【论文笔记】CycleGAN(基于PyTorch框架)
CycleGAN(基于PyTorch框架)
- 0.论文简介
-
- 0.1本文主要的工作
- 0.2引言
- 0.3方法
- 1.代码结构
-
- 1.1根目录中的文件
-
- 1.1.1 train.py文件
- 1.1.2 test.py文件
- 1.2根目录中的文件夹
-
- 1.2.1 docs文件夹
- 1.2.2 .git文件夹
- 1.2.3 data文件夹
-
- 1.2.3.1 template_dataset.py
- 1.2.3.2 __init__.py
- 1.2.3.3 base_dataset.py
- 1.2.3.4 image_folder.py
- 1.2.3.5 aligned_dataset.py
- 1.2.3.6 unaligned_dataset.py
- 1.2.3.7 single_dataset.py
- 1.2.3.8 colorization_dataset.py
- 1.2.4 imgs文件夹
- 1.2.5 models文件夹
-
- 1.2.5.1 __init__.py
- 1.2.5.2 base_model.py
- 1.2.5.3 template_model.py
- 1.2.5.4 network.py
- 1.2.5.5 cycle_gan_model.py
- 1.2.5.6 pix2pix_model.py
- 1.2.5.7 colorazation_model.py
- 1.2.5.8 test_model.py
- 1.2.6 option文件夹
- 1.2.7 scripts文件夹
- 1.2.8 util文件夹
- 2.复现过程
-
- 2.1 准备过程
- 2.2 训练过程
- 2.3 测试过程
0.论文简介
CycleGAN是一款实现风格迁移的模型,其论文可以在各大平台找到。我们在aixiv上可以找到:https://arxiv.org/pdf/1703.10593.pdf。
我们复现的的代码是来自下面这个github仓库:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix。
虽然看起来很简单,不过对于刚入门的新手来说难度还真不低,下面让我们来仔细看看代码的结构。
0.1本文主要的工作
- 在训练集缺失的情况下,将图片从某一种风格转移到另一种风格。希望学习到一种映射规则G,使得G(X)=Y。
- 希望找到G的可逆变换F使得F(G(X))=X。
- 本文进行了很多任务方面的尝试,并和之前的方法作对比。
0.2引言
- 整体步骤概述:捕获风格1的图像特征,在没有训练集提示的情况下将其转化为风格2的特征。
- 研究背景:获取不同风格的成对数据存在一定的困难。
- 具体实施:虽无法获取图像级别的监督(缺乏有标注的图像对),但可获取集合级别的监督(X和Y中各有一组图像,我们不知道X中的某张图对应Y中的哪张图,但我们可以知道X和Y这两个集合是彼此对应的)。经过训练,使得y ̂=G(X)与y无法区分,也就是使得y ̂和y的分布尽可能一致。
- 遇到的问题:第一是无法确定哪一个才是有意义的配对(可能会有很多组映射G),第二是独立地去优化对抗损失是一件很困难的事(配对程序会将所有输入的映射图像都转换成同一个输出图像)。
- 解决措施:添加循环一致性损失,把F(G(X))与x、G(F(Y))与y的损失也都加到对抗网络的损失里。
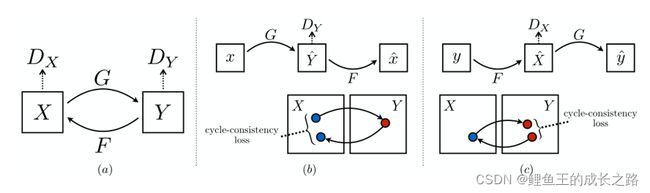
0.3方法
- 整体损失项:损失函数一共是4个部分,其中有两个是对抗损失,两个是循环一致性损失。四项分别是:(1)D_Y:用于衡量y ̂=G(x)与y的损失;(2)D_X:用于衡量x ̂=F(y)与x的损失;(3)F(G(x))与x之间的损失;(4)G(F(y))与y的损失。
- 对抗损失:基本公式如下。
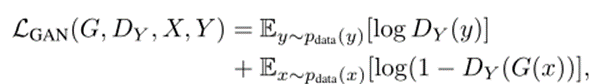
优化思想是:

- 循环一致性损失。基本公式如下:
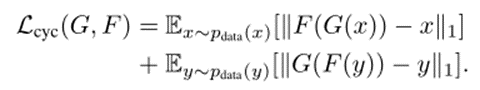
- 总损失函数
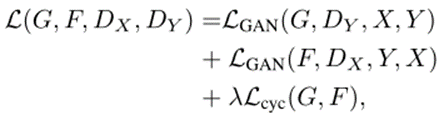
优化目标是
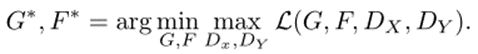
1.代码结构
1.1根目录中的文件
我们将目光聚集到根目录这个位置。
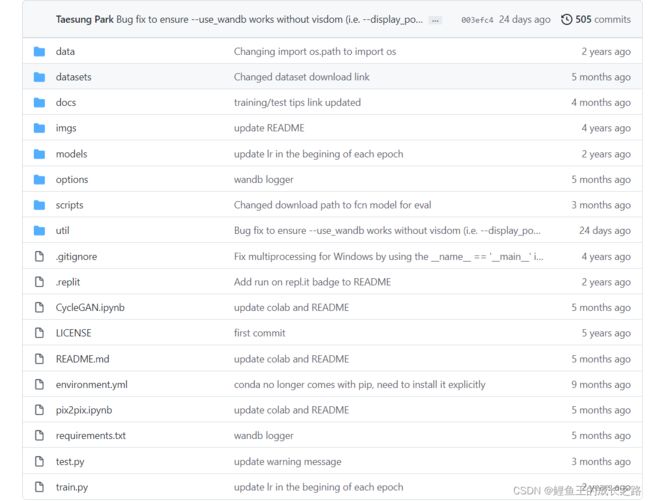
这里面,我们先来看根目录下的文件:
- README.md就是说明书。
- requirements.txt是说明这样的一个仓库所需要的各种包的版本。
- .gitignore文件是那些上传的时候要忽略的东西(不是所有的数据都需要被commit到仓库里,有时候可能只需要交源码)。
- LICENSE文件是许可证文件,会告知我们有什么样的权限(比如这个项目的代码我们可以下载并在本地中修改,但是不能修改远程仓库的内容)。
- .replit文件提供了所使用的信息,便于在浏览器中运行代码,这样一来就无需在本地配置环境。这是在使用云编辑器repl.it的时候可能会用到的设置。
- environment.yml这个文件相当于Python+requirement.txt,我们可以直接使用
conda env create -f environment.yml来创建一个environment.yml文件里指定的环境(里头什么样的包、环境名是什么、Python版本是多少)。当然,如果你现在就有这样的一个环境,想要导出这个环境所对应的environment.yml,只需要下面的命令就可以conda env export | grep -v "^prefix: " > environment.yml。 - train.py是用于训练的主脚本,可以指定使用什么样的数据集和模型。我们使用–model选项可以指定使用什么样的模型(例如:pix2pix, cyclegan, colorization),通过–dataset_mode指定数据模式(例如:aligned, unaligned, single, colorization),通过–dataroot指定数据集路径,通过–name指定实验名称。这里可以列举一个命令供参考
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan。 - test.py是用于测试的主脚本,通过–checkpoints_dir可以设置模型读取的路径,通过–results_dir可以设置结果的保存路径,通过–dataroot可以设置数据集的路径,通过–name可以设置任务名称,通过–model设置所采用的模型。对于CycleGAN双向检验,可以利用命令
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan来实现,其中的–model cycle_gan会将数据导入的模式变为双向。对于CycleGAN的单项检验,可以利用命令python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout来实现。–no_dropout指的是不需要dropout;–model test指的是单向验证CycleGAN模型,这将使得–dataset_mode自动变成single,也就是导入单一集合的数据。 - CycleGAN.ipynb和pix2pix.ipynb里头是两个模型的运行教程(在jupyter notebook)。
1.1.1 train.py文件
21-25行不说了,都是导入一些基本的类。
第27行的意思是,如果这个脚本作为主脚本使用,那么就运行下方的东西。28行是先把TrainOption实例化成对象,然后用parse进行解析,这样形成一个结果,赋给opt,也就是说,opt解析出来的结果。29行是根据这个结果去创建数据集。30行获取数据集中样本的数量。31行不说了。
33行是创建模型。34行是根据opt创建合适的学习率调整策略、导入网络并打印。第35行是根据opt创建可视化实例。36行是训练迭代次数。
第38行是迭代过程的开始,opt.epoch_count是从哪个epoch开始,opt.n_epochs_decay是持续多少epoch。39-40行不说了,获取这个epoch开始的时间和本轮epoch导入数据的时间。41行是在本轮epoch当中的第几次迭代。42行是可视化机器的重置,保证在每个epoch里它至少有一次保存图片。43行是在每次epoch之前率先更新一下学习率。
第44行就是每个epoch内部的循环了,enumerate函数的作用是同时列出数据和下标,这个无需多说,注意这里的i是batch的编号,而data也不是一张图,而是一个batch的图。45行是本次iteration开始的时间。46-47行是说如果总迭代次数total_iters到了opt.print_freq的整倍数,就计算t_data,也就是本轮iteration开始的时刻到本轮epoch导入数据的时间已经过去了多久。49-50行指的是,一共多少个数据参与了训练以及本轮epoch里有多少数据参与了迭代。51行是把每一个数据解包,52行是参数优化,这些都是在model当中的basemodel.py当中定义的。
54-57行是数据可视化的部分,如果本轮epoch当中已经参与迭代的样本总数是opt.display_freq的整数倍,那么执行55-57行的操作。55行是返回一个叫save_result的布尔值,用于判定是否需要存出结果到html文件里。第56行是只有在着色任务中才有用,是展示图片的命令,其他的模型中compute_visuals函数只有一个命令,那就是pass。第57行则是存储到html文件里的命令,其中save_result就决定本行是否执行,可以参见util文件夹里的visualizer.py。
59-64行是打印的部分。如果本轮epoch当中已经参与迭代的样本总数是opt.print_freq的整数倍,那么执行60-64行的操作。第60行是获取当前的损失函数。第61行是计算每个图片所用的时间。第62行是输出当前的损失值,后面的参数含义大家可以点击util文件夹下的visuallizer.py去查看相应的函数。63-64行是损失值可视化的部分,如果window id of the web display这个值大于0,那么就利用plot_current_losses函数输出,参数的含义可以点击util文件夹下的visuallizer.py去查看相应的函数。
66-69行是保存权重文件的部分,如果本轮epoch当中已经参与迭代的样本总数是opt.save_latest_freq的整数倍,那么执行67-69行的操作。67行不说了,68行是设置保存后缀,69行是保存模型。
71行是重新获取时间。72-75行也是在保存模型,不过这次是在每个epoch结束的时候。
77行是输出,无需多言。
1.1.2 test.py文件
它将从’–checkpoints_dir’加载保存的模型,并将结果保存到’–results_dir’。它首先在给定opt选项的情况下创建模型和数据集。它将硬编码一些参数。然后,它对“–num_test”图像运行推断,并将结果保存到HTML文件中。
29-34行不用多说了,导入包。
36-39行是导入wandb包,可以帮我们记录超参数指标。
42-43行不说了,和上面的train.py有异曲同工之妙。45行,测试模式仅能使用单线程,至于哪一个线程,你可以去自己指定;46行,batch_size只能为1;47行是确定数据需不需要打乱;48行则是是否翻转;49行是放弃展示图片;50-52行不说了,上面的train.py里解释过是什么含义。
54-57行,没太看懂。不太熟悉wandb这个包的含义。
59-行,是在创建网站。60行是在确定地址。61-62行是要根据本轮迭代来确定网址的域名(整体)。63行不说了,就是打印一下结果。64行是确定网页的地址和标题(这块可能得在util文件夹里头找html.py)。68-69行是评估模式开启。
70-72行比较简单,不再重复。73-74行也比较容易理解,分别是解包数据、测试。75-78行可以参考注释,获取图像结果、获取图像路径,每隔5个图片打印一次。79行是保存图片到html中,参数的含义可以点击util文件夹下的visuallizer.py去查看相应的函数。最后80行,保存html。
1.2根目录中的文件夹
之后,我们再来看看各个文件夹都是怎么回事。
1.2.1 docs文件夹
docs文件夹不多说了,里头是各种说明文档。
1.2.2 .git文件夹
.git文件夹也不多说了,这是用于分布式版本管理的工具,具体什么是git请自行百度。在我【教程搬运】的专栏下也有专门介绍git的博文。
1.2.3 data文件夹
data文件夹,里头是各种和数据加载、处理的模块。里头的__init__.py是一个接口文件,basedataset.py是一个基础文件(包含一些常见的转换功能,有点相当于公用的“基类”,不知道怎么描述了),template_dataset.py这是一个模板,相当于示例文件。其它的都是具体的数据集对应的文件了。
1.2.3.1 template_dataset.py
首先让我们聚焦一个模板文件,也就是template_dataset.py,在这里我们仅仅给出一些说明,读完之后觉得抽象也没关系,我们后面还有例子(1.2.3.2节之后),慢慢体会,慢慢读就可以了。
这个文件主要起到一个模板的作用,是一个参考,具体说明如下:
- 这个脚本可以被当做一个模板,被用于创建新的数据类型。如果说此时此刻的我们想建立一个新的数据类型dummy,就需要在这个根目录底下创建一个名叫dummy_dataset.py的文件,里面需要定义一个类,名叫DummyDataset,而这个类需要继承父类BaseDataset(当然这个类就在data文件夹中的base_dataset.py之中),在类DummyDataset这里面需要实现四个重要的功能,我们将在后面仔细分析。
- 创建完之后如何使用呢?可以通过–dataset_mode template来指定,但需要注意,你所创建的类名class TemplateDataset、在–data_mode后面所指定的template、文件名template_dataset.py这三者都要保持一致,在实际应用中把template换为你自己的数据集名。具体的命名规范在template_dataset.py这个脚本前面有表述。
好了,刚刚我们已经说明了这个模板函数的作用,下面让我们详细地说一下要实现的是个具体功能:
- __len__函数,用于统计数据集里有多少数据,这无需多言,里面需要传入一个self参数,这显然是实例化之后的对象。返回值一般是len(self.A_path),括号内的内容是访问self的路径属性。
- modify_commandline_options函数,用于添加针对这个数据集特定的选项,这个脚本里头只是一个样例。
- __getitem__函数,这个函数将用来获取数据点,最后要返回的是数据和数据的路径,{‘data_A’: data_A, ‘data_B’: data_B, ‘path’: path},一切信息就都包含在这样一个字典里头。
- __init__函数,注意到它需要传入两个参数,一个是self,另一个是opt,前者就是将类进行实例化出来的对象,不用管;后者是我们添加的选项,在options里头文件夹里头有一些BaseOption,我们的opt必须是其中的子集。然后先得继承一下BaseDataset.__init__这个方法,之后在此处要获取数据集的路径,并且还要对输入数据进行一定的预处理。
为了便于大家理解__init__函数,我列举了single_dataset.py这个脚本里的内容进行举例。
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
# 调用BaseDataset.__init__方法,将创建好的对象self和你在训练命令里的opt传入。
BaseDataset.__init__(self, opt)
# 用opt.dataroot解析出数据路径,opt.max_dataset_size解析出最大允许数据集大小。
# make_dataset函数是用来制作数据集,返回值是一个图片组成的列表。
# 最后使用sorted函数对图片进行一下排序。
self.A_paths = sorted(make_dataset(opt.dataroot, opt.max_dataset_size))
# 这是对输入进行处理的部分。
input_nc = self.opt.output_nc if self.opt.direction == 'BtoA' else self.opt.input_nc
self.transform = get_transform(opt, grayscale=(input_nc == 1))
读完上面我写的,你可能一头雾水,没事,我们马上就利用示例来分析。
1.2.3.2 init.py
这个脚本主要是提供接口。里头分成两部分,第一部分有三个函数,第二部分是一个类,里头也有几个函数。
让我们先进入第一部分。
- 先来看第一个函数find_dataset_using_name,这个函数在这个脚本之外就再也没使用过,推测这个函数是用来按照数据集名称来寻找所对应的dataset类的。我们可以简单地把这个函数的功能理解为,给定一个数据集名,例如Single,我们将singledataset.py脚本中的SingleDataset这个类进行实例化,并返回。整个函数乍一看很难理解,其实不然。第一行
dataset_filename = "data." + dataset_name + "_dataset"就是一个简单的拆解,便于第二行datasetlib = importlib.import_module(dataset_filename)进行导入,有人会好奇这第二行是在干什么,这一行是在动态导入对象,dataset_filename只不过就是一个索引而已,导入之后的结果是一个类实例化后的对象datasetlib。这时候小朋友们可能又要问我了,为什么是一个类实例化后的对象?因为你注意看左侧的data文件夹下,任何一个数据集(比如single)是不是都对应着一个脚本(例如:single_dataset.py),而这个脚本里是不是有一个类名字叫做SingleDataset。以后,凡导入这种类实例化后的对象,都是需要动态导入对象的。有些小朋友又会问了,为什么我们要导入这个类的对象,你不是要导入数据集么?很好,我们来看这个类是不是有__getitem__函数,你的数据都是这么被读入的,你可以理解为,数据集被存到这个类实例化后的对象里了。第三行定义一个变量并初始化dataset = None。第四行target_dataset_name = dataset_name.replace('_', '') + 'dataset',简单的文字编辑。第五行到第八行就要正式进入循环了,我们来看datasetlib.__dict__.items(),感兴趣的同学可以去查查__dict__是干什么的python中__dict__的作用是什么? 请参见__dict__的用法
,__dict_也是一个魔法函数,可以把一个类当中定义的属性和方法都作为一个字典返回,而datasetlib.__dict__.items()其实就是方便这个循环遍历这个字典,有小朋友可能会问,为什么我们要遍历?我来告诉你,因为这个类里有很多的属性或方法形成的键值对,而我们需要的只有那些图片名称和图片组成的键值对,所以我们才要在这个循环中的if函数判断其键名name是不是我们所需要的类名,然后如果它同时也是BaseDataset的子集,就说明遍历过程中当前这个cls就是我们所需要的数据集所对应的类。把它读出来给dataset。第九行到第十行是报错信息,如果第九行的条件语句被触发了,那么第十行的raise就会自动执行错误信息,raise是Python一个常见的语法。最后,这个方法显然返回的是第十一行的dataset,return dataset。注意,这个地方的dataset其实还是一个类形成的实例化对象,千万不要认为里头只有图片。 - 来看第二个函数get_option_setter。这个函数返回的是一个静态方法,这个方法就负责对命令里的option进行编辑(而这些命令就是我们平时启动训练/测试脚本的时候所使用的那些命令),而这个方法就存在于dataset_class这个类里头,这个类又是怎么获取的呢?答案就在上面一个函数里。
- 再来看第三个函数create_dataset,这次要根据所给的option真正地制作一个数据集了(不再像第一个函数那样返回一个类),代码结构也很简单,一行实例化,一行调用load_data()方法,最后返回所需数据集。但是我们还没有看到CustomDatasetDataLoader这个类呀。别急,我们先继续往下。
来让我们进入第二部分,CustomDatasetDataLoader这个类。
- 先看看__init__函数吧,需要传入的参数一个是self,就是实例化之后的对象,另一个是opt,也就是各种选项。第一行是self的性质,也就是self.opt,这个就等于你传入的参数opt,第二行,代码是
dataset_class = find_dataset_using_name(opt.dataset_mode),这是在做什么?右侧的函数返回值是一个实例化对象,也就是说dataset_class只是一个由相应的Dataset这个类实例化之后的对象(这一点从上面 find_dataset_using_name函数的解释就可窥知一二),然后转化成self.dataset,而self.dataset也是个实例化的对象,这个是要传入到torch.utils.data.DataLoader中的,而且你阅读一下torch.utils.data.DataLoader的使用方法就会发现,第一个参数一定是一个实例化之后的对象。torch.utils.data.DataLoader这个是一个非常常用的Pytorch导入数据之用的东西,具体的用法请参见torch.utils.data.DataLoader的用法,而在这个函数里头,第75-79行这几行代码不难理解,因此我不再赘述。 - 然后来看看load_data函数,这个没的说,就是读取数据,然后返回self其实也就是返回实例化之后的对象,也就是把数据集导出。
- __len__函数就不说了,具体作用大家都懂。
- __iter__函数的作用是生成一批数据(batch)并迭代。enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。yield的使用可以从这个链接yield的使用当中得到答案,它的作用是生成一个迭代(常见的迭代比如说斐波那契数列)。
总而言之,这个脚本就是围绕着create_dataset这样一个函数展开的,目的就是根据opt制作数据集,只是一个接口而已。
1.2.3.3 base_dataset.py
这个文件实现了一些基础的数据读取、转换功能。在BaseDataset类中,所有的函数基本都留空,这个是要根据具体的数据集来确定的,所以base_dataset.py里的这块是空的,可以在template_dataset.py查到每个函数对应的用法示例,而实际的应用就是single_dataset.py、colorizationo_dataset.py等文件里的用法。
我们来看看在BaseDataset类之后有什么函数。
- get_params:前面的if语句是根据opt.preprocess去计算新的宽、高大小,而73、74行则是计算x,y,这是两个参数,用于表示图像截取的位置,
random.randint(0, np.maximum(0, new_w - opt.crop_size))具体代表什么含义呢?我们不妨这么想,20×20的图片,我们要把它裁剪成10×10,那么裁剪的位置(左上角坐标)只能在左上方10×10的区域之内,要不然的话,被裁剪出的图片就无法成为10×10的图片了,这两行随机数生成就是干这个的;flip参数则是通过生成随机数的方式来计算翻转概率。这里我要多说一句,Transform是torchvision里用于图片预处理的中药模块,里头规定了很多歌变换,使用者经常通过Transform.Compose将其组合起来,如果我们需要的功能源代码里头不能实现,就需要自己定义函数,有关这部分内容可以参见Torchvision中Transform的使用。 - get_transform:这个函数的作用即使把所有预处理的方案组合一下,形成一个list,这个list就记录着我们所有的预处理操作。我们来看看81行的几个参数:
opt, params=None, grayscale=False, method=Image.BICUBIC, convert=True,opt不说了,就是指定的各个选项;params是上一个函数获取的,默认情况下是None;grayscale应该是是否进行灰度处理;method指的是放大图片的方法,Image.BICUBIC是双三次插值的意思。注意第83-84行,如果grayscale参数是Ture,就执行transforms.Grayscale(1),这个1指的是一个通道;85-87行是说,如果resize为True,则通过双三次插值把图片resize到指定大小;88-89行是等比调整大小,注意前面是elif而不是if,说明和前面的85-87行是有关联的;91-95行是关于裁剪的设定,先要判定params是不是None,如果不是,那就不能采用随机裁剪,而是指定裁剪左上角的点,并指定裁剪大小;97-98行的意思是,如果什么预处理操作都没有,那么就要通过人工调整把图片的宽、高数值调整成4的倍数;100-104行是翻转的相关操作;106-111行属于细微的调整,执行了两个操作,分别是张量化、标准化。最后将所有的变换操作compose到一起。 - __make_power_2:这个函数就是要根据给定的方法(例如:双三次插值),将图片变成指定的大小。其中的round函数是一种四舍五入的方法。
- __scale_width:这是用于调整大小的一个函数,不难读懂。
- __crop:这是用于图片裁剪的一个函数,不难读懂。
- __flip:图片左右反转,这个函数不用我说了吧。
- __print_size_warning:这个函数只是用来打印一个警告,告诉人们所输入的图片不合乎要求,需要将宽高调整到4的倍数。
1.2.3.4 image_folder.py
这是一个和图片读取有关的脚本。1-16行不说了,很容易读懂,我们从后面说起。
- is_image_file:这个脚本不说了,判定是否为图片。
- make_dataset:这就是制作数据集的函数。assert函数就是先判断dir是否是一个路径,如果不是,输出后面的报错信息。os.walk是根据给定的路径dir进行遍历,该函数返回一个 [ 文件夹路径,文件夹名字,文件名 ] 的三元组序列。28-32行很简单,我就不解释了。
- default_loader:这是一个默认的“读取器”。指定默认的读取路径,然后转换成RGB图像。这个函数是为后面做准备的。
- ImageFolder:这是一个类。43行,根据root来制作数据集,imgs实际上是一个列表;44-46行是在必要的时候返回错误信息;48-52行我就不说了,很容易;54-55行,根据索引来寻找指定序号的图片,56行,根据你给定的loader(52行定义的)去加载图片,存入变量img里,57-58行是预处理,处理的方式在50行已经给定,59-62行就是返回而已,比较容易读懂;64-65行不说了,统计imgs列表的长度,就是想看看数据集的大小。
1.2.3.5 aligned_dataset.py
先插一句,为什么要准备对齐的数据,这是因为pix2pix模型要用这个。
aligned_dataset.py包含一个可以加载图像对的数据集类。它设置好了一个图像目录/path/to/data/train,其中包含 {A,B} 形式的图像对。在测试期间,您需要准备一个目录/path/to/data/test作为测试数据。那么如何准备对齐的数据集呢,方法在这里。您也可以参阅/pytorch-CycleGAN-and-pix2pix/datasets/combine_A_and_B.py这个脚本,它就是我们在准备对齐数据的时候需要执行的脚本。我们在这里权且先不提,后面还会再说。
让我们来逐个分析在Aligned_dataset类里面的3个函数。
- __init__函数:典型的接口函数。14-20行没啥可说的,很简单。第21行是在获取数据的路径(只有路径,没有图片),第22行在1.2.3.4节中已经说的非常明确了,注意这一行的返回值应当是一个列表,列表由图像组成。第23行是为了确保裁剪大小小于图片本身的大小。第24-25行,如果转换方向是B→A,那模型的input应该是opt里的output,反之则结论相反,而模型的output也有类似的结论。
- __getitem__函数:40-41行是单独读取一张图片,并将其转化为RGB,43行是获取图片的宽、高,44-45行是从AB这一张图中获取A和B,什么意思呢?就是对齐的两张图。48-54行是对于图片的预处理,56行是返回一个字典,无需多言。
- __len__函数:不用我多说了吧。
1.2.3.6 unaligned_dataset.py
unaligned_dataset.py包含一个可以加载未对齐/未配对数据集的数据集类。我们可以使用数据集标志训练模型--dataroot /path/to/data。
依然是同样的三个函数,让我们来一一解读。
- __init__函数:里面实现的各项功能和1.2.3.5节中的__init__函数是非常类似的。26-27行获取目录,29-30行生成图片列表,31-32行获取列表大小,33-35行判断转换方向,36-37行生成变换。
- __getitem__函数:51-56行是获取图片索引的方式。57-61行是读取图片,并进行简单的预处理。63行就是返回了。
- __len__函数:这个函数不用我说了吧。
1.2.3.7 single_dataset.py
single_dataset.py包含一个数据集类,可以加载由path指定的一组单个图像–dataroot /path/to/data。它只能用于使用模型选项为一侧生成CycleGAN结果-model test。
里面的三个函数完全就是前面1.2.3.6的翻版,我就不再一一赘述了。
1.2.3.8 colorization_dataset.py
colorization_dataset.py实现了一个数据集类,可以加载一组 RGB 的自然图像,并将 RGB 格式转换为Lab颜色空间中的 (L, ab) 对。基于 pix2pix 的着色模型 ( --model colorization) 需要它。
- modify_commandline_options:这个函数的出现,意味着opt里头一些默认的选项要被修改了,因为对应着着色任务,所以输入维度是1(亮度),输出维度是2(也就是Lab颜色空间中的ab)。
- __init__函数:接口函数。第41行的assert函数要注意一下,只有在括号内的内容为True方可执行,否则报错,而其它行基本都在之前遇到过,不再赘述。
- __getitem__函数:56行是获取路径,57-59行是读图、转换、数组化,60-61行是从RGB颜色空间转换到Lab颜色空间并转化为张量;62-63行没太看懂,我推测是标准化,64行是返回值。这个函数的返回值A就是亮度,返回值B就是Lab颜色空间里的ab值。
- __len__函数:不想说了。。。
1.2.4 imgs文件夹
这里是两个示例图片,也可以被用来存放效果图。
1.2.5 models文件夹
模型目录包含与目标函数、优化和网络架构相关的模块。如果要添加一个名为的自定义模型类dummy,那么必须要添加一个名为的文件dummy_model.py并定义一个DummyModel类,这个类继承父类BaseModel。您需要实现四个功能:__init__初始化类(您需要先调用BaseModel.init(self, opt))、set_input(从数据集中解包数据并应用预处理)、forward(生成中间结果)、optimize_parameters(计算损失、梯度和更新网络权重),以及可选的modify_commandline_options(添加特定于模型的选项并设置默认选项)。现在您可以通过指定 flag 来使用模型类–model dummy。有关示例,请参见我们的模板模型类。下面我们详细解释每个文件。
1.2.5.1 init.py
_init_.py 实现了这个包与训练和测试脚本之间的接口。 train.py并在给定选项的情况下test.py调用from models import create_modelandmodel = create_model(opt)创建模型opt。您还需要调用model.setup(opt)以正确初始化模型。
- find_model_using_name:这个函数是根据参数model_name去找对应的模型。第32行的model_filename是这个model所对应的文件名,比如说里头有cycle_gan_model,就对应着models.cycle_gan_model,这是便于import所采用的方法。第33行就不说了,动态导入该文件中的类和对应的名字,形成一个字典,字典的结构是{name,cls}。第34行是先把model置为None。第35行也只是调整格式。第36-39行是重点,逐个判断所导入的字典里头的键值对,其中的name是否和target_model_name一致,如果一致且是BaseModel的一个子集,那么model等于cls并被返回,否则报错。
- get_option_setter:这个函数是根据模型名来找到对应的类,赋值给变量model_class,并把其中修改opt的选项返回。
- create_model:这个模型主要是将model实例化,并返回对应的对象instance。
1.2.5.2 base_model.py
base_model.py为模型实现了一个抽象基类 ( ABC )。它还包括常用的辅助函数(例如 , setup, test, update_learning_rate, ) save_networks,load_networks以后可以在子类中使用。
我们来看看BaseModel这个类里包含了什么东西。
- __init__函数:首先声明,如果您计划实现自己的类,在__init__函数里,必须要实现自己的初始化,怎么实现呢,要调用
- modify_commandline_options函数:这个留空,具体问题具体分析。该函数是用于修改一些opt用的。
- set_input函数:这个函数同样被留空,要针对具体情况具体分析。该函数是用于读取数据的,包含本身的数据和元数据信息。
- forward函数:这个函数也被留空了,要针对具体情况具体分析。该函数用于生成中间信息。
- optimize_parameters函数:留空函数,用来计算损失、梯度和更新网络权重。
- setup函数:这个函数用来加载并打印网络结构,除此之外会创建好一个调度器。第84行是在判断是否是训练状态,如果是,则执行第85行的策略;第85行,首先定义了一个self.schedulers,这个东西是一个列表,用中括号括起来,
for optimizer in self.optimizers指的是对于self.optimizers的每一个优化器,都要获取一下学习率更新的策略,怎么样才能获取呢?就是使用networks.get_scheduler(optimizer, opt)这个方法,注意到该方法源码就在networks.py的get_scheduler方法里头,我们下面的network.py的讲解里头会提到。第86-88行,如果self.isTrain这个标志不为真,或者只是继续训练(opt.continue_train为真),那么则要加载已有的网络,当然这块我也有个疑问,就是load_networks这个函数的输入明显应该是int类型(下面定义里头有注释),但为什么第88行其输入是一个字符串呢。不论如何,第89行都要根据opt.verbose是否为真打印一下网络。 - eval函数:这是一个评估模式的函数,它将保证模型在测试阶段处于评估模式。对于self.model_names这个列表里头的每一个name(一个name就将对应一个model),第94行,如果name是字符串,那么可以使用getattr函数来判定self这个对象里是否有
'net' + name这样一个属性,如果有,则把这个属性值赋给net变量,如果没有则报错,有关getattr()的用法请单击这里。当然,这里的属性值指的就是一个网络,也就是说net代表的是一个网络,所以第96行其实就是开启评估模式。 - test函数:这是测试过程中前向传播的函数, with torch.no_grad()可以让节点不进行求梯度,从而节省了内存控件,测试的过程显然是不需要反向传播求梯度的,第105行是前向传播,第106行是计算visdom和HTML可视化的其他输出图像。
- compute_visuals函数:这个函数我刚刚已经说过了,计算visdom和HTML可视化的其他输出图像。在train.py的第56行有用到这个函数,这是展示图片代码的一个组成部分。
- get_image_paths函数:这个函数是获取图片所在的路径。
- update_learning_rate函数:这个函数用来更新学习率。第118行是获取旧有的学习率,在Pytorch当中,optimizer.param_groups 是长度为2的list,其中的元素是2个字典,详情请单击这里查看,其中的optimizer.param_groups[0]是长度为6的字典,包括[‘amsgrad’, ‘params’, ‘lr’, ‘betas’, ‘weight_decay’, ‘eps’]这6个参数,所以说我们看到的optimizers[0].param_groups[0][‘lr’]就是optimizers[0]这个优化器的学习率。第119-123行其实就是更新学习率的主体部分,其本质是针对每一个self.schedulers这个列表里的元素,根据self.opt.lr_policy来安排一个学习率更新的方法,注意如果学习率更新策略是plateau,会和其它的有些不同,这种情况下第44行已经说了,self.metric=0,其它的只要正常按照step去更新学习率就可以了。关于scheduler.step()这个东西,可以看看这里,我们只需要知道,他是一个用于更新学习率的东西就可以了。第125行是获取现有学习率,第126行是打印学习率的变化。
- get_current_visuals函数:用来返回可视化图像。第130行,visual_ret = OrderedDict()是实现对字典的元素排序,赋给visual_ret这个变量,对于self.visual_names列表里的每一个name,第133行都要获取它对应的属性,存入visual_ret这个字典中,和’name’组成一个键值对,最后字典visual_ret被返回。这里的属性可能指的是一张图片。
- get_current_losses函数:获取当前的损失值。有人可能会好奇,为什么会有和诺损失函数呢?这是因为每一层所采用的损失函数很可能是不一样的。
- save_networks函数:保存整个网络。第150-154行比较好理解,就是指定好保存路径,获取属性(网络)。第156行是在判断GPU是否可用,是够规定了使用gpu进行训练(通过gpu_ids来判断),显然通过这行我们可以知道,CPU和GPU模型的保存模式是完全不同的,在156-160行中,.state_dict()这个方法是用来提取网络中参数的,我们要保存模型,当然是为了保存参数,第158行的意思是说,使用GPU中的第0块进行训练。但为什么这块还要训练一遍我不太懂。
- __patch_instance_norm_state_dict函数:这个函数我一直没太懂是什么意思,不过看里面的注释,好像是为了解决Pytorch版本低于0.4的不兼容问题,而我使用的Pytorch是1.10.2,自然没有理会这个函数。
- load_networks函数:这是导入网络的函数。从第182行开始,对于self.model_names当中每一个name。第183行,如果这个name是字符串类型,那么就执行后面的操作。第184、185行就是字符串的拼接,获取导入的文件名load_filename和导入的路径load_path。第186行是找到属性的一个办法,回传的是一个属性,即:网络net。第187行,注意isinstance这个函数,它的结构是isinstance(object, classinfo),前者是对象名,后者是类名,也就是判断这个对象是否属于这个类,类似的前面的183行,isinstance(name, str),str也是一个class,所以这一行就是判断net是否属于torch.nn.DataParallel这个类,而torch.nn.DataParallel又是什么呢,它是用于多GPU并行计算的一个类,可以理解为如果属于torch.nn.DataParallel类,那么就需要使用多GPU。第188行,如果要使用多GPU,那每一个GPU上的net应该相当于原有net当中的module,也就是说使用nn.DataParallel后,事实上DataParallel也是一个Pytorch的nn.Module,那么你的模型和优化器都需要使用.module来得到实际的模型和优化器,这就是为什么会有第188行的代码,更多关于并行计算的内容请单击这里。第189行略过。第192行,torch.load这个函数可以加载模型,里头的参数一个是模型存放的路径,另一个是用于训练的装置map_location,当然啦,加载模型的实质是加载参数,这些参数就会被存储在state_dict这个字典之中。第193-194行,首先判断参数字典里是否包含元数据这样的属性,也就是第193行里的__metadata,如果有就删除(因为元数据是描述数据的数据,而我们加载网络参数的时候显然是不需要获取这些元数据的)。第197-198行同样也是兼容问题,所以我们也就没有理会。第199行就是将参数字典导入到我们的网络中了。综上所述,实际过程分成两步,第一步是将导入参数,第二部是将参数字典加载到net里。
- print_networks函数:请注意208-210行这个结构出现过很多次了,应该注意记住。param.numel()的功能是返回param中元素的数量,所以说num_params是在统计所有参数的数量。第214-215行不说了,根据verbose判断是否要打印网络。216-217行也很容易理解。
- set_requires_grad函数:第225-226行的意思是,如果net不是列表,要先把它列表化;后面的很好理解,把每一个参数是否需要计算梯度设置为您一开始给定的参数值。
1.2.5.3 template_model.py
这个脚本主要是用来做模板之用。该模块为用户提供了一个模板来实现自定义模型,可以指定“–model template”来使用此模型,类名应与文件名及其模型选项一致。文件名应该是_dataset.py,类名应该是Dataset.py。它实现了一个简单的基于回归损失的图像到图像的转换baseline。给定输入输出对(data_A,data_B),它学习可以最小化以下L1损失的网络netG,使得:
min_<netG> ||netG(data_A) - data_B||_1
- modify_commandline_options函数:这个函数专门用来更改opt当中的选项,比如第35行就是把默认的dataset模式改成“对齐”。第36、37行就是在训练状态下,为它新加一个标签,即:lambda_regression,默认值是1.0,第39行不说了。
- __init__函数:第51行,对Basemodel通过Basemodel这个类里的__init__函数进行初始化。第53行是指定你想要输出的损失函数名称(把所有的名称存放在这个列表里),程序将会调用
base_model.get_current_losse来返回损失函数值并存储。第55行是在调用一个函数去存储,这些图片的保存是通过base_model.get_current_visuals来实现的。第58行是指定需要存储/调用的模型的名字,通过base_model.save_networks和base_model.load_networks来实现,你可以使用opt.isTrain去控制训练和测试模式,这二者往往是不同的。第60行是在定义生成器G,在同一级目录的network里有一个define_G的函数,我们在这里就是调用了这个函数,需要传入的参数包括输入、输出、最后一个卷积层里有多少filter、网络名、使用哪块GPU去训练。第61行,是判断语句,无需多言,注意self.isTrain是在base_model.py里定义的。第64行是定义一个损失函数,把这个损失函数赋值给self.criterionLoss。第67、68行是在定义一个优化器,并把优化器存入优化器列表里,这里我们选用了Adam优化器,具体的公式请参见这里。 - set_input函数:这个函数是专门用来设定输入的,第78行是一个判断语句,方向是否是AtoB。第79-80行是读取数据之用,并把它们送入
self.device这个装置里,第81行是找到输入图片的路径。 - forward函数:第85行就是一个前向输出。
- backward函数:这是反向传播。第91行,
criterionLoss就是L1损失,后面再去算一个回归损失。self.loss_G.backward()就是计算梯度,并且实现反向传播。 - optimize_parameters函数:96-99行注释已经说得很明确了。
1.2.5.4 network.py
-
第1-5行是导入一些基础的包。前两行比较简单,第三行的作用是让我们可以使用torch.nn.init进行初始化参数,第四行这个包是一个针对函数进行操作的函数,第五行是导入优化器。
-
下面介绍Identity这个类。
- 里面只有一个forward函数,这个函数比较好理解。
- 下面介绍get_norm_layer这个函数。
- 这个函数的作用是得出“标准化层”。传入的参数只有norm_type,也就是标准化的方式,这个里头有三种办法,第一种是batch,第二种是instance,第三种是不操作,最后是报错信息,并返回norm_layer.这里就要简单来说说几种归一化方式了,比较详细的介绍可以参考这里,一个图片分成3个通道,于是就有了H×W×C这样的维度,而B张图片加起来就形成了一个batch,这样就变成了,首先是BatchNorm,这种方式会让某个batch中所有的图片位于(c,h,w)这个位置的像素进行标准化,InstanceNorm这种方式对在某张图片的某一个channel内H×W的全体像素做归一化,在这里补充一下Layernorm是什么,这其实是对一张图片的不同通道的同一位置的像素最归一化。只有BatchNorm需要仿射变换以及追踪统计信息。
- 下面介绍get_scheduler这个函数。
- 这个函数是用来获取学习率更新策略的。具体每种策略都是怎么回事可以自行查找,不是太难理解。
- 下面介绍init_weights这个函数。
- 这个函数用来初始化网络的权重用的。传入参数是初始化的类型和增益的大小。传入的参数m是一个类,79是要获取类名,第80行的意思是如果m包含属性weight且name里有conv或是Linear,则执行下面的操作,注意.find函数的用法。 81-90行是各种权值初始化的方法,不再赘述。91-92行是一个偏差值的指定,相当于y=wx+b里头的b。93-95行则是指BatchNorm2d的情况(输入为2d)。97-98行就是应用。
- 下面介绍init_net函数。
- 这个函数将通过调用刚刚的init_weights函数来实现权值初始化,返回一个net。
- 下面介绍define_G函数。
- 这个函数用来定义生成器。需要的传参在122-133行详细地说过了。同时我们有两类网络备选,分别是UNet-128/256和Resnet6/9.第146行,设定net的初始值是None(即:什么都没有),第147行是获取标准化层(比如:BatchNorm2d等),后面对类进行实例化的时候会用到。149-160行这个想要读懂并不困难,就是实例化,我们会在后面的文章里介绍那些类。
- 下面介绍define_D函数。
- 这个函数用来定义判别器,和刚刚的define_G函数有异曲同工之妙。165-175行详细解释了每个参数的含义,此处不再赘述。177-190行是对网络的各种介绍。192-193行和146-147行是完全一样的。195-203行也是在实例化,我们将在后面对这些类一一揭晓。
- GANLoss类
这个类是用来创建不同的GAN对象的,按照注释内所说的,他把“创建与输入大小相同的目标标签张量”这一任务抽象化了。换言之这是用来创建标签用的。
- __init__函数:这个函数主要是定义损失函数。需要传入的参数包括gan的模式、目标真值、目标非真值。227行是初始化,228-229行是在保存一些不会更新的模型参数,关于register_buffer函数的用法请参考这里。230行是指定新属性。231-238行是根据gan模式来定义损失,234行的含义请点击这里。
- get_target_tensor函数:创建与input大小相同的标志向量。传入参数注释里有明确介绍。第255行就是把target_tensor这个tensor转换成和prediction一样的大小。
- __call__函数:这个函数并不难理解,就是计算损失而已。这也是这个类的基本功能。
- cal_gradient_penalty函数。
- 计算梯度惩罚损失,用于WGAN-GP论文,和CycleGAN关系不大。280-291行详细解释了传入参数的含义。由于该函数和CycleGAN关系不大, 我们权且略过。
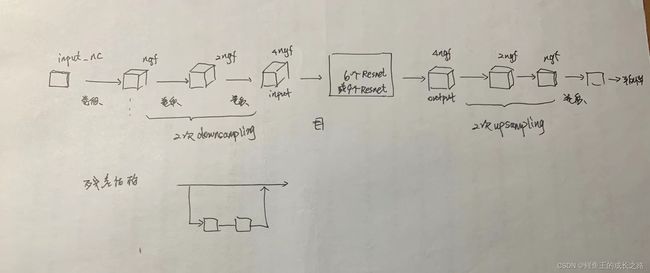
- 类ResnetGenerator:
这个类是用来定义残差结构的。
- __init__函数:322-332行着重介绍了每个参数的含义。333行是为了防止不合理的数据添加的报错信息。334行是继承。335-338行没太看懂,感兴趣的同学可以看这里,不过大概是确定是否使用bias。340-343行是模型结构的第一部分,其中nn.ReflectionPad2d()的用法请点击这里,这一行指的是在图片上下左右都填充3行;nn.Conv2d是卷积,详细用法看这里;然后是342、343行的标准化、ReLU激活。345行是定义降采样次数,346-350行是模型的扩张。352行就是看一下目前的图片有几个通道(不出意外应该是4倍ngf),353-355行是加入残差块,357-364行执行了两次上采样过程。365-367行是填充、卷积和tanh函数激活,369行将模型确定。
- forward函数:这是车头车尾的前向传播。
- 类ResnetBlock:
这是用来定义残差块结构的。
- __init__函数:387行是继承,388行是后面的build_conv_block函数,具体参数会在下一个函数里解释。
- build_conv_block函数:391-401行已经把参数的含义揭示了一遍。402行为初始化一个空列表,403-411行都是去进行填充。413行添加新的卷积层、批归一化、ReLU函数。414-415行是随机丢弃一部分神经元,417-426行是把之前的操作又搞了一次,只不过这次没有ReLU激活和dropout。428行是把模型组合起来。430-433行是前向传播的过程。
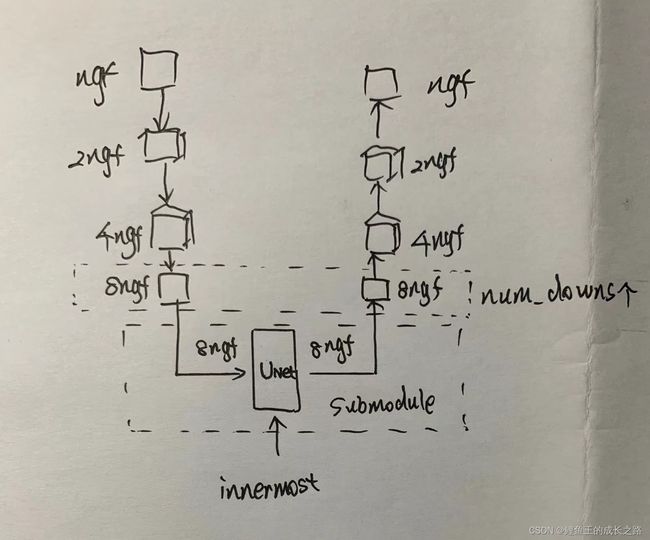
- 类UnetGenerator:
这个是用来定义UNet生成器结构的。
- __init__函数:440-451行解释说明了参数的含义。452行是继承,454-461都是在定义Unet的结构,大体来说是这样的。
- forward函数:前向传播。
- 类UnetSkipConnectionBlock:
这个类用于定义UNet里面的小结构。
- __init__函数:476-487行是已有参数的说明。488行是继承。489行是判断是否为最外侧的一行。490-493行也是决定是否使用偏移。494-495行就是对中间的层采取的措施,在这样的层里,input_nc一开始是None,我们把input_nc和输出的outer_nc设为相等,因为一个Unet子结构是不改变图片通道数量的。见下图。496-499行是下采样过程中的卷积层、激活函数、归一化。500-501行是上采样过程中的归一化、激活函数。503-522行根据三种情况来确定上采样过程中的模型。524-527行是上面的第三种情况里才会调用,总的结构是不难理解的。
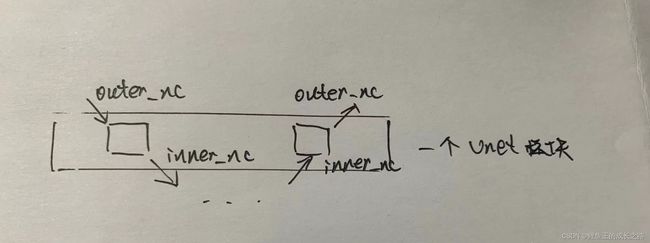
- forward函数:531-535行是前向传播,这个无需多解释,注意torch.cat是合并的意思,第二个参数是1,说明是横向合并。
- 类NLayerDiscriminator
这个类是用来创建判别器的。
- __init__函数:这个是初始化。542-549行都是参数的定义。550行是继承。551-554行是针对偏移量做出决定。556-558行是在对模型进行组装,形成模型的第一步。559-568行是第二步,也就是逐步增加filter的个数,当然,第二步这个模块的数量和n_layers这个参数是密切相关的。570-576行是第三步,578行是第四步,579行是组装模型。
- forward函数:581-583行是前向传播。
- 类PixelDiscriminator:
- __init__函数:590-596行是在介绍参数的含义。597行是继承。598-601行是判断是否需要偏移量。603-609行是网络的定义,总的来说没什么难度。611行是给self.net赋值。
- forward函数:613行-615行是前向传播。
至此,network.py长达616行的脚本解读完毕。
1.2.5.5 cycle_gan_model.py
第2行的itertool是一个Python提供的迭代工具箱,第3行image_pool.py实现了一个存储先前生成的图像的图像缓冲区。这个缓冲区使我们能够使用生成图像的历史而不是最新生成器生成的图像来更新鉴别器。后面就是CycleGANModel这个类,第12-15行有非常明确的概述,dataset模式要使用“非对齐、未配对”,它会使用带有9个残差块的生成器网络结构,并使用PatchGAN这样的判别器结构,以及一个最小方根的GANs对象(就是说损失函数使用LSGAN,平方损失),我们来逐个分析其中的函数。
- modify_commandline_options函数:这个就不说了,基本就是option。第39行默认不使用dropout,第40-43行,是指定上面几个损失函数项的权值,45行不说了。
- __init__函数:第55行是损失函数列表,里头有几种损失函数’D_A’, ‘G_A’, ‘cycle_A’, ‘idt_A’, ‘D_B’, ‘G_B’, ‘cycle_B’, ‘idt_B’,其中
'D_A'和'D_B两个判别器的损失,'G_A'和'G_B'是两个生成器的损失,上面这四项在公式(1)及公式(1)的变体里边都有体现;'cycle_A'和'cycle_B'这两个是循环一致性损失,见公式(2);'idt_A'和'idt_B'是公式(5)里出现的,针对图片→照片任务的损失项。第56-61行指的是要展示/保存的图片,57行是真实的A、经cyclegan转化出的B、经cyclegan重建的A,第58行则是换成B;第59、60行是针对着色任务开辟出来的两项;第63行没什么可说的,就是组合而已。第65-68行是模型的组合情况,就是有哪些模型会被使用。第73-76行没啥可说的,是定义生成器的地方,define_G这里面的参数是什么意思,在1.2.5.4节中有介绍。第79-82行更是类似,生成判别器的地方,define_D这里面的参数是什么意思,在1.2.5.4节中有介绍。第84行跳过,85-86行指的是,如果有“图片→照片”的任务,那么应该保证输入图片和输出图片的尺寸一致,否则报错;87-88行是给训练过程中制作一个imagepool,用于存储历史图片,fakeApool和fakeBpool分别是“BtoA”和“AtoB”情况下的imagepool。第90行是根据你选择的gan模式(opt.gan_mode)确定一个模型,并将其输送到self.device里,剩下两个损失完全都采用了L1损失函数。第94-95行是设定优化器,注意其中的itertools.chain是迭代,也就是把里面所有的参数组合起来,每轮训练过后一起迭代,lr和betas可以自己去查Adam优化器的相关知识,不再赘述;第96-97行是把设定好的优化器加在既有的self.optimizers列表里,这个列表来自basemodel.py。 - set_input函数:这个函数和此前的basemodel.py非常像,不再赘述,也很容易看懂。
- forward函数:前向传播,非常容易理解,不再赘述。
- backward_D_basic函数:第130-135行是用于判别器计算损失的,131、134行就不说了,利用netD去进行判别,得到预测值pred_real和pred_fake,然后再根据这两个值去分别计算损失loss_D_real和loss_D_fake,并且在137行将其combine成为loss_D。138、139行就纯粹是反向传播和返回值了。
- backward_D_A函数:第143行是把self.fake_B_pool这个imagepool通过query这个函数拆成单张图片,例如:fake_B。第144行self.loss_D_A是利用上一个函数计算损失值。这个损失值代表的就是从A到B这个风格的转换,所造成的真实B和生成B的区别。
- backward_D_B函数:和上面的backward_D_A函数很接近。
- backward_G函数:153-155行是权重的计算。156-166行代码的理解并不困难,这是在“图片→照片”任务中会使用的损失,公式可能有点难以理解,不过和原论文5.2节里的东西是完全一致的。168-178行则是简单的损失函数定义并反向传播,没有什么难点。
- optimize_parameters函数:这个函数的注释也已经很友善了。有一点不太明白,更新生成器的权重,不需要判别器,但更新判别其权重,却需要生成器?
1.2.5.6 pix2pix_model.py
该任务和我们的CycleGAN任务暂时无关,是pix2pix里的任务,我们暂时不谈。
1.2.5.7 colorazation_model.py
该任务和我们的CycleGAN任务暂时无关,是pix2pix里的任务,我们暂时不谈。
1.2.5.8 test_model.py
将于后续补充。
1.2.6 option文件夹
这个文件夹里的4个文件都是用来规定训练命令里的选项之用。init.py是一个接口类型的文件,没有什么用。base_option.py是一些基础性的选项,它还实现了一些辅助功能,例如解析、打印和保存选项。它还收集modify_commandline_options数据集类和模型类的函数中定义的附加选项;而剩下两个文件则分别对应着训练时、测试时的一些选项,原脚本已经把里面的参数解释的明明白白了。
这一部分不是重点,建议大家不要过分拘泥在这里。
1.2.7 scripts文件夹
这里存放了一些.sh脚本,关于shell的教程可以参见这里。
这一部分不是重点,建议大家不要过分拘泥在这里。
1.2.8 util文件夹
这个文件夹内是一些辅助功能。
这一部分不是重点,建议大家不要过分拘泥在这里。
2.复现过程
2.1 准备过程
- 先要克隆远程仓库
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix并将当前目录调整到项目根目录下:cd pytorch-CycleGAN-and-pix2pix - 安装所需要的包
pip install -r requirements.txt - 下载数据,这里要用到的命令是
bash ./datasets/download_cyclegan_dataset.sh maps,当然你可以将maps换成其它数据集的名字,也可以自己制作数据集。下载之后的数据集被自动存储在了datasets文件夹下面相应的文件夹里,例如:map。然后,这个文件夹中有train、test、val、trainA、trainB、testA、testB、valA、valB九个文件夹,A、B分别象征着风格A和风格B,而不带AB的则是两个风格合并到一起的图片。
2.2 训练过程
- 下面转入训练部分,你可以用python脚本训练,也可以用.sh脚本训练,原github里提供了两个训练命令。这里可以看看一个训练博客。这里我们选用的命令是
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan。
训练结果是这样的:
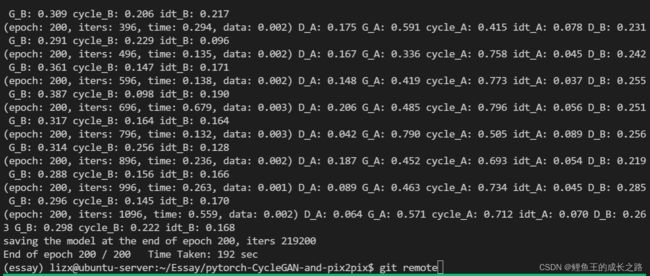
里面的含义是这样的:第几个epoch、第几次迭代、总用时、训练一个data的用时,后面就是各种损失。
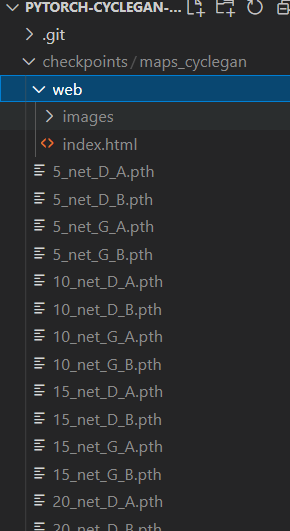
训练后的结果(包括模型和示例图片)都保存在根目录下一个叫checkpoint的文件夹里。大家可以查看,image文件夹下是图片,其它.pth文件都是模型权重文件。如下图所示:
2.3 测试过程
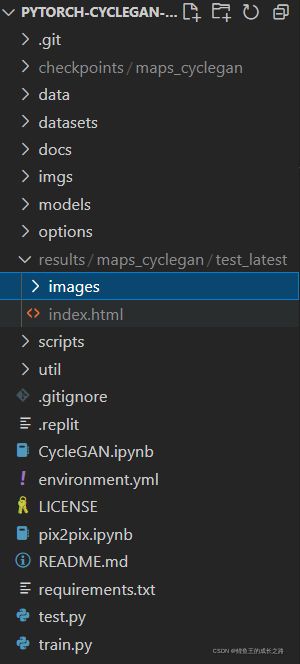
- 测试的命令是
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan。测试结束后,结果可以在下面标蓝的文件夹里找到。
参考:https://blog.csdn.net/Joe9800/article/details/103224383