机器学习基础——分类算法之决策树、随机森林、Titanic乘客生存分类
目录
1 认识决策树
1.1 信息增益、信息熵的计算
1.2 举例计算编辑
1.3 决策树的分类依据
1.4 sklearn决策树API
2 泰坦尼克号乘客生存分类
2.1 案例背景
2.2 数据描述
2.3 步骤分析
2.4 代码实现
2.4.1 调入包
2.4.1 数据处理
2.4.2 估计器流程
2.4.3 导出决策树的结构
3 决策树的优缺点及改进
4 集成学习方法——随机森林
4.1 集成学习方法
4.2 随机森林
4.3 随机森林建立多个决策树过程
4.4 随机森林API
4.5 随机森林进行预测(超参数调优)
4.6 随机森林的优点
1 认识决策树
1.1 信息增益、信息熵的计算


1.2 举例计算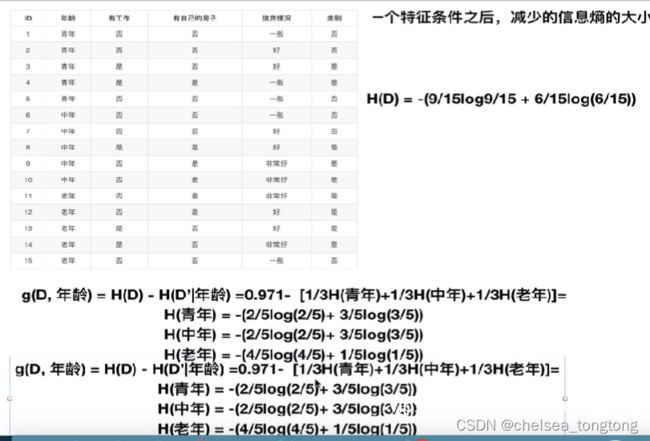
1.3 决策树的分类依据
-
ID3 信息增益 最大的准则
-
C4.5 信息增益比最大的准则
- CART 回归树:平方误差最小 分类树:基尼系数 在sklearn中可以选择可以划分的默认原则
1.4 sklearn决策树API

2 泰坦尼克号乘客生存分类
2.1 案例背景
kaggkle决策树案例:泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
数据来源:https://www.kaggle.com/c/titanic

2.2 数据描述
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
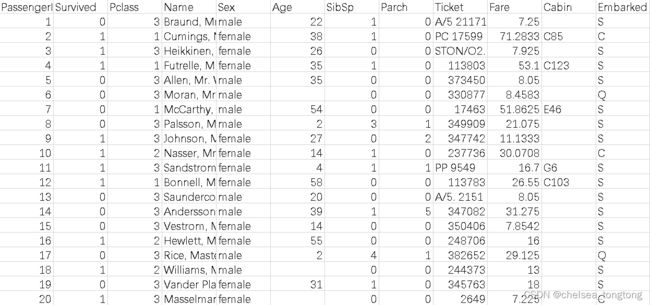
经过观察数据得到:
- 1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
- 2 其中age数据存在缺失。
2.3 步骤分析
- 1.获取数据 pd读取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值 选择有影响的特征[年龄]、[阶级]、[性别]
- 2.2 缺失值处理 fillna()
- 2.3 数据集划分
- 3.特征工程(字典特征抽取) pd转化字典,特征抽取
- 4.机器学习 决策树估计器流程
- 5.模型评估
2.4 代码实现
2.4.1 调入包
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer#转换成one_hot代码
from sklearn.tree import DecisionTreeClassifier,export_graphviz#决策树、导出决策树2.4.1 数据处理
- DictVectorizer(sparse=False) 字典特征抽取返回one_hot编码
具体的做法看字典特征提取DictVectorizer(特征工程之特征提取)
- x_test.to_dict(orient="records") 可以pandas DataFrame转换为词典列表,其中1个词典代表1行
ef decision():
"""
决策树对于泰坦尼克号进行预测生死
:return:None
"""
#获取数据
titan=pd.read_csv("C:\\Users\\zoutong\\Desktop\\programming\data\\machine learning\\train.csv")
#处理数据,找出特征值和目标值
x=titan[["Pclass","Age","Sex"]]
y=titan["Survived"]
# 缺失值处理
x["Age"].fillna(x["Age"].mean(), inplace=True)
#分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.25)
#进行处理(特征工程) 特征->类别->one_hot代码
dict=DictVectorizer(sparse=False)#DictVectorizer(sparse=False)会返回一个one-hot编码矩阵
x_train=dict.fit_transform(x_train.to_dict(orient="records"))#pandas DataFrame转换为词典列表,其中1个词典代表1行
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train) 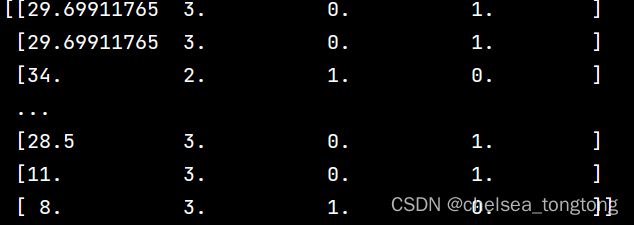
这个是转换成one_hot代码的数据
2.4.2 估计器流程
#用决策树进行分类
dec=DecisionTreeClassifier()
dec.fit(x_train,y_train)
#预测准确率
print("预测的准确率:",dec.score(x_test,y_test))
预测的准确率: 0.8116591928251121
2.4.3 导出决策树的结构
安装graphiviz教程:Win / Mac安装Graphviz - 哔哩哔哩

#导出决策树的结构
export_graphviz(dec,out_file="./decision tree.dot",feature_names=["年龄","pclass","男性","女性"])Dot文档中的内容:
digraph Tree {
node [shape=box, fontname="helvetica"] ;
edge [fontname="helvetica"] ;
0 [label="女性 <= 0.5\ngini = 0.476\nsamples = 668\nvalue = [407, 261]"] ;
1 [label="pclass <= 2.5\ngini = 0.389\nsamples = 242\nvalue = [64, 178]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="年龄 <= 2.5\ngini = 0.103\nsamples = 128\nvalue = [7, 121]"] ;
1 -> 2 ;
3 [label="pclass <= 1.5\ngini = 0.5\nsamples = 2\nvalue = [1, 1]"] ;
2 -> 3 ;
4 [label="gini = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
3 -> 4 ;
5 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
3 -> 5 ;
6 [label="年龄 <= 37.0\ngini = 0.091\nsamples = 126\nvalue = [6, 120]"] ;
2 -> 6 ;
7 [label="pclass <= 1.5\ngini = 0.044\nsamples = 88\nvalue = [2, 86]"] ;
6 -> 7 ;
8 [label="gini = 0.0\nsamples = 44\nvalue = [0, 44]"] ;
7 -> 8 ;
9 [label="年龄 <= 26.5\ngini = 0.087\nsamples = 44\nvalue = [2, 42]"] ;
7 -> 9 ;
10 [label="年龄 <= 25.5\ngini = 0.165\nsamples = 22\nvalue = [2, 20]"] ;
9 -> 10 ;
11 [label="年龄 <= 23.0\ngini = 0.091\nsamples = 21\nvalue = [1, 20]"] ;
10 -> 11 ;
12 [label="gini = 0.0\nsamples = 14\nvalue = [0, 14]"] ;
11 -> 12 ;
13 [label="年龄 <= 24.5\ngini = 0.245\nsamples = 7\nvalue = [1, 6]"] ;
11 -> 13 ;Dot转化为PNG:
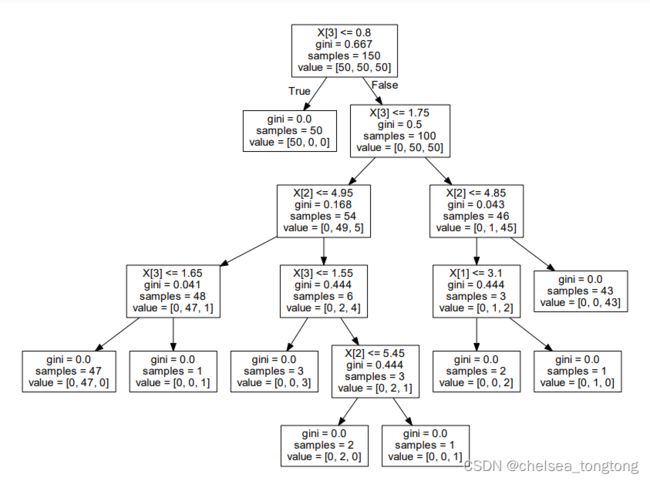
3 决策树的优缺点及改进
- 优点:
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合。
- 改进:
- 减枝cart算法
- 随机森林(集成学习的一种)
- 注:企业重要决策,由于决策树有很好的分析能力,在决策过程应用较多。
4 集成学习方法——随机森林
4.1 集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。他的工作原理是生成多个分类器/模型,各自独立的学习和做出预测。这些预测最后结合成但预测,因此优于任何一个单分类的做出预测。
4.2 随机森林
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。比如4个决策树结果是T,1个决策树结果是F,那么随机森林结果是T.

4.3 随机森林建立多个决策树过程
N个样本,M个特征
单个树建立过程:
- 随机在N个样本当中选择一个样本,重复N次 样本有可能重复
- 随机在M个特征当中选出m个特征 m取值
- 建立10棵决策树,样本、特征大多不一样 随机有放回的抽样bootstrap
- 为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
- 为什么要有放回抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同,都是没有交集的,这样每棵树都是“有偏”的,都是绝对”片面的”,也就是说每棵树训练出来的都是有很大的差异的;而随机森林最后分类取决于多棵树(弱2分类器)的投票表决。
4.4 随机森林API

- n_estimator决策树的数量
- max_depth每棵树的深度限制
4.5 随机森林进行预测(超参数调优)
rf=RandomForestClassifier()
param={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
#网格搜索与交叉验证
gc=GridSearchCV(rf,param_grid=param,cv=2)
gc.fit(x_train,y_train)
print("准确率:",gc.score(x_test,y_test))
print("查看选择的参数模型:",gc.best_params_) 准确率: 0.8071748878923767
查看选择的参数模型: {'max_depth': 5, 'n_estimators': 300}
4.6 随机森林的优点
- 在当前所有算法中,有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估割让给特征在分类问题上的重要性
缺点基本上很少,有以下两点
- 有一点就是要给定参数,参数选取很重要
- 还有一点就是训练集特征提取