机器学习全面知识点总结(小白入门!)
**
机器学习相关总结(小白入门!)
**
目录
- 机器学习的特点
- 机器学习的研究对象
- 机器学习的应用
#大家好,这篇博文主要介绍机器学习相关的基本理论和部分应用,目的是帮助初学者对机器学习建立初步的认知框架,文章通俗易懂,以后博主还会根据具体的机器学习实践和部分模型模型应用更深入的帮助大家汇总相关知识。
现在让我们开始吧!!!
1.机器学习的特点*
简单来说机器学习的特性是从我们已经拥有的数据的特征(Data)和其对应的对照的答案(Label)寻找某种规则。Data和Label 帮助大家理解,后续我们会说到有的训练是没有Label也就是对照答案的,像无监督学习。
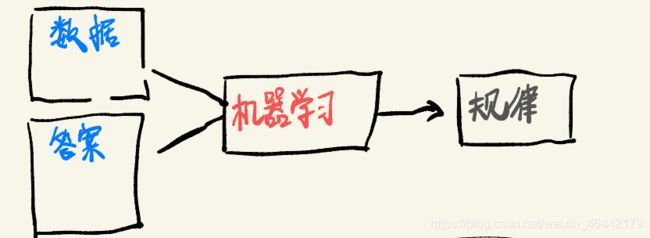
学术一点来说,机器学习是以计算机为平台,数据为研究对象,学习方法为中心的交叉学科,涉及的课程包括概率论、线性代数、信息论、等。
涉及的研究包括:
- 机器学习方法:开发新的学习方法。
- 机器学习理论: 探究机器学习方法的有效性和效率。
- 机器学习的应用: 利用模型解决实际问题。
2.机器学习的研究对象*
机器学习的研究对象,毋庸置疑是从数据出发的,提取数据特征,利用数据模型,发现数据中的规律。

我们来看一个例子,这个是Kaggle网上的拉面评分的数据集,每一行是一组拉面数据,我们可以看到像品牌名字,名称,生产规格和产地都是一行数据的数据特征(Feature)。
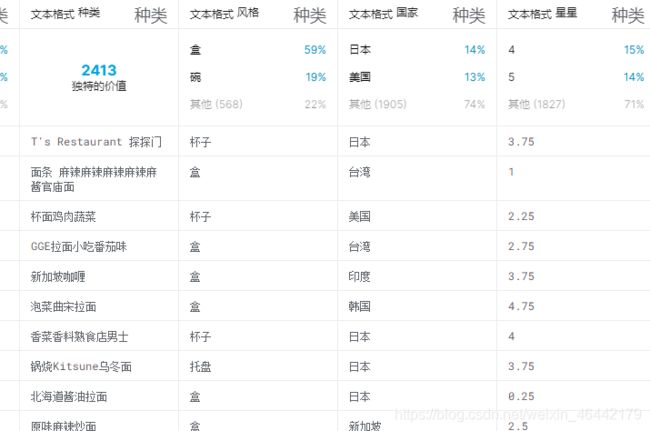
后续这张图我们可以看到,评分(星星)就是这一行数据对应的标签(Label),因为我们利用这组数据的目的是从每一行拉面数据拥有的各个特征中找出影响评分的关系。如果我们将这整个列表的数据应用到某个模型中训练,我们就可以得到一个可以预测拉面评分的模型,基于我们拥有的数据特征。
当然在现实生活中,我们会对数据进一步按照比例划分,例如**(8:2)**。这样做的结果是我们会拥有训练集和验证集两部分,然后我们可以在训练集上训练,在验证集上验证模型的泛化能力,也就是好坏。如果验证结果好,我们就得到了一个可以应用的‘ 规律 ’。之后我们每得到一个新的数据样本(新的训练集),放入我们训练好的模型中,都可以得出一个预测输出值。

另外注意一点,在实际场景中,机器学习的数据可能是多样的,例如图像、文本、语音等。一般在我们在做机器学习之前会对这些数据统一格式类型。例如矩阵。如果是文本类型,我们将各个文本进行分词处理,然后统计每个词在文中出现的频率值,这样就形成了一个词频矩阵,再比如给定的图像数据,我们将图片当成一个像素矩阵。
3.机器学习的分类
3.1. 按照学习方式分类
机器学习可以分为有监督学习、无监督学习和强化学习等。

- 有监督学习
有监督学习,是指带有Label的样本训练模型,然后利用该模型对新的未知结果做预测。例如刚才我们举得拉面评分的例子,评分就是我们的Label。常见的监督学习任务是分类(Classufy)和回归(Regression)。
分类:例如区分一张图片是猫还是狗,区分一片叶子还是树(数据是离散的)。
回归:例如预测未来股票的市场价格。今天的数据和明天的数据是有关联的(数据是连续的)。
- 无监督学习
在无监督学习中样本是没有Label的,也就是说训练集的结果标签是未知的。我们通过对这些没有Label的数据样本学习,来发现他们的内在规律。此类学习方法中比较常用的是聚类(Clustering)和降维(Dimension Reduction)。
聚类:聚类模型是将数据集划分为若干个不相交的子集,每个子集我们成为簇(Cluster)。这样的划分有什么结果呢,简单来说每个簇就对应一个类别。具体应用的时候,聚类问题可以作为一个单独的过程,用于寻找数据的内在结构分布(我们通常在二维坐标中直观的观察,每一个簇代表不同的颜色),又可以作为其他分类等其他学习任务的前驱过程和数据预处理。
那样本之间怎么评估呢? 我们希望簇之间能尽可能地不同,但是在同一个簇内尽可能相似。
降维: 有一定基础的小伙伴一定会知道,我们的样本多样,有时候数据的特征纬度很高但是数据稀疏,并且一些特征是多余的。这种情况我们称为维数灾难(Curese of Dimensionality)其会造成计算困难,还会对结果的精度造成影响。所以我们一般是要利用到降维的,通常我们利用数学变换关系(例如高斯核函数),将高维空间转换成低维子空间。在这个子空间中,样本密度大幅提升,也更容易进行后续学习。
- 强化学习
强化学习也称再励学习,评价学习。是从动物学习等理论发展而来的。
简单来说机器会自己不断的去尝试,采取一种趋利避害的策略,不断调整,最终机器会发现哪种行为能产生最大的回报。
机器会先选择一个初始动作作用于环境,环境接收到该动作后状态发生变换,同时产生一个信号(奖赏或惩罚)返回给机器,机器根据这个反馈和环境当前状态选在下一个动作,选择的原则是使奖赏概率增大。
强化学习在智能机器人及分析预测有许多应用,例如AlphaGo。

3.2. 按照任务分类
机器学习可以分为分类问题,回归问题,聚类问题和降维问题。
分类问题:像上面说过的图片分类,文本分类。
回归问题:利用回归分析原理,来确定我们数据的特征之间的依赖关系。上文我们提到过的股票预测例子,有兴趣的小伙伴可以自己查一下,以后我可以给大家做详细的例子。
聚类问题:聚类问题可以叫做群分析,将样本数据划分为簇,常见的聚类问题又市场分析,群体分析。
降维问题:简单来说从高维数据映射到地纬数据。常见的降维模型主成分分析(PCA)和线性判别分析(LDA)。

4. 机器学习的应用
机器学习等应用可用于人脸识别、垃圾邮件检测、自动驾驶、信用风险检测、语音识别等领域。

机器学习,深度学习,人工智能他们之间存在一定的关系,深度学习是机器学习的子集,而机器学习又是人工智能的子集。人工智能的概念相对于更广泛,除了机器学习算法的应用还有一些认知、心理、控制等领域算是一个综合性和交叉学科。

**
末尾
**
到目前为止,相信你应该对机器学习有一定的总体了解了吧,如果有问题欢迎给我留言,由于第一次谢博文还是希望大家能给一些支持,以后我会提供更加优秀的博文,相关领域感兴趣的也可以私信我。
引用
感兴趣的小伙伴还可以看看《机器学习基础》这本书,本文很多内容也参考这本书的总结。