解读《Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation》论文
论文大纲目录
-
- 一、工作:
- 二、目前的挑战:
- 三、DocRE不足:
- 四、模型:
-
- (1)表示学习:
-
- ①实体表示
- ②文本增强实体表示
- ③实体对表示
- ④轴向注意增强实体对表征
- (2)自适应局部损失:
-
- ①自适应阈值损失(ATL):
-
- a)正面类别:
- b)负面类别:
- ②ATL与AFL区别:
- (3)基于远程监督预训练的知识蒸馏
-
- ①朴素适应
- ②知识蒸馏
- 五、实验:
-
- (1)主要结果
-
- ①DocRED数据集
- ②HacREd数据集
- 六、消融实验
- 七、自适应方法比较
- 八、错误分析
- 九、延展思考
- 十、结论
对于本论文我把所有内容重新排版了,加上自己更直白的话来直观介绍。
如果对于文章里的名词解释有疑惑,可以参考我这篇文章
一、工作:
首先,我们使用轴向注意模块学习实体对之间的相互依赖关系,提高了两跳关系的性能。其次,我们提出了一个自适应的局部损失来解决DocRE的类不平衡问题。最后,我们利用知识蒸馏来克服人工标注数据与远程监督数据之间的差异。
首先,为了改进两跳关系的推理,我们提出使用轴向注意模块作为特征提取器。此模块使我们能够关注两跳逻辑路径内的元素,并捕获关系三元组之间的相互依赖关系。其次,我们提出自适应局部损失函数来解决标签分配的不平衡问题。提出的损失函数鼓励长尾类对整体损失贡献更多。最后,我们利用知识蒸馏来克服带注释数据与远监督数据之间的差异。
二、目前的挑战:
DocRE任务在以下几个方面比句子级任务更具挑战性:(1) DocRE的复杂度随实体数量的增加呈二次曲线增长。如果一个文档包含n个实体,则必须对n(n - 1)个实体对进行分类决策,且大多数实体对不包含任何关系。(2)除了正例和负例的不平衡外,正例对关系类型的分布也非常不平衡。以DocRED (Y ao et al., 2019)数据集为例,共有96种关系类型,前10种关系占所有关系标签的59.4%。这种不平衡显著增加了文档级RE任务的难度。
三、DocRE不足:
现有DocRE方法有三个限制:首先,现有方法主要关注实体对的句法特征,而忽略了实体对之间的交互作用。Zhang et al.(2021)和Li et al.(2021)使用CNN结构对实体对之间的交互进行编码,但CNN结构不能捕获两跳推理路径内的所有元素。其次,之前没有明确处理DocRE的类不平衡问题的工作。现有作品(Zhou等人,2021;Zhang等,2021;Zeng et al., 2020)只关注阈值学习来平衡正例和负例,但正例内部的阶级失衡问题并没有得到解决。最后,关于将远程监督数据应用于DocRE任务的研究很少。Xu等人(2021)已经表明,远程监督数据能够提高文档级关系提取的性能。然而,它只是单纯地使用远程监督数据对正则模型进行预训练。
四、模型:
关系抽取问题本质上是一个多标签分类问题。我们的半监督学习框架主要包括三个部分:

(1)表示学习:
对于表示学习,我们首先通过一个预先训练的语言模型提取每个实体对的上下文表示。通过轴向注意模块对实体对之间的相互依赖信息进行编码,进一步增强实体对的表示。
①实体表示
上下文嵌入:
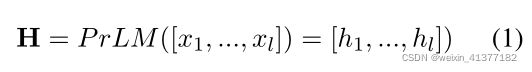
实体ei的聚合特征:
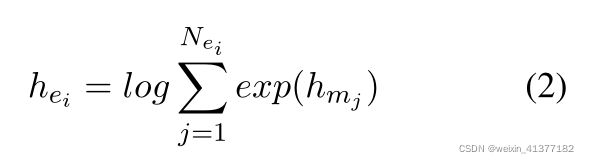
②文本增强实体表示
平均池化:聚合注意力输出

上下文查询的计算方法:

实体对中s的情景增强:

实体对中获得o同理
③实体对表示
实体对在每个维度上的值:
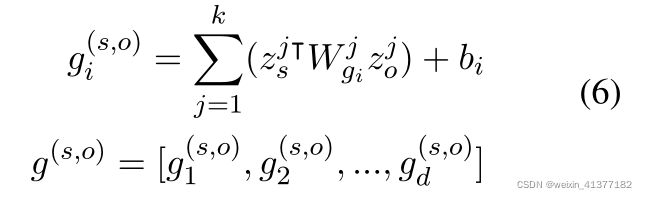
具有n个实体的给定文档D,我们需要对n(n - 1)个实体对排列进行分类。
④轴向注意增强实体对表征
提出使用两跳注意力(two-hop attention)对实体对表示的轴向相邻信息进行编码。给定一个n × n的实体表,对于实体对(es, eo),关注它的轴向元素对应于关注(es, ei)或(ei, eo)元素。也就是说,如果可以将两跳关系(es,eo)分解为路径(es,ei)和(ei,eo),那么用于分类(es,eo)的信息量最大的邻居是与该实体对共享es或eo的单跳候选对象。轴向注意简单地通过沿高度轴和宽度轴的自注意来计算,每次沿轴的计算之后都有一个残差连接。
沿轴做残差链接:

指定q(i,j) = WQg(i,j),键k(i,j) = WKg(i,j),值v(i,j) = WV g(i,j),它们都是实体对表示g在位置(i,j)的线性投影。
(2)自适应局部损失:
然后我们使用前馈神经网络(FFN)分类器来获取logit并计算它们的损 失。我们使用我们提出的自适应局部损失,以更好地学习从长尾类。
预测关系线性层:
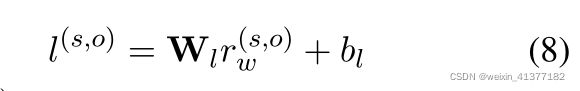
l(s,o)∈Rc表示所有关系的输出logit。
①自适应阈值损失(ATL):
ATL没有对所有示例使用全局概率阈值,而是引入了一个特殊类T H 作为每个示例的自适应阈值。对于每个实体对(es、eo),其logit 大于TH类logit的类将被预测为正类,其余的将被预测为负类。
自适应局部损失(AFL):在训练过程中,将标签空间划分为两个子集: 正类子集PT和负类子集NT。
a)正面类别:
正类子集PT包含实体对(es, eo)中存在的关系,如果实体对(es, eo)中不存在关系,则PT为空(PT =∅)。
正类概率计算:

b)负面类别:
负子集NT包含不属于正类的关系类,NT = R \ PT。
负类logit计算TH类概率:

损失函数:
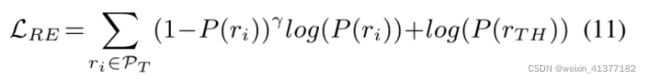
②ATL与AFL区别:
AFL其中ri的logit与阈值类TH的logit分别排序。这与最初的ATL 不同,在最初的ATL中,所有的正对数都与softmax功能一起排序。
(3)基于远程监督预训练的知识蒸馏
最后,我们利用知识蒸馏来克服人工标注数据与远程监督数据之间的 差异(远程监督适应的关键挑战是克服远程监督数据与人工标注数据 的概率分布之间的差异。)。具体来说,我们使用带注释的数据训练 teacher模型,并将其输出用作软标签。然后基于软标签和远距离标 签对student模型进行预训练。预先训练的student模型将使用带注 释的数据再次微调。
①朴素适应
首先使用具有关系提取损失LRE (Eqn. 11)的远程监督数据对模型进 行预训练,然后对具有相同目标的人工标注数据进行微调。我们称这 种方法为朴素适应(NA)。
②知识蒸馏
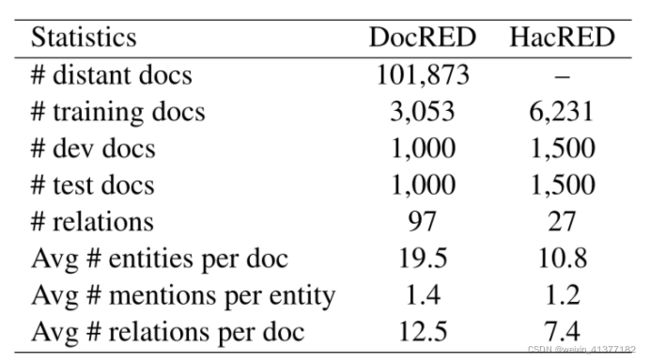 表表1:DocRED和HacRED数据集的数据集统计。
表表1:DocRED和HacRED数据集的数据集统计。
为了进一步利用带注释的数据,我们使用一个在带注释的数据(表1中的#Train)上训练的关系分类模型作为教师模型。远程监督数据被输入到教师模型中,而预测的logits将是用于训练学生模型的软标签。学生模型与教师模型具有相同的配置,但同时使用两个信号进行训练。第一个信号是来自远监督数据的硬标签的监督,第二个信号来自预测的软标签。
硬标签上的损失函数为:
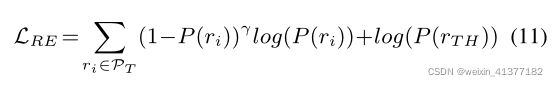
软标签上的知识蒸馏损失函数:
![]()
l(s,o) s为学生模型的预测对数,l(s,o) T为教师模型的预测对数。
总体损失函数:

五、实验:
在两个文档级关系提取数据集上评估了模型——DocRED-base和HacRED数据集。
DocRED是一个众包的大规模文档级关系提取数据集。它包含3,053/1,000/1,000个实例,分别用于培训、验证和测试。HacRED是一个中文关系抽取数据集,主要研究关系抽取的疑难案例。它包含27个硬关系,分为6231 / 1500 / 1500个实例,用于训练、验证和测试。然而,HacRED的测试集还没有发布。在本文中,我们只提供其开发集上的结果。
(1)主要结果
①DocRED数据集
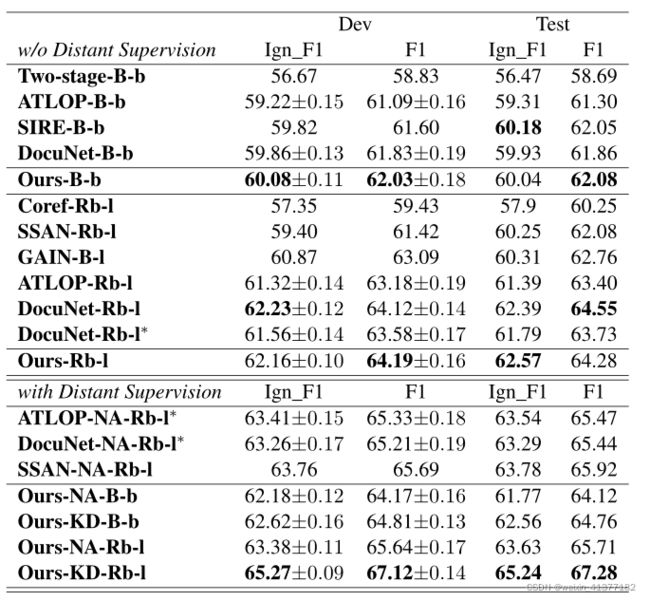
表2:DocRED数据集的实验结果。报告的指标是F1得分和Ign_F1。我们报告开发集5次随机运行的平均值,最佳检查点用于提交测试结果的排行榜。∗的结果是通过复制得到的。
表2显示了DocRED数据集的主要结果。知识精馏能够显著提高我们的模型的性能。我们的kd - rb -l获得了67.28试验F1的最佳单模型性能。我们最好的模型在测试F1上比之前的最先进的san - na - rb -l性能提高了1.36,在测试Ign_F1上提高了1.46。我们最好的模型在测试F1上比之前的最先进的san - na - rb -l性能提高了1.36,在测试Ign_F1上提高了1.46。
②HacREd数据集

表3:在HacRED开发集上的实验结果。*是由我们执行的。所有实验均使用XLM-R-base作为编码器。
HacRED数据集的实验结果如表3所示。 我们的方法和TLOP基线的主要区别在于自适应局部损失和轴向注意模块。 我们提出的方法能够比A TLOP基线超出1.12 F1。除了模型的性能之外,值得注意的是,对于每种方法,HacRED的绝对性能都显著高于其在DocRED上的性能。这是违反直觉的,因为HacRED侧重于硬关系,而DocRED则更一般。
这可能是由以下原因造成的:
1)HacRED数据集的人工标注训练实例明显多于DocRED,从而导致更好的泛化性能。
2) 尽管HacRED声称它专注于关系提取的硬案例,但它只有27个类,并且HacRED数据集中的关系类型分布更加平衡。
六、消融实验
先把标签空间分成两个子集。第一个子集由10个最常见的标签组成,占训练数据中正关系的59.4%。第二个子集表示为长尾标签,它包含了86个关系中的其余部分(总标签空间为97,有一个T H类)。
由于我们的自适应局部损失函数主要是为了提高低频率类的性能,我们在表4中展示了频繁类和长尾类的消融研究。当我们将AFL损失改变为传统的自适应阈值损失(Zhou et al., 2021)时,KD的总体性能下降了0.89 F1,而频繁标签的F1得分仅下降了0.65。
同时,长尾标签F1下降1.78,明显高于整体性能下降和频繁性能下降。这表明我们的自适应焦点损失能够平衡频繁类和不频繁类的权重。轴向关注模块对于长尾类比频繁类更有利,表明我们的模型在频繁类上的性能是饱和的。
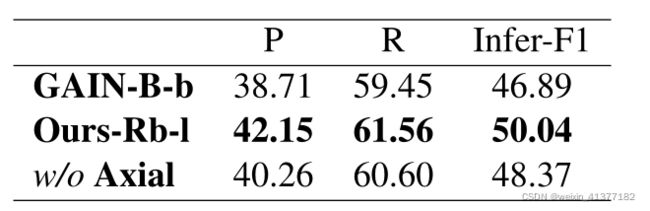
表5:DocRED开发集上inferf - f1关系的消融研究。
七、自适应方法比较
在本节中,我们直接比较DocRED开发集上的知识适应方法(表6)。
我们主要比较了三种自适应方法:
1)朴素自适应(NA)
2)KDKL知识蒸馏与KL散度损失,
3)KDM SE与均方误差损失。
开发集上的适配性能与下游微调性能呈正相关。在远端适应环境中,我们的最佳方法KDM SE比NA高出3.07 F1,比KDKL高出0.77 F1。在持续训练设置中也观察到类似的表现差异。
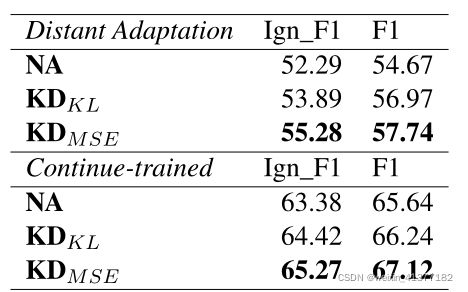
表6:DocRED不同知识适应方法的开发集性能。
八、错误分析

表7:我们的误差分布统计。最终的评价分数是在r∈R的三元组上进行评价,因此在计算最终分数时忽略NR的正确预测。
我们首先构建模型的预测和地面真值三元组的联合(没有NR标签)。然后,我们将并集分为四类:
(1)Correct ( C),其中预测三元组在ground truth中。
(2)错误(W),预测的头实体和尾实体位于地面真值,但预测的关系是错误的。
(3) miss (MS),模型预测一对头实体和尾实体没有关系,但在地面truth中有关系。
(4) More (MR),其中模型预测了一对头实体和尾实体在地面真理中不相关的外部关系。
九、延展思考

表8:DocRED开发集上的性能分解。
然而,我们观察到,我们的大多数错误都在MR和MS类别下,它们的计数大致相同。为了更好地理解文档级RE任务的性能瓶颈,我们在一个简化的子任务(表8)上评估我们的模型。
这个子任务是二进制分类,即确定两个实体是否相关,它被记为binary Labels。在这个子任务中,我们只关心正确预测头部实体和尾部实体之间存在某种关系,而不关心97个关系类之间的确切关系。在这个简化任务上的性能是68.64 F1分数,只比原来的F1分数67.12略高。这可能是由于两个文档级关系提取数据集的注释不完整造成的,我们将在图2中说明这一假设。

图2:我们的模型在DocRED开发集上的示例输出。
在图2中,我们展示了来自DocRED开发集的示例文档及其预测。我们观察到在MR分类中的许多三元组是事实正确的。也就是说,一些实体对是真正相关的,但在整个数据集中被标记为NR。例如,从基本事实来看,我们可以看到Labour Party和Hol都是来自挪威的实体。类似地,Nordland和Vestvågøy都在挪威,但它们与挪威的关系并不存在于真实值的三元组中。
(说简单点就是DocRED数据集的人工标注不够多,而该模型预测出来这种关系,与人工标注关系相对比还多好几种关系了。所以被评分没有高出很多。典型的模型被人工标注耽误了)
因此,当我们的模型预测这些三元组时,它的表现会在评估时受到不公平的惩罚。**这表明DocRED数据集中有一些不完整的注释。**然而,这并不是本文的重点,我们希望把它留作以后的工作。
十、结论
本文提出了一种新的文档级关系抽取框架,该框架基于知识精馏、轴向注意和自适应焦点损失。我们提出的方法能够在DocRED排行榜上显著超过以前的艺术状态。此外,我们还进行了深入的消融研究和误差分析,以识别文档级关系提取任务的瓶颈。