论文阅读笔记----《From Easy to Hard: Two-stage Selector and Readerfor Multi-hop Question Answering》
Abstract
多跳问答 (QA) 是一项具有挑战性的任务,要求 QA 系统对多个文档执行复杂的推理,并提供支持事实和准确答案。现有的工作倾向于利用基于图的推理和问题分解来获得推理链,这不可避免地给系统带来了额外的复杂性和累积误差。为了解决上述问题,我们提出了一个简单而有效的新颖框架,从易到难 (FE2H),以消除分散注意力的信息并为多跳 QA 任务获得更好的上下文表示。受迭代的文档选择过程和人类渐进式学习习惯的启发,FE2H 将文档选择器和阅读器按照易到难的方式分为两个阶段。具体来说,我们首先选择与问题最相关的文档,然后利用该问题与该文档一起选择其他相关文档。至于 QA 阶段,我们的阅读器首先在单跳 QA 数据集上进行训练,然后转移到多跳 QA 任务中。我们在流行的多跳 QA 基准 HotpotQA 上全面评估我们的模型。实验结果表明,我们的方法在 HotpotQA(干扰器设置)排行榜中的表现优于所有其他方法。
1 Introduction
问答(QA)是自然语言理解中流行的基准任务,旨在教机器根据给定的上下文回答问题。早期的 QA 数据集,如 SQuAD (Rajpurkar et al., 2016a) 主要侧重于评估每个问题使用单个文档找到答案的能力。随后,出现了为每个问题提供多个文档的更具挑战性的数据集(Joshi 等人,2017;Dunn 等人,2017)。但是,这些数据集的大多数问题仍然可以仅使用一个文档来解决。最近,构建了许多需要对多个文档进行多跳推理的数据集(Welbl 等,2018;Talmor 和 Berant,2018;Y ang 等,2018)。在本文中,我们专注于 HotpotQA(Yang 等人,2018 年),它是具有代表性的多跳 QA 基准之一。HotpotQA(Y ang et al., 2018)中的每个问题都提供了一组文档,其中包括相关和不相关的文档。除了确切的答案范围之外,HotpotQA(Yang 等人,2018 年)还提供了支持句子,作为训练和评估 QA 系统的解释。
遵循当前多跳 QA 的主流管道(Fang 等人,2020;Tu 等人,2020;Wu 等人,2021),我们提出的框架还包括一个用于最小化分散注意力的信息的选择器和一个阅读器提供确切的答案和解释。至于选择器的设计,大多数早期的作品都忽略了任务的多跳性质,独立地处理候选文档或句子。为了解决这个问题,最近的工作包括 SAE (Tu et al., 2020) 和 S2G (Wu et al., 2021) 应用多头自我注意 (MHSA) 层来鼓励文档间交互。然而,他们仍然使用预训练语言模型 (PLM) 在 MHSA 层之前对每个文档进行单独编码,这无法充分利用 PLM 的强大建模和自然语言理解能力,从而导致交互受限。请注意,尽管与 SAE 相比,S2G 进一步采用了以粗选文档文本为馈送的级联检索,但这些选择器旨在一次找到所有相关文档,而忽略了多跳跃推理。
与上述选择器不同,我们提出的选择器由两个阶段组成,在一个阶段选择一个文档。具体来说,我们首先选择与问题最相关的文档,然后根据问题和之前选择的文档来选择另一个。图1展示了我们在回答多跳问题时这种两阶段文档选择过程的一个例子,这表明我们的两阶段选择器与人类的推理过程表现出极大的一致性。具体来说,我们首先根据问题到达文档D10,这表明 "物理学的七堂简明课是由Carlo Rovelli写的"。接下来,我们利用问题和D10号文件来识别包含 "Carlo Rovelli自2000年以来一直在法国工作 "的文件。我们的实验证明,在由易到难的两阶段方式的帮助下,即使是简单地在PLM上增加一个二进制分类层,也可以达到很强的性能。

图 1:HotpotQA 基准测试中的多跳 QA 示例。图示的推理过程与我们从易到难的两阶段文档选择相呼应。
在文档选择之后,过滤后的上下文被传递给问题回答模块,即读者。许多现有的工作侧重于引导读者通过精心设计的管道来模仿人类的推理过程,这些工作可以大致分为两类。一类是基于图的方法,包括将句子视为图节点的SAE(Tu等人,2020)和用不同颗粒度的节点建立分层图的HGN(Fang等人,2020)。然而,这些方法需要额外的技术,包括命名实体识别和图形建模,这不可避免地导致复杂性的增加和错误的积累。由于这些缺点,已经有作品证明,图建模可能不是必不可少的(Shao等人,2020)。因此,为了简单起见,我们也没有利用任何基于图的推理方法。另一类是问题分解方法,如DECOMPRC(Min等人,2019)和ONUS(Perez等人,2020),它们将一个多跳的困难问题映射为许多单跳的简单子问题。虽然我们很欣赏将困难的任务分解成容易的任务的想法,但子问题的生成带来的难度和复杂性是不容忽视的。
受基于问题分解的方法和儿童通常从非常简单的问题中学习的经验的启发,我们提出了这样一个问题:让模型直接从头开始学习回答多跳问题是否太难和太混乱。因此,我们的读者首先在较简单的单跳数据集SQuAD(Rajpurkar等人,2016b)上进行训练,然后再进行较难的多跳QA任务。我们假设在单跳数据集上的训练可以用更好的参数初始化模型,使模型更容易回答多跳问题。此外,从易到难的学习过程与广泛接受的概念是一致的,即技能的获得应该有一个渐进的过程(Liu等人,2017;Roads等人,2018;Song等人,2019)。我们的实验说明,两阶段的读者有效地提高了性能,这验证了我们的假设。
我们工作的主要贡献总结如下:
- 我们提出了一个简单而有效的多跳QA框架,称为FE2H,其中文档选择器和阅读器都按照从易到难的方式分为两个阶段。
- 我们引入了一个新颖的文档选择模块,该模块通过简单地在PLM上添加一个预测层,迭代地执行二进制分类任务来选择相关的文档。
- 所提出的阅读器首先在单跳QA数据集上进行训练,然后转入多跳QA任务,其灵感来自于人类的渐进学习过程。
- 我们在流行的多跳QA基准测试HotpotQA上全面评估了我们的模型。实验结果表明,所提出的FE2H在所有指标上都能以很大的幅度超过以前的先进技术。
2 Related Work
QA的选择器 句子或文档选择器旨在最大限度地减少噪声信息,这已被证明对提高QA系统的性能和效率很有效。研究中提出了SQuAD的句子选择器(Rajpurkar等人,2016b),因为问题可以在一个句子中回答。至于多跳QA,(Wang等人,2019)和(Groeneveld等人,2020)只是将文档和句子分开处理,忽略了它们之间的互动。因此,SAE(Tu等人,2020)和S2G(Wu等人,2021)附加了一个MHSA层以鼓励文档互动。为了获得更精细的结果,S2G(Wu et al., 2021)进一步采用了另一个级联段落检索模块,该模块将所选文件的文本作为输入,随后探索它们之间更深层次的关系。由于SAE和S2试图同时定位所有的相关文档,所以天真的二元分类器不能很好地表现。因此,SAE(Tu等人,2020)和S2G(Wu等人,2021)分别将分类目标重新表述为排名和打分目标,以符合选择器的排名性质。与上述选择器不同的是,我们提出了一个新颖的两阶段选择器,它既不独立也不同时选择文档。
多跳QA的阅读器 现有的多跳QA阅读器可以大致分为两类:基于中间结果的推理和基于图形的推理。第一类可以进一步按中间结果是以隐藏状态还是自由形式的文本表示来分组。对于前一组,QFE(Nishida等人,2019)通过在每一步更新RNN隐藏状态向量来识别相关句子,其他的则迭代更新查询和上下文的表示向量来获得最终答案(Das等人,2018;Feldman和El-Y aniv,2019)。后一类的代表作品主要通过首先分解原始问题或生成子问题,然后采用现成的阅读器来获得中间文本结果(Qi等人,2019;Min等人,2019;Perez等人,2020)。第二类是利用图神经网络对构建的图进行推理。DFGN(Qiu等人,2019)和CogQA(Ding等人,2019)专注于实体图,而SAE(Tu等人,2020)将句子作为图节点来识别支持句子。此外,(Tu等人,2019)、HGN(Fang等人,2020)和AMGN(Li等人,2021)对具有不同类型的节点和边的异质图进行推理。然而,最近有一些工作质疑图结构是否有必要。QUARK(Groeneveld等人,2020)、C2F阅读器(Shao等人,2020)和S2G(Wu等人,2021)证明了简单无图阅读器的性能与基于图的推理方法相当。C2F阅读器(Shao等人,2020)进一步声称,图的注意力可以被视为自我注意力的一个特例。在本文中,我们提出了一个简单的遵循两阶段流水线的阅读器,并且不需要任何反复的状态更新和图形建模。
3 Proposed Framework
我们选择HotpotQA(Y ang等人,2018)的干扰因素设置作为我们的测试平台,其中每个问题配备了2个相关文件和8个干扰因素。我们还提供了一个支持性的句子列表和一个可以是准确的文本跨度或 "Y es/No "的答案,以供评估。我们提出的框架概述见图2。按照传统的多跳质量保证系统的管道,我们首先利用文档选择模块来构建几乎无噪音的上下文,然后将它们传递给下游的问题回答模块,以同时提取支持事实和答案跨度。
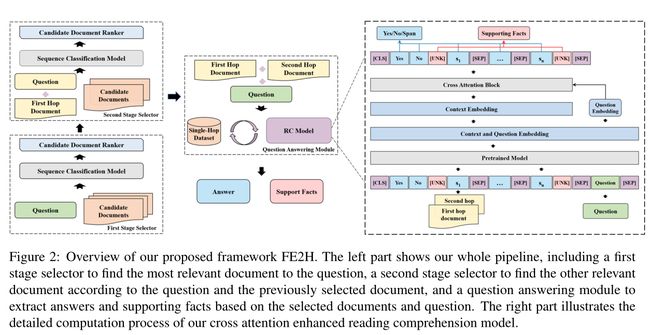
图 2:我们提出的框架 FE2H 的概述。左边部分展示了我们的整个管道,包括一个第一阶段选择器,用于查找与问题最相关的文档,第二阶段选择器根据问题和先前选择的文档查找其他相关文档,以及一个问答模块,用于提取基于所选文件和问题的答案和支持事实。右侧部分说明了我们的交叉注意力增强阅读理解模型的详细计算过程。
3.1 Document Selection Module
在这个阶段,我们的目标是过滤干扰信息,为下面的问题回答模块生成高质量的上下文,即几乎没有噪音的上下文。需要注意的是,虽然有很多作品在提取支持性句子和答案时使用图建模和问题分解进行了循环推理,但现有的选择器仍然是独立或同时提取相关文档,这在第一节和第二节已经讨论过。因此,我们假设递归推理方式也应该应用于更大的颗粒度,即文档级别。回顾一下,当我们回答一个多跳问题时,在大多数情况下,我们首先选择与问题最相关的文档,并使用这个文档与问题一起寻找另一个文档。受此启发,我们将文件选择分为两步,一步一个文件,这与现有的方法不同。
第一阶段 在这个阶段,我们的目标是选择与问题最相关的文档。我们将序列“[CLS] + question + [SEP] + document + [SEP]”提供给 PLM ELECTRA(Clark 等人,2020),并投影令牌“[CLS]”的输出以计算相关分数 P (d|q) 对于每个候选文档 d 和问题 q。我们将所有包含支持事实的文档标记为相关的,并将二元交叉熵损失为:
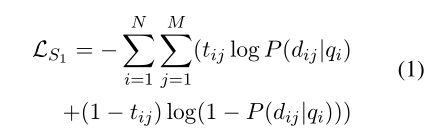
其中qi是数据集中的第i个问题,dij是qi的第j个候选文档,tij是问题-文档对(qi,dij)的标签,N是问题的数量,M是每个候选文档的大小设置,HotpotQA 为 10。我们选择具有最高相关性分数的文档并将所选文档表示为 p1。也就是说,给定问题 qi,pi1 = arg max j P (dij|qi)。
第二阶段 此阶段的目的是根据先前的结果找到其他相关文档。因此,我们生成输入为“[CLS] + question + [SEP] + document1 + [SEP] + document2 + [SEP]”,其中 document1 是第一步选择的文档,document2 是另一个候选文档。我们像上一步一样计算候选文档的相关性分数,记为 P(d|q, p)。二元交叉熵损失计算为:
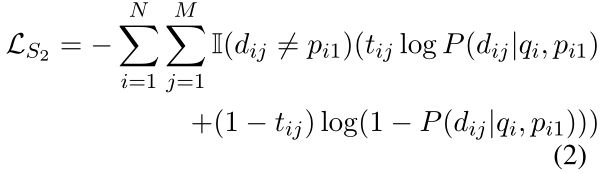
其中 ![]() 是指标函数。同样,我们选择此步骤中相关性得分最高的文档并将其表示为 p2。
是指标函数。同样,我们选择此步骤中相关性得分最高的文档并将其表示为 p2。
在两阶段检索之后,将每个问题的选定文档连接起来并传递给下面的问答模块,作为高质量的上下文。
3.2 Question Answering Module
多任务模型 在这个阶段,我们实现了一个多任务模型来提取多跳问题的答案和支持事实,如图 2 所示。首先,我们将上下文和问题连接为一个序列,然后使用名为 ELECTRA (Clark et al., 2020) 的 PLM 来获取输入文本的上下文表示。随后,我们利用交叉注意力来增强上下文和问题之间的交互,以获得更好的上下文嵌入。最后,采用多任务学习方法,通过简单地添加线性预测层,共同提取答案和支持句子。
首先,我们应该构建输入序列作为 ELECTRA 的输入(Clark et al., 2020)。考虑到“是/否”答案案例,“是”和“否”标记被添加到序列的开头。此外,我们在上下文中的每个句子之前添加一个“[UNK]”,其上下文表示用于支持句子分类。因此,我们的输入序列可以表述为“[CLS] + yes + no + context + [SEP] + question + [SEP]”。我们将输入的 ELECTRA 输出表示为 H = [h1, · · · , hL] ∈ RL×d,上下文输出表示为 Hc = [h1, · · · , hS] ∈ RS×d,问题输出表示为 Hq = [hS+1, · · · , hL] ∈ RT ×d ,其中 L 是输入序列的长度,S 是上下文的长度,T = L - S 是查询的长度,d 是ELECTRA 的隐藏向量维度。
为了提高 QA 性能,我们进一步添加了交叉注意力交互模块,以增强上下文和查询表示之间的交互。同时,为了在训练过程中获得更好的结果并使收敛更快,我们使用了两个交叉注意力块,一个带有层归一化,一个没有层归一化。交叉注意力计算为:
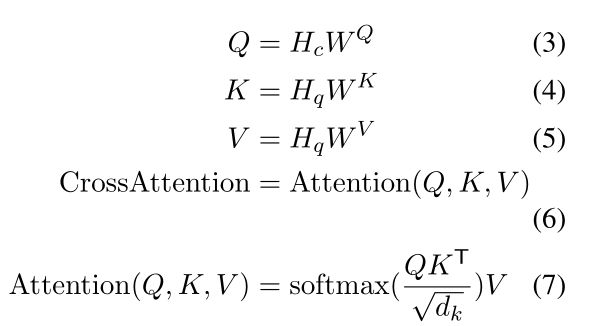
为了提取答案跨度,我们利用上下文表示上的线性预测层来识别答案的开始和结束位置。相应的损失项分别表示为 Lstart 和 Lend。至于支持事实预测,我们在每个句子之前添加的“[UNK]”的输出上使用线性二元分类器来确定句子是否相关。支持事实的分类目标表示为 Lsf 。最后,我们共同优化上述目标为:
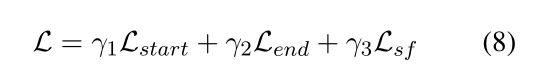
两阶段阅读器 如第 1 节所述,我们假设在多跳 QA 任务上直接微调 PLM 可能对模型来说过于困难和混乱。因此,该模型可以用单跳快捷方式回答多跳问题,即将问题与单个句子进行单词匹配(Jiang and Bansal,2019)。因此,我们首先在单跳 QA 数据集 SQuAD(Rajpurkar 等人,2016b)上训练我们的模型,然后将模型转移到多跳 QA 任务。我们假设单跳 QA 任务优化的参数比随机初始化的参数要好得多。因此,在学习单跳 QA 任务后,模型趋向于更快地收敛并获得更高的性能。请注意,单跳和多跳阶段的模型结构是相同的。
4 Experiments
4.1 Dataset
我们在 HotpotQA 的干扰器设置上评估我们的模型(Yang 等人,2018 年)。 HotpotQA 由 113k 基于维基百科和众包的问答对组成,包括 90K 训练示例、7.4K 开发示例和 7.4K 测试示例。
在干扰器设置中,数据集中的每个问题都提供一小组文档,其中包含两个支持文档和八个不相关文档。 HotpotQA (Yang et al., 2018) 还为每个问题提供了一个支持句子的列表,鼓励模型解释预测。精确匹配 (EM) 和 F1 分数用于评估两个任务的模型,联合 EM 和 F1 分数用于评估整体性能。我们的模型在测试集上的表现是通过在开发集上提交我们最好的模型来获得的。由于测试集不可用,我们报告了我们在开发集上的综合实验的性能。
4.2 Implementation Details
我们的模型是基于 Hugging Face (Wolf et al., 2020) 的转换器实现的,我们采用 ELECTRA 和 ALBERT 作为我们的 PLM 来获得问题和上下文的上下文嵌入。我们的实验都是在 2 或 3 个 NVIDIA A100 GPU 上进行的。下面列出了我们的两阶段选择器和读取器的实现细节。
两阶段选择器 我们分别用一个基本版本和一个大版本的 ELECTRA 训练两个文档选择器。由于资源限制,文档选择的消融仅在 ELECTRA-base 上进行。 epoch 数设置为 3,batch size 设置为 12。我们使用 BERT-Adam 进行优化,学习率为 2e-5。我们两个不同阶段的选择器的超参数是相同的,而模型参数是不同的并且是按顺序训练的。
两阶段阅读器 至于问答阶段,我们在 ELECTRA 模型上训练 FE2H,批量大小为 16,带有 2 个 NVIDIA A100 GPU,学习率为 1.5e-5,预热率为 0.1,L2 权重衰减为 0.01。此外,我们使用 ELECTRAlarge 作为这一阶段的 PLM。训练一个单一阶段的阅读器大约需要每个 epoch 2 小时,总共需要 6.5 小时。我们在 ALBERT 模型上训练 FE2H,批量大小为 12,使用 3 个 NVIDIA A100 GPU,学习率为 1.0e-5,预热率为 0.1,L2 权重衰减为 0.01。此外,我们使用 Albert-xxlarge-v2 作为这一阶段的 PLM。训练一个阶段的阅读器总共需要大约25个小时。
4.3 Experimental Results
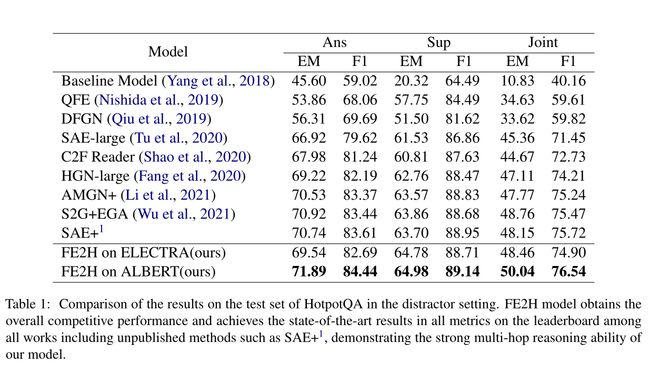
HotpotQA 的结果 表 1 显示了已发布的高级方法在干扰设置中的 HotpotQA 测试集上的性能。尽管我们的模型很简单,但我们在 ALBERT 上的 FE2H 是排行榜上最先进的模型1。我们的模型在所有指标上都取得了最好的结果,展示了我们模型强大的多跳推理能力。在所有已发表的方法中,联合 EM 改进为 1.28%,联合 F1 改进为 1.07%。在包括 SAE+1 在内的所有提交的方法中,联合 F1 改进为 0.82%。
文档选择 我们将我们的选择器与三个已发表的高级作品中的一个进行比较,即 HGN、SAE 和 S2G,它们也应用精心设计的选择器为下游读者检索相关文档。我们使用 EM 和 F1 来评估文档选择器的性能。如表 2 所示,我们的选择器优于这三个强基线。与之前的最佳选择器相比,即使是我们的选择器的基本版本也实现了具有竞争力的性能。
4.4 Ablation
两阶段选择器消融 两阶段选择器消融的结果如表 3 所示。为了证明两阶段选择器的有效性,我们移除了第二阶段并评估结果。结果说明,给定的输出第一阶段,无论我们选择前 2 个文档,还是选择得分高于某个阈值的文档,EM 和 F1 得分都显着下降。请注意,SAE 和 S2G 都认为包含答案跨度的文档(即黄金文档)对于下游任务更重要,因此为这些文档分配更高的分数。但是,我们假设相关文档具有同等重要性,尤其是对于我们文档选择的第一阶段。由于我们没有将二元分类目标重新表述为 SAE 和 S2G 等与排名相关的目标,因此我们为黄金文档分配更大的权重以验证这一假设。结果表明,在第一阶段重新分配相关文档的权重后,性能显着下降。值得指出的是,与两阶段设置相比,单阶段设置的性能下降更多,表明直接引导选择器识别黄金文档是不可行的,因此两个相关文档同等重要。
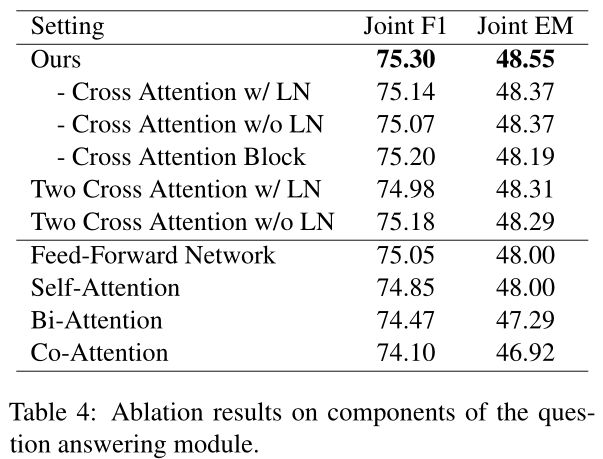
QA 模型消融 由于计算资源的限制,我们只使用单阶段阅读器,即没有在单跳 QA 数据集上训练的阅读器,来执行 QA 模型结构的消融,如表 4 所示。具体而言,我们研究问题和上下文之间的不同交互层对提取支持事实和答案的性能的影响。
除了交叉注意力层之外,我们还尝试探索其他层对增强问题和上下文之间交互的影响,包括自注意力层、涂层注意力层、双向注意力层和前馈层。这些层在实验期间直接添加到 PLM。请注意,我们没有交叉注意块的 QA 模型相当于直接根据 PLM 的输出预测结果,即基线 QA 模型,而我们的实验表明,与基线相比,添加这些层都会导致性能下降。对于这些退化,我们的直观解释如下。由于前馈网络仅将上下文嵌入作为输入,因此禁止了问题与上下文之间的交互,这可能导致性能下降。至于 self-attention,回想一下 PLM 已经包含许多 self-attention 层,因此从头开始学习额外的 self-attention 层可能无济于事。此外,由于双向注意 (Seo et al., 2017) 和共同注意 (Xiong et al., 2017) 建模的交互比自我注意和交叉注意的交互更复杂,我们认为它很难训练具有许多预训练自注意力层和随机初始化的双向注意力或共同注意力层的模型。
然而,总而言之,我们得出的结论是,尽管我们的交叉注意力块提高了性能,但改进并不显着,许多其他交互机制甚至会对性能产生负面影响。也就是说,无需任何额外的计算,直接微调的 PLM 就可以在下游任务上获得有竞争力的性能。
两阶段阅读器消融 为了证明阅读器两阶段方式的有效性,我们使用较小的 PLM BERT 基础(Devlin 等人,2019)和较大的 PLM ELECTRA-large(Clark 等人)进行消融研究., 2020)。结果如表 5 所示,表明两阶段方式在 BERT(Devlin 等人,2019)上比 ELECTRA 带来了更显着的性能提升。具体来说,仅在多跳 QA 数据集上进行训练时,联合 F1 下降 1.45%,联合 EM 下降 2.04%。我们假设这是因为像 ELECTRA 这样的大型 PLM 学习了更多的常识并获得了更强的自然语言理解能力,因此在单跳 QA 等简单任务上进一步微调可能帮助有限。而对于像 BERT(Devlin 等人,2019)这样的小型 PLM,单跳 QA 数据集可以为 PLM 提供更多特定于任务的知识,并有效地弥合 PLM 和多跳 QA 任务之间的差距。因此,我们推荐使用两阶段阅读器,尤其是在资源有限且只允许使用小型 PLM 的情况下。
随后,我们使用单跳和多跳 QA 数据集进行实验,但使用不同的训练策略。如表 5 所示,当我们同时执行单跳和多跳 QA 任务时性能下降,这表明我们的两阶段阅读器的性能提升不仅是通过使用更多标记的 QA 对带来的,而且还带来了由易到难的两阶段方式。请注意,仅在第一阶段使用单跳数据集并在第二阶段使用两个数据集也会导致性能下降。我们假设这是因为一旦模型学会了简单的任务,在下一步中将这两个任务的数据集提供给它几乎没有用,甚至可能对训练结果产生负面影响。
5 Conclusion
我们提出了 FE2H,这是一个简单而有效的多跳 QA 框架,它将文档选择和问答分为两个阶段,遵循一种易到难的方式。实验结果表明,由于输入长度的限制,我们不能一次将所有候选文档都提供给 PLM,因此在文档选择阶段考虑多跳推理性质可以显着提高整体性能。至于随后的 QA 阶段,由于 PLM 的强大自然语言理解能力,我们简单的两阶段阅读器的性能优于没有任何图结构和显式推理链的最先进方法。我们希望这项工作可以在高级 PLM 的帮助下促进更简单但功能强大的多跳 QA 方法。