论文阅读笔记:GoogLeNet Inception 网络
论文阅读笔记:GoogLeNet Inception 网络
inception_v1 论文下载地址:inception_v1 Going deeper with convolutions
inception_v2 论文下载地址:inception_v2 Accelerating Deep Network Training by Reducing Internal Covariate Shift
inception_v3 论文下载地址:inception_v3 Rethinking the Inception Architecture for Computer Vision
inception_v4 论文下载地址:inception_v4 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
本篇博客主要讲解四篇来自 Google 的论文,即 inception 网络
本文主要包含如下内容:
- 论文阅读笔记GoogLeNet Inception 网络
- inception_v1 Going deeper with convolutions
- 核心思想
- 网络结构
- GoogleNet
- inception_v2 Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 核心思想
- inception_v3 Rethinking the Inception Architecture for Computer Vision
- 核心思想
- inception_v4 Inception-v4 Inception-ResNet and the Impact of Residual Connections on Learning
- 核心思想
- 實驗結果
- inception_v1 Going deeper with convolutions
inception_v1 Going deeper with convolutions
核心思想
论文将1x1,3x3,5x5的 conv 和3x3的 pooling,stack 堆叠在一起,一方面增加了网络的 width 宽度,另一方面增加了网络对尺度的适应性;
论文将全连接和一般的卷积转换为稀疏连接,构建了 inception 结构。一方面是因为现实中的生物神经系统的连接是系数的,另一方面对大规模神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。Hebbian赫补原则有力地支持了这一点: fire together,wire together。即如果神经元的激活条件相同,它们会彼此互联。
网络结构
我们常说的 inception 基础网络结构如下:

网络结构说明:这种网络结构,一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性。
1. 采用不同大小的卷积核意味着不同大小的感受野,最后合并为单一向量作为输出,即融合不同的尺度特征。主要考虑多个不同size的卷积核能够增强网络的适应力。
2. 卷积核大小为1*1,3*3和5*5,设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后就可以通过聚合操作合并。
3. 由于池化网络的重要性,所以inception网络嵌入了pooling。
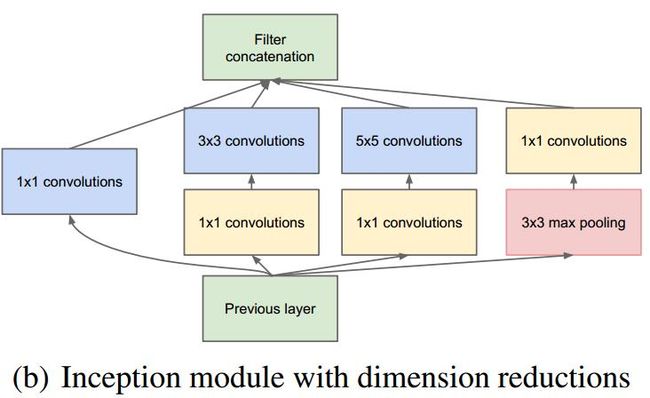
改进后网络结构如上图:这里主要使用了1*1的卷积操作,这里我们详细介绍一下1*1卷积操作的作用:
1. 采用1*1卷积核进行降维,例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
2. 1*1卷积核还有一个作用就是线性修正激活。
GoogleNet
在介绍了相关网络的模型之后,我们定义网络 GoogleNet,这个网络使用传统的网络和 Inception 块堆叠而成,具体操作如下:

在底层时候仍然用传统的方式,高层用Inception块叠加。
用Average pooling代替传统的FC层。
为了解决梯度弥散的问题,在4a和4d的后面添加辅助loss,该loss仅在训练的时候以一定的weight参与梯度传递,而在test的时候不用。
inception_v2 Accelerating Deep Network Training by Reducing Internal Covariate Shift
核心思想
论文中加入了BN层,减少了InternalCovariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,从而增加了模型的鲁棒性,可以以更大的学习速率训练,收敛更快,初始化操作更加随意,同时作为一种正则化技术,可以减少dropout层的使用。
用2个连续的3*3 conv替代inception模块中的5*5,从而实现网络深度的增加,网络整体深度增加了9层,缺点就是增加了25%的weights和30%的计算消耗。

参考博客
使用 Batch Normalization 的原因:在训练深层神经网络的过程中,由于输入层的参数在不停的变化。因此,导致了当前层的分布在不停的变化,这就导致了在训练的过程中,要求learning rate要设置的非常小。另外,对参数的初始化的要求也很高。作者把这种现象称为internal convariate shift。
Batch Normalization的提出就是为了解决这个问题的。BN 在每一个 training mini-batch 中对每一个 feature 进行 normalize。通过这种方法,使得网络可以使用较大的 learning rate。总结起来:BN解决了反向传播中的梯度弥散和爆炸问题,同时使得weight的更新更加稳健,从而使网络的学习更加容易,减少了对weight初始化的依赖和可以使用更大的学习速率。(扩大网络的同时又尽可能地发挥计算性能)

论文通过 mini-batch 来对相应的 activation 做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1. (即将某一层输出归一化)而最后的 scale and shift 操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入,从而保证整个 network 的 capacity。
源码解析:caffe官方将BN层拆成两个层来实验,一个是batch_norm_layer.c
pp,一个是scale_layer.hpp。相关源码可以在caffe源码中查看。
/*************************/
//将BN层加入到conv层和Relu层之间即可
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2b"
name: "res2a_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "bn2a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "scale2a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "res2a_branch2b_relu"
type: "ReLU"
}inception_v3 Rethinking the Inception Architecture for Computer Vision
核心思想
论文将7*7分解成两个一维的卷积(1*7,7*1),3*3也是一样(1*3,3*1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,更加精细设计了35*35/17*17/8*8的模块。
论文增加网络宽度,网络输入从224*224变为了299*299。

具体的相关操作,读者可以参考原文。
inception_v4 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
核心思想
Inception v4主要利用残差连接(Residual Connection)来改进v3结构,代表作为,Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4
resnet中的残差结构如下,这个结构设计的就很巧妙,简直神来之笔,使用原始层和经过2个卷基层的 feature map 做 Eltwise

實驗結果
将 Inception 模块和 ResidualConnection 结合,提出了Inception-ResNet-v1,Inception-ResNet-v2,使得训练加速收敛更快,精度更高。
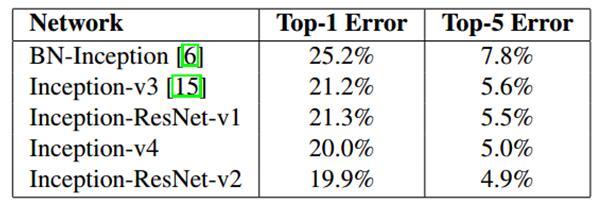

设计了更深的Inception-v4版本,效果和Inception-ResNet-v2相当。
Inception-v4 网络的输入大小和V3一样,还是299*299