4d;
cv::triangulatePoints(T1,T2,pts_1,pts_2,pts_4d);
//转换成非齐次坐标
for (int i = 0; i < pts_4d.cols; i++)
{
//定义x来接收每一个三维点
Mat x = pts_4d.col(i);
x/=x.at<float>(3,0);//归一化
Point3d p(x.at<float>(0,0), x.at<float>(1,0), x.at<float>(2,0));
points.push_back(p);
}
}
3.2 结果分析
-- Max dist : 95.000000
-- Min dist : 4.000000
一共找到了79组匹配点
essential matrix[-0.02036185505234771, -0.4007110038118444, -0.033240742498241;
0.3939270778216368, -0.03506401846698084, 0.5857110303721015;
-0.006788487241438231, -0.5815434272915687, -0.01438258684486259]
R is[0.9985961798781877, -0.05169917220143662, 0.01152671359827862;
0.05139607508976053, 0.9983603445075083, 0.02520051547522452;
-0.01281065954813537, -0.02457271064688494, 0.9996159607036126]
t is[-0.8220841067933339;
-0.0326974270640541;
0.5684264241053518]
depth: 45.3724
depth: 16.6993
depth: 14.046
depth: 13.267
depth: 13.6788
depth: 30.0102
depth: 14.6864
depth: 13.8394
depth: 14.408
depth: 15.118
depth: 17.1833
depth: 16.2955
depth: 14.4425
depth: 15.5032
depth: 16.6199
depth: 29.6163
depth: 29.8479
depth: 14.2034
depth: 17.2911
depth: 13.952
depth: 14.7138
depth: 51.8393
depth: 50.3779
depth: 15.2634
depth: 15.1423
depth: 13.5731
depth: 15.2204
depth: 17.2002
depth: 15.1018
depth: 13.1856
depth: 28.1319
depth: 27.8687
depth: 14.8212
depth: 16.2624
depth: 13.3843
depth: 14.8062
depth: 14.6493
depth: 16.8406
depth: 14.6166
depth: 44.9113
depth: 28.6374
depth: 28.7027
depth: 46.6309
depth: 15.6839
depth: 14.9472
depth: 14.5156
depth: 14.0974
depth: 13.5684
depth: 19.3896
depth: 17.501
depth: 29.7291
depth: 15.5625
depth: 53.3157
depth: 16.3022
depth: 12.9899
depth: 17.7342
depth: 18.2738
depth: 17.8923
depth: 16.5829
depth: 15.7578
depth: 17.9717
depth: 18.049
depth: 14.3796
depth: 10.4467
depth: 11.2243
depth: 13.9109
depth: 16.0181
depth: 22.9477
depth: 15.9597
depth: 10.2454
depth: 9.95815
depth: 16.3941
depth: 14.9895
depth: 18.6442
depth: 18.0098
depth: 11.627
depth: 16.2583
depth: 13.4797
depth: 17.2989
结果分析:
纯旋转无法使用三角测量,因为对极约束会永远满足。提高三角化精度的方法:
1.提高特征点的提取精度,即提高图像分辨率。缺点:会导致图像变大,增加计算成本。
2.使平移量增大(平移较大时,在同样的相机分辨率下,三角化测量会更精确)。
缺点:导致图像的外观会发生明显变化,使得特征提取和匹配变得困难。
三角测量的矛盾:增大平移量->匹配失效;平移太小->三角化精度不够。
4 3D-2D: PnP
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当我们知道n个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。
在双目或 RGB-D 的视觉里程计中,我们可以直接使用 PnP 估计相机运动。而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。
优点:3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。
PnP 问题有很多种求解方法,直接线性变换(DLT)、EPnP(Efficient PnP),UPnP[47] 。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,即Bundle Adjustment。
1).DLT(Direct Linear Transform)
2).P3P
输入数据:3对3D-2D匹配点。记3D点为A,B,C。2D点为a,b,c。小写字母对应的点为对应大写字母代表的点在相应的成像平面上的 投影
注意:A,B,C表示的是在世界坐标系中的坐标,而不是在相机坐标系中的坐标。如果一旦能算出3D点在相机坐标系下的坐标,就能得到3D-3D的对应点,从而把PnP问题转化为ICP问题。
缺点:1.P3P只利用3个点的信息,当给定的配对点多于3组时,难以利用更多的信息。
2.如果2D点或3D点受噪声的影响,或存在误匹配,则算法失效
3).EPnP、UPnP等
相较于P3P来说,优点:1.利用更过的信息
2.用迭代的方式对相机的位姿进行优化,尽可能消除噪声的影响
缺点:原理更复杂
通常的做法:先使用P3P/EPnP等方法估计相机位姿,然后构建最小二乘优化问题对估计值进行调整(Bundle Adjustment)
线性方法:先求相机位姿,再求空间位置
非线性优化:把相机位姿和空间位置均看作优化变量,放在一起优化
4).Bundle Adjustment
两个重要的公式见P164(公式7.45)和P165(公式7.47)-分别描述了观测相机方程关于相机位姿与特征点的两个导数矩阵。能够在优化过程中(优化位姿和优化特征点的空间位置)提供重要的梯度方向,指导优化的迭代。
4.1 实验代码如下:
首先用OpenCV提供的EPnP求解PnP问题,然后通过g2o对结果进行优化
第一步:使用EPnP求解位姿
//created by 2022/3/4
#include 4.2 结果分析
一共用了三种求解方式。第一种,调用cv的函数pnp求解 R ,t;第二种,手写高斯牛顿进行位姿优化;第三种,利用g2o进行位姿优化。
三种方式中的R与前面对极几何求出来的R都相差不大,但t相差许多,通过添加深度信息提高了准确性。代码方面的用时都是小于1ms,但其中通过g2o可以添加多张图片进去。(具体结果自己运行代码查看)
其中关于g2o的知识可以查看文档《g2o的原理》在这个里面进行了讲解。
5 3D-3D:ICP
对于一组匹配好的3D点可以用迭代最近点(ICP)进行求解R,t。主要用两种解法,线性代数求解(SVD)、非线性优化。
线性代数求解(SVD):通过构建图片之间的误差项,构建最小二乘法,求使误差平方和达到极小的R和t。
非线性优化:构建误差的最小二乘法,对误差项求一次导数得到雅可比矩阵,通过高斯牛顿法优化法进行求解。
5.1 代码详解
//
// Created by nnz on 2020/11/5.
//
#include detector = FeatureDetector::create ( "ORB" );
// Ptr descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create("BruteForce-Hamming");
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect(img_1, keypoints_1);
detector->detect(img_2, keypoints_2);
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute(img_1, keypoints_1, descriptors_1);
descriptor->compute(img_2, keypoints_2, descriptors_2);
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<DMatch> match;
// BFMatcher matcher ( NORM_HAMMING );
matcher->match(descriptors_1, descriptors_2, match);
//-- 第四步:匹配点对筛选
double min_dist = 10000, max_dist = 0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for (int i = 0; i < descriptors_1.rows; i++) {
double dist = match[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist);
printf("-- Min dist : %f \n", min_dist);
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for (int i = 0; i < descriptors_1.rows; i++) {
if (match[i].distance <= max(2 * min_dist, 30.0)) {
matches.push_back(match[i]);
}
}
}
//实现像素坐标到相机坐标的转换(求出来的只是包含相机坐标下的x,y的二维点)
Point2d pixel2cam(const Point2d &p, const Mat &K) {
return Point2d
(
(p.x - K.at<double>(0, 2)) / K.at<double>(0, 0),
(p.y - K.at<double>(1, 2)) / K.at<double>(1, 1)
);
}
//参考书上的p197页
void pose_estimation_3d3d(
const vector<Point3f> &pts1,
const vector<Point3f> &pts2,
Mat &R, Mat &t
)
{
int N=pts1.size();//匹配的3d点个数
Point3f p1,p2;//质心
for(int i=0;i<N;i++)
{
p1+=pts1[i];
p2+=pts2[i];
}
p1 = Point3f(Vec3f(p1)/N);//得到质心
p2 = Point3f(Vec3f(p2) / N);
vector<Point3f> q1(N),q2(N);
for(int i=0;i<N;i++)
{
//去质心
q1[i]=pts1[i]-p1;
q2[i]=pts2[i]-p2;
}
//计算 W+=q1*q2^T(求和)
Eigen::Matrix3d W=Eigen::Matrix3d::Zero();//初始化
for(int i=0;i<N;i++)
{
W+= Eigen::Vector3d (q1[i].x,q1[i].y,q1[i].z)*(Eigen::Vector3d (q2[i].x,q2[i].y,q2[i].z).transpose());
}
cout<<"W = "<<endl<<W<<endl;
//利用svd分解 W=U*sigema*V
Eigen::JacobiSVD<Eigen::Matrix3d> svd(W,Eigen::ComputeFullU | Eigen::ComputeFullV);
Eigen::Matrix3d U=svd.matrixU();//得到U矩阵
Eigen::Matrix3d V=svd.matrixV();//得到V矩阵
cout << "U=" << U << endl;
cout << "V=" << V << endl;
Eigen::Matrix3d R_=U*(V.transpose());
if (R_.determinant() < 0)//若旋转矩阵R_的行列式<0 则取负号
{
R_ = -R_;
}
Eigen::Vector3d t_=Eigen::Vector3d (p1.x,p1.y,p1.z)-R_*Eigen::Vector3d (p2.x,p2.y,p2.z);//得到平移向量
//把 Eigen形式的 r 和 t_ 转换为CV 中的Mat格式
R = (Mat_<double>(3, 3) <<
R_(0, 0), R_(0, 1), R_(0, 2),
R_(1, 0), R_(1, 1), R_(1, 2),
R_(2, 0), R_(2, 1), R_(2, 2)
);
t = (Mat_<double>(3, 1) << t_(0, 0), t_(1, 0), t_(2, 0));
}
//对于用g2o来进行优化的话,首先要定义顶点和边的模板
//顶点,也就是咱们要优化的pose 用李代数表示它 6维
class Vertexpose: public g2o::BaseVertex<6,Sophus::SE3d>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;//必须写,我也不知道为什么
//重载setToOriginImpl函数 这个应该就是把刚开的待优化的pose放进去
virtual void setToOriginImpl() override
{
_estimate = Sophus::SE3d();
}
//重载oplusImpl函数,用来更新pose(待优化的系数)
virtual void oplusImpl(const double *update) override
{
Eigen::Matrix<double,6,1> update_eigen;//更新的量,就是增量呗,dx
update_eigen << update[0], update[1], update[2], update[3], update[4], update[5];
_estimate=Sophus::SE3d::exp(update_eigen)* _estimate;//更新pose 李代数要转换为李群,这样才可以左乘
}
//存盘 读盘 :留空
virtual bool read(istream &in) override {}
virtual bool write(ostream &out) const override {}
};
//定义边
class EdgeProjectXYZRGBD: public g2o::BaseUnaryEdge<3,Eigen::Vector3d,Vertexpose>
{
public:
EdgeProjectXYZRGBD(const Eigen::Vector3d &point) : _point(point) {}//赋值这个是图1坐标下的3d点
//计算误差
virtual void computeError() override
{
const Vertexpose *v=static_cast<const Vertexpose *>(_vertices[0]);//顶点v
_error = _measurement - v->estimate() * _point;
}
//计算雅克比
virtual void linearizeOplus() override
{
const Vertexpose *v=static_cast<const Vertexpose *>(_vertices[0]);//顶点v
Sophus::SE3d T=v->estimate();//把顶点的待优化系数拿出来
Eigen::Vector3d xyz_trans=T*_point;//变换到图2下的坐标点
//下面的雅克比没看懂
_jacobianOplusXi.block<3, 3>(0, 0) = -Eigen::Matrix3d::Identity();
_jacobianOplusXi.block<3, 3>(0, 3) = Sophus::SO3d::hat(xyz_trans);
}
bool read(istream &in) {}
bool write(ostream &out) const {}
protected:
Eigen::Vector3d _point;
};
//利用g2o
void bundleAdjustment(const vector<Point3f> &pts1,
const vector<Point3f> &pts2,
Mat &R, Mat &t)
{
// 构建图优化,先设定g2o
typedef g2o::BlockSolver<g2o::BlockSolverTraits<6, 3>> BlockSolverType; // 优化系数pose is 6, 数据点 landmark is 3
typedef g2o::LinearSolverDense<BlockSolverType::PoseMatrixType> LinearSolverType; // 线性求解器类型
// 梯度下降方法,可以从GN, LM, DogLeg 中选
auto solver = new g2o::OptimizationAlgorithmGaussNewton(
g2o::make_unique<BlockSolverType>
(g2o::make_unique<LinearSolverType>()));//把设定的类型都放进求解器
g2o::SparseOptimizer optimizer; // 图模型
optimizer.setAlgorithm(solver); // 设置求解器 算法g-n
optimizer.setVerbose(true); // 打开调试输出
//加入顶点
Vertexpose *v=new Vertexpose();
v->setEstimate(Sophus::SE3d());
v->setId(0);
optimizer.addVertex(v);
//加入边
int index=1;
for(size_t i=0;i<pts1.size();i++)
{
EdgeProjectXYZRGBD *edge = new EdgeProjectXYZRGBD(Eigen::Vector3d(pts1[i].x,pts1[i].y,pts1[i].z));
edge->setId(index);//边的编号
edge->setVertex(0,v);//设置顶点 顶点编号
edge->setMeasurement(Eigen::Vector3d(pts2[i].x,pts2[i].y,pts2[i].z));
edge->setInformation(Eigen::Matrix3d::Identity());//set信息矩阵为单位矩阵
optimizer.addEdge(edge);//加入边
index++;
}
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
optimizer.initializeOptimization();//开始
optimizer.optimize(10);//迭代次数
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "optimization costs time: " << time_used.count() << " seconds." << endl;
cout << endl << "after optimization:" << endl;
cout << "T=\n" << v->estimate().matrix() << endl;
// 把位姿转换为Mat类型
Eigen::Matrix3d R_ = v->estimate().rotationMatrix();
Eigen::Vector3d t_ = v->estimate().translation();
R = (Mat_<double>(3, 3) <<
R_(0, 0), R_(0, 1), R_(0, 2),
R_(1, 0), R_(1, 1), R_(1, 2),
R_(2, 0), R_(2, 1), R_(2, 2)
);
t = (Mat_<double>(3, 1) << t_(0, 0), t_(1, 0), t_(2, 0));
}
6 总结
第七章看书理解加手敲代码花费了8天左右,其中手敲代码是最花费时间但又必不可少的一部分,在一些函数,参数不懂时,可以直接查看该参数的定义。第二部分就是安装软件加cmake,由于使用的十四讲第二版的代码其中的g2o(最新版)就只能运行第二版代码,第一版无法运行,还有一些cmake相关的问题,查阅资料花费许多时间。第三部分就是对于这部分公式的推导和代码的理解,第七章中用到了第三章中的旋转向量转旋转矩阵,第四章的李群与李代数,重点是左扰动更新模型,第五章中的相机模型,归一化坐标大量用到,需要弄懂空间坐标系到相机坐标系,空间坐标系到像素坐标系及相机坐标系到像素坐标系的关系(这部分很重要)。而第六部分就比较晦涩难懂,要着重理解最小二乘法在优化方面的含义,对于优化方面,需要看懂高斯牛顿法和列文伯格法,还有g2o原理不复杂,只是在运用方面有许多要求。
结束于2022/3/5 20:30
bug
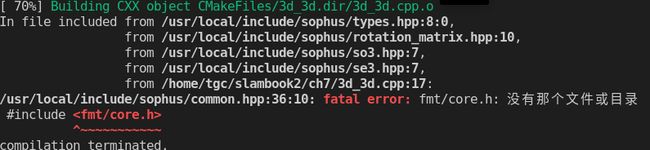
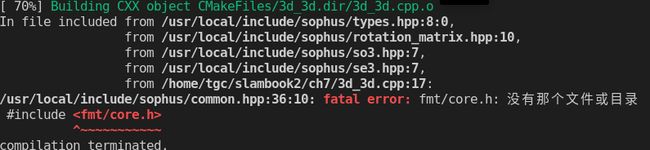
1.#include
./usr/local/include/sophus/common.hpp:36:10: fatal error: fmt/core.h: 没有那个文件或目录**
#include
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0U6MdjE6-1647311685764)(视觉SLAM十四讲——ch7.assets/482a27b3355eba79de8a9c1616235d5-16464838018401.png)]
解决方案:需要在cmakelists中添加类似于第五行和第12行的代码,将其中的3d_2d改为自己的可执行文件名。
add_executable(3d_2d 3d_2d.cpp)
target_link_libraries(3d_2d
g2o_core g2o_stuff
${OpenCV_LIBS})
target_link_libraries(3d_2d Sophus::Sophus)
add_executable(3d_3d 3d_3d.cpp)
target_link_libraries(3d_3d
g2o_core g2o_stuff
${OpenCV_LIBS})
target_link_libraries(3d_3d Sophus::Sophus)