NeRF原理解析
文章目录
- 引言
- NeRF资料
- 技术基础梳理
-
- 算法概览
- 用神经辐射场(Neural Radiance Field)来表示场景
- 基于辐射场的体素渲染算法
-
- 经典体素渲染算法
- 数值近似的方法
- 优化神经辐射场
-
- 位置信息编码(Positional encoding)
- 多层级体素采样
- 实现细节
- 时间消耗
引言
NeRF是2020年ECCV论文,本技术的提出是为了做新视角合成的研究工作。研究者借助深度学习技术实现了摄像机级别的逼真的新视图合成,展现了十分惊艳的效果。仅仅过去不到2年,关于NeRF的论文数量已经十分可观。相比于计算机视觉,尤其是相比于基于深度学习的计算机视觉,计算机图形学是比较困难、比较晦涩的。被深度学习席卷的计算机视觉任务数不胜数,但被深度学习席卷的计算机图形学任务仍然尚少。
除了本文,我还将继续介绍一些相关的改进或者应用。
NeRF资料
项目地址:
https://www.matthewtancik.com/nerf
论文地址:
https://arxiv.org/abs/2003.08934
开源代码地址:
TensorFlow实现:https://github.com/bmild/nerf
PyToch实现:https://github.com/yenchenlin/nerf-pytorch
官方数据地址:
https://drive.google.com/drive/folders/128yBriW1IG_3NJ5Rp7APSTZsJqdJdfc1
相关技术解析文章:
https://zhuanlan.zhihu.com/p/360365941
https://wandb.ai/sweep/nerf
技术基础梳理
算法概览
NeRF可以简要概括为用一个MLP(主要由全连层而非卷积层,加上激活层组成的)神经网络去隐式地学习一个静态3D场景,目的是实现复杂场景的任意新视角合成(渲染)。
为了训练网络,针对一个静态场景,需要提供包含大量相机参数已知的图片的训练集,以及图片对应的相机所处3D坐标,相机朝向(2D,但实际使用3D单位向量表示方向)。
使用多视角的数据进行训练,空间中包含真实场景的位置具有更高的密度和更准确的颜色,这鼓励神经网络预测一个连续性更好的场景模型。
以任意的相机位置+朝向作为输入,经过训练好的神经网络进行体绘制(Volume Rendering),即可以从渲染出图片结果了。

用神经辐射场(Neural Radiance Field)来表示场景
NeRF函数是将一个连续的场景表示为一个输入为5D向量的函数,包括一个空间点的3D坐标位置x=(x,y,z),以及方向(θ,ϕ);
输出为视角相关的该3D点的颜色c=(r,g,b),和对应位置(体素)的密度σ。
实践中,用3D笛卡尔单位向量d来表示方向,因此这个神经网络可以写作:ϜΘ:(x,d)→(c,σ)。

在具体的实现中,x首先输入到MLP网络中,并输出σ和一个256维的中间特征,中间特征和d再一起输入到额外的全连接层(128维)中预测颜色。
因此,体素密度只和空间位置有关,而颜色则与空间位置以及观察的视角都有关系。基于view dependent 的颜色预测,能够得到不同视角下不同的光照效果。
以下为神经网络的架构:
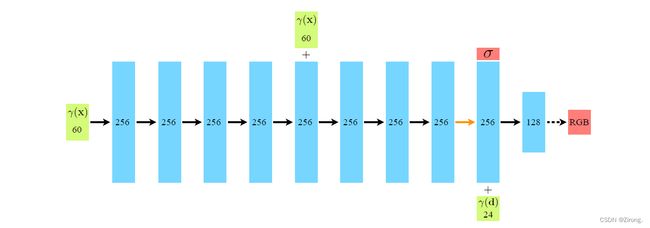
1、输入向量用绿色表示,中间隐藏层用蓝色表示,输出向量用红色表示; “+” 符号表示向量串联;黑色实线箭头表示隐藏层使用ReLU激活,橙色实线箭头表示隐藏层不使用激活函数,黑色虚线箭头表示隐藏层使用sigmoid激活函数。
2、输入数据x和d都先经过了位置信息编码(Position Encoding),即γ(∙)操作,将原始的输入数据映射到高频,能够使得网络更容易的理解并建模位置信息,提高渲染清晰度。
3、位置编码后的位置输入γ(x)经过8层256维的全连接ReLU层,包括将此位置信息接入到第5层的激活层的SKIP连接(代码中接入到激活之后);第9层用于输出体素密度σ和256维的特征向量,使用ReLU来保证σ不会包含负数值;该特征向量与经过位置编码的γ(d)串联,再经过一个128维的全连接层,最后输出与方向d相关的,在位置x的颜色预测。
4、论文中提到的PE操作的参数为:位置信息,L=10,视角信息,L=4;暂不清楚位置编码后的输入维度(60, 24)具体是怎么得来,但二者比值和论文的参数设置是相匹配的。
5、上图中网络输入的位置信息,指的是由各个相机原点出发的,经过对应图像中每一像素引起的射线,所经过的采样点位置,方向指该射线的方向;输出的体素密度σ和方向相关的颜色值c=(r,g,b),共同决定了该位置在后续渲染时所提供的对渲染结果的数值;上述网络中的权重/参数,为所有的像素射线共享。
基于辐射场的体素渲染算法
神经辐射场将一个场景表示为,空间中任意一个点(3D位置)的体素密度σ以及与视角相关的“辐射”颜色。
但当用一个相机去对这个场景成像时,所得到的2D 图像上的一个像素实际上对应了一条从相机出发的射线上的所有连续空间点。
我们需要通过渲染算法从这条射线上的所有点得到这条射线的最终渲染颜色。同时,为了保证网络可以训练,NeRF中需要采用可微的渲染方法。
经典体素渲染算法
体素密度σ(x)可以被理解为,一条穿过空间的射线,在x处被一个无穷小的粒子终止的概率,这个概率是可微分的,可以将其近似理解为该位置点的不透明度。
一个虚拟的相机沿着特定方向进行观测,其观测射线上的点是连续的,则该相机成像平面上对应的像素颜色,可以理解为由对应射线经过的点的颜色积分得到。
将一条射线的原点标记为o,射线方向(即相机视角)标记为d,则可将射线表示为r(t)=o+td,t的近端和远端边界分别为tn和tf。
可将这条射线的颜色,用积分的方式表示为:

其中,T(t)表示的是射线从tn到t这一段的累计透明度,即,该射线从tn到t都没有因击中任何粒子而被停下的概率,具体写作:

在连续的辐射场中,针对任意视角进行渲染,就需要对穿过目标虚拟相机的每个像素的射线,求取上述颜色积分,从而得到每个像素的颜色,渲染出该视角下的成像图片。
数值近似的方法
在实际应用中,我们并不可能用NeRF去估计连续的3D点信息(射线上的连续点),这就需要数值近似的方法。论文中先提出了使用求积法(Quadrature)近似连续积分的方法。
确定性求积(Deterministic Quadrature)通常用于渲染离散体素网格,一般在需要求积的区域均匀采样N个点进行近似计算,但这样做会使MLP只在一系列确定的离散点上学习,从而极大限制了神经辐射场的分辨率。
因此,作者提出了一种分层抽样(Stratified Sampling)的方法:首先将射线需要积分的区域[tn,tf]均匀分为N份,再在每个小区域进行均匀随机采样:

这个方法实现了,在只采样离散点的前提下,使MLP可以在用一种连续的方式进行优化,从而保证了辐射场对场景表达的连续性,如下图所示:

基于这些采样点,可以将上面的积分简化为求和的形式:

其中,δi=ti+1−ti为两个近邻采样点之间的距离,此处T(t)改写作:

这种从所有采样点的(ci,σi)集合求和得到射线渲染颜色的方法也是可微分的,并且可以简化为传统的透明度混合算法,其中alpha值αi=1−exp(−σiδi)。
优化神经辐射场
论文继续介绍了NeRF中两个重要的创新点,使得神经辐射场可以表达高分辨率的复杂场景。
位置信息编码(Positional encoding)
作者发现,直接将位置和视角作为网络的输入得到的结果,在表达高分辨率的场景时表现不佳,较为模糊,而使用位置信息编码的方式将输入先映射到高频可以有效地解决这个问题。
因此,将ϜΘ重写成由两组函数组成:ϜΘ=Ϝ′Θ∘γ,其中Ϝ′Θ仍为常规MLP网络,需要通过训练学习得到,而γ用于将输入映射到高维空间中,论文中使用的是R→R2L的正余弦周期函数的形式:
![]()
对于位置和视角信息,论文先将其归一化到NDC(normalized device coordinate)空间中,使得其数值上落在[-1,1]间,再对其进行PE操作。
对位置和视角信息使用不同的参数L,在本文中对于 γ(x)设置 L=10;对于γ(d)设置 L=4。
多层级体素采样
NeRF的渲染策略是对相机出发的每条射线都进行N个采样点的求和计算。
这个策略效率是较低的,因为大量的对渲染没有贡献的空的或被遮挡的区域仍要进行采样计算,这样占用了过多的计算量。
作者提出按照对最终渲染的贡献比例进行采样,设计了一种“coarse to fine”的多层级体素采样方法,同时优化coarse和fine两个网络。
首先,使用分层采样的方法先采集较为稀疏的Nc个点,在这些采样点上计算coarse网络的渲染结果,改写前述的离散求和函数:
 ,其中
,其中![]() ,并对ωi进行归一化:
,并对ωi进行归一化:
归一化后的ωi可以看作是沿着射线方向的概率密度函数,如下左图所示。通过这个概率密度函数,我们可以粗略地得到射线方向上物体的分布情况:

接下来,基于这个概率密度函数,使用逆变换采样(inverse transform sampling)方法,再采样出Nf个点,如上右图所示。
这个方法可以从包含更多可见内容的区域中得到更多的采样点,然后在Nc+Nf的采样点集合上,计算fine网络的渲染结果。
这达到了类似按权重采样的效果,作者将采样点视为非均匀的离散化,而非对每个点进行独立的概率估计。
实现细节
针对不同的场景,需要进行独立的训练。
需要的数据集由针对场景采集的多视角的RGB图像、对应的相机位姿、相机内参、以及场景的近端/远端边界信息(部分可从Colmap得到)。
在训练中的每一次迭代,从数据集中所有像素中随机选择,从对应像素点出发的射线,通过上述多层采样法得到coarse和fine的采样点,再通过体素渲染法得到对应的渲染结果。
训练损失直接定义在渲染结果上的L2损失(同时优化coarse和fine网络):

时间消耗
实现中使用4096个射线作为一个batch,Nc = 64, Nf = 128,针对一个场景一般需要100300K次迭代,在英伟达V100的显卡上训练12天。
推理1920*1080分辨率的图像,NeRF的速度为50s/帧(V100)。