cs231n_2018_lecture09_notes_知名CNN结构分析
这一讲的ppt内容相当之大,主要介绍了几个较为出名的CNN结构。在其他人所作的再整理中也就都是非常简单地介绍了这几个网络,实际上想要深入理解还是需要找出以原paper读读,然后再针对单个网络搜搜看看别人的理解。此处也仅简单概括几个案例,作为后续的学习方向。
LeNet-5
简单的5层网络,常用于字母识别,结构:input->conv->pool->conv->pool->conv->fc->fc(output)。各层的解释和计算可以看这里。
AlexNet:

简单的8层网络,在ILSVRC2012上获胜,正确率相较之前比赛没有采用CNN时提升了近10个百分点,宣布了CNN的火爆开始。输入是227*227*3的图像,经过第一层11*11*96的卷积层,得到尺寸的宽高为(227-11+2*0)/4+1=55的输出空间(即55*55*96),这个计算公在“cs231n_神经网络笔记_部分总结工作2”提及过了,需要注意的是这个计算非常的重要,因为在网络设计的过程中是需要时刻关注着维度信息的,必须保证维度统一可实现矩阵计算,保证最终的计算维度结果的形式是我们想要的表达形式,比如N*1*1。第一层中参数有11*11*3*96=35K,参数的计算必要性是需要考量到内存的问题。
AlexNet的特别:1.第一次使用了ReLU层;2.训练时使用了norm层;3.训练时大量使用了data augmentation;4.训练时dropout率设为0.5;5.训练时batchsize设为128;6.训练时使用SGD+Momentum的优化,Momentum超参数设为0.9;6.训练时学习率初始为1e-2,当验证集准确率曲线平滑就降低10倍;7.训练时L2权重衰减weight decay设为5e-4。
ILSVRC2013的冠军时ZFNet,它是基于AlexNet的,不同的是它将第一层的11*11(S=4)调整为小卷积核7*7(S=2),而后将cnv3、conv4、conv5的384、384、256个卷积核替换为512、1024、512。
VGG:
VGG有VGG-16、VGG-19,在2014提出,是定位冠军、分类亚军,采用了更小的卷积核、更深的网络,实践结果表明这样子的处理是非常有效的。它使用了3个3*3的卷积核来代替ZFNet的1个7*7,可以证明出这种代替是可行的,它们的效果一致,而且使用更小的卷积核可以使得网络更加得深、更加的非线性(=更好的表达),而且待学习参数数目从C*7*7*C减少到了C*3*3*C(C是通道数),然而这种替换可能会带来GPU的内存瓶颈,所以可能需要做出妥协继续使用7*7,当然尽可能使用更小的卷积核!计算可得到内存消耗在前向传播过程中约96MB,总共参数有138M,较多内存消耗在了前面的卷积层中,大多的参数量集中在后面的全连接层了。
VGG的特别:1.更小的卷积核;2.没有LRN(local response normalisation)层;3.开始表现在其他任务上适用性良好。
相比AlexNet个人感觉最大的进步在于证明了使用更小的卷积核是更优的。
GoogleNet:
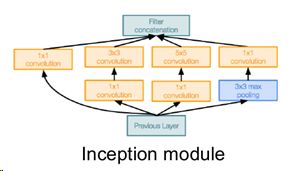
GoogleNet有22层,在2014提出是分类冠军,它设计引入了“Inceotion module”(需要重点理解!),使得网络更高效,且放弃了网络末端多个繁杂的全连接层(仅留下最后用于输出的fc),因此参数量相比大大减少。在“Inceotion module”中开始使用1*1卷积核(“bottlenect layers”很关键,越来越常见)降低depth维度,使得ops(=operations=时间复杂度?)大大减少。另外,它还引入了"auxiliary classification outputs",由avgpool->1*1conv->fc-fc->softmax构成。
GoogleNet的特别:1.使用高效的Inception module;2.使用1*1conv做维度调整减少参数量;3.使用auxiliary classification outputs;4.抛弃了多余的fc层。更深的网络,更少的参数!
相比VGG个人感觉最大的进步在于使用inception突破了每层卷积只用一种尺寸的卷积核以及引入了bottlenect减少参数量。
RestNet:
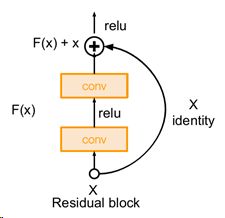
ResNet在2015正式提出,有34、50、101、152层这几个不同的版本,设计采用了"Residual Block"(需要重点理解!),它将神经网络的深度带入到一个新的纪元,拥有152层,在ImageNet上的分类正确率首次超过了人类的正确率,夺得了ILSVRC2015和COCO2015的classification和detection冠军,表明了该网络结构的普适性。它也是首次证实了更深的网络结果的确不该是更糟,从56layer没有导致过拟合但仍然劣于20layer提出了假设,更深的网络表现糟糕的原因是更深的网络更难优化,那么问题就转化为更深的网络要同时改变结构而不是简单地堆叠层数,因此设计出了"Residual Block"。
ResNet的特别:1.使用并堆叠“Residual Block”;2.每个"Residual Block"是由两个3*3conv组成;3.抛弃了多余的fc层;4.在网络多于50层时使用了1*1conv(“bottlenect layers”);5.训练时在每个卷积层后使用了BatchNorm;6.训练时没有使用dropout;7.训练时Min-batchsize设为256;7.训练时使用SGD+Momentum的优化,Momentum超参数设为0.9;8.训练时学习率初始为1e-1,当验证集准确率曲线停滞就降低10倍;9.训练时权重衰减weight decay设为1e-5。
相比AlexNet个人感觉最大的进步在于证明了更深的网络是可行的并使用residual通过skip connection的思路解决了深度网络带来的梯度消散问题。
解决梯度消散的关键:网络中有很多skip connection跨层连接结构,其中的shortcut机制可以无损地传播梯度(梯度为1),因为有1的存在基本不会导致梯度的消失。
网络比较:
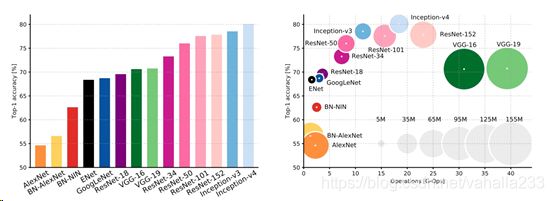
正确率 和 消耗
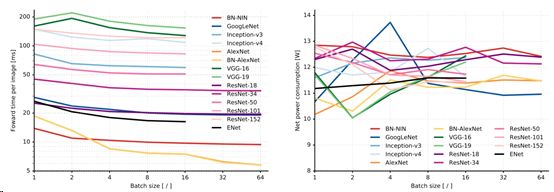
前向传播时间 和 损耗
其他网络:
2014 NiN(network in network):思路是使用micronetwork计算出更抽象的局部特征,使用了mlp,启发了googlenet和resnet的bottlenect layers。
自从2015ResNet网络的提出,使得从浅层进入到了深层网络,即成为了新的巅峰,后续很对对它的研究和改进。2016 Identity Mappings in Deep Residual Networks 对ResNet中的resdual blocks做出了改进; 2016 Wide Residual Networks提出重要的是residuals而非网络深度,提升宽度而非深度; 2016 Aggregated Residual Transformations for Deep Neural Networks (ResNeXt) 使用了类似于inception module的并行模式提升宽度; 2016 Deep Networks with Stochastic Depth 主要针对了训练模式; 2016 Good Practices for Deep Feature Fusion 集成了inception 、inception-resnet、 resnet、 wide-resnet模型,获得了ILSVRC2016分类冠军; 2017 Squeeze-and-Excitation Networks (SENet) 使用了ResNeXt作为基础加入了“feature recalibration module”,获得了ILSVRC2017分类冠军。
当然也有对ResNet持怀疑的,2017 FractalNet: Ultra-Deep Neural Networks without Residuals 提出residual不是将浅层网络带入到深层网络的关键,采用drop out sub-paths的方式训练;2017 Densely Connected Convolutional Networks 为解决深层网络带来的梯度消失问题强调特征的传播鼓励特征的再利用,它的网络层结构看上去是交错连接的。
随着对网络实际使用的需求(!准确,轻量!),高效的压缩模型随之提出,2017 SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size 设计了"squeeze layer"和"expand layer",在保证准确率的前提下将模型压缩得非常小!
强化学习的理念也影响了发展,2016 Neural Architecture Search with Reinforcement Learning (NAS) 提出了“ controller ”,开始了Meta-learning:Learning to learn network architectures;2017Learning Transferable Architectures for Scalable Image Recognition 是在NAS基础上为降低损耗设计了搜索空间(a search space of building blocks (“cells”))。
感觉基本都是在拓深或拓网络的同时围绕着复杂度再做优化,对时间/空间复杂度的分析可以看这里,相关计算在前文。
对CNN的总结与思考可以看这里(强力推荐!)。
总结:
1.VGG\GoogleNet\ResNet都是目前很好的网络,应用广泛,在各个framwork的model zoos也能轻松找到;
2.ResNet从准确率和消耗等各方面来说是目前的优选,当然如果可以SENet可能更好;
3.趋势是深层网络,研究围绕design of layer / skip connections and improving gradient flow;
4.争论围绕在对于网络是depth还是width&residual connections更重要;
5.先进的研究趋势是meta-learning;
6.优化的对象有训练过程、网络结构;