FPGA HLS 卷积神经网络软硬件映射
实现思路
实现两个子函数:
一个负责卷积与Relu
一个负责池化
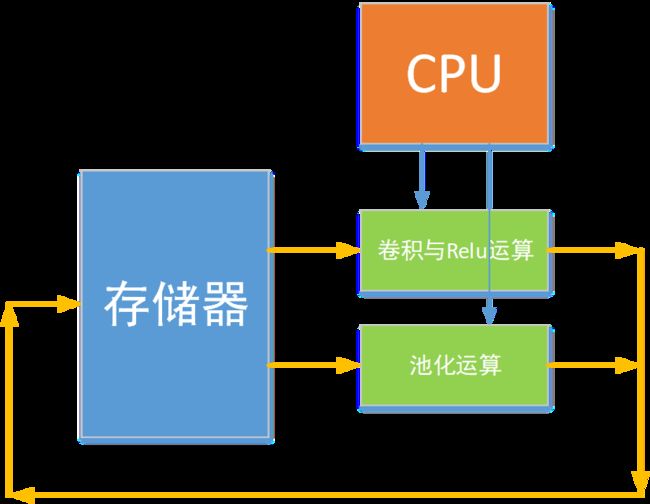
全连接可以转化为卷积,或者或全连接是特殊的卷积
当卷积核与输入特征相同,stride和padding为0时,卷积核的个数是输出的维度,也就是全连接的输出维度

量化
把权重的浮点数量化为定点数,需要获取权重的精度范围
根据输入的数据,对特征的浮点数量化为定点数,需要获取特征的精度范围
步骤
-
tensorflow完成训练与量化,导出
- 确定特征和权重的小数点位置
-
PYNQ工程开发
- 为权重申请空间,初始化权重空间
- 为特征申请空间
- 将测试图片放入网络的输入特征节点
- 调用硬件逐层完成网络的运算
- 读出网络的输出节点,对其输出值进行解析
训练与量化

训练
input_data.py
# Copyright 2015 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tensorflow.python.platform
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
def maybe_download(filename, work_directory):
"""Download the data from Yann's website, unless it's already here."""
if not os.path.exists(work_directory):
os.mkdir(work_directory)
filepath = os.path.join(work_directory, filename)
if not os.path.exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
return filepath
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def extract_images(filename):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def extract_labels(filename, one_hot=False):
"""Extract the labels into a 1D uint8 numpy array [index]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels)
return labels
class DataSet(object):
def __init__(self, images, labels, fake_data=False, one_hot=False,
dtype=tf.float32):
"""Construct a DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`.
"""
dtype = tf.as_dtype(dtype).base_dtype
if dtype not in (tf.uint8, tf.float32):
raise TypeError('Invalid image dtype %r, expected uint8 or float32' %
dtype)
if fake_data:
self._num_examples = 10000
self.one_hot = one_hot
else:
assert images.shape[0] == labels.shape[0], (
'images.shape: %s labels.shape: %s' % (images.shape,
labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2])
if dtype == tf.float32:
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1] * 784
if self.one_hot:
fake_label = [1] + [0] * 9
else:
fake_label = 0
return [fake_image for _ in xrange(batch_size)], [
fake_label for _ in xrange(batch_size)]
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir, fake_data=False, one_hot=False, dtype=tf.float32):
class DataSets(object):
pass
data_sets = DataSets()
if fake_data:
def fake():
return DataSet([], [], fake_data=True, one_hot=one_hot, dtype=dtype)
data_sets.train = fake()
data_sets.validation = fake()
data_sets.test = fake()
return data_sets
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz'
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'
VALIDATION_SIZE = 5000
local_file = maybe_download(TRAIN_IMAGES, train_dir)
train_images = extract_images(local_file)
local_file = maybe_download(TRAIN_LABELS, train_dir)
train_labels = extract_labels(local_file, one_hot=one_hot)
local_file = maybe_download(TEST_IMAGES, train_dir)
test_images = extract_images(local_file)
local_file = maybe_download(TEST_LABELS, train_dir)
test_labels = extract_labels(local_file, one_hot=one_hot)
validation_images = train_images[:VALIDATION_SIZE]
validation_labels = train_labels[:VALIDATION_SIZE]
train_images = train_images[VALIDATION_SIZE:]
train_labels = train_labels[VALIDATION_SIZE:]
data_sets.train = DataSet(train_images, train_labels, dtype=dtype)
data_sets.validation = DataSet(validation_images, validation_labels,
dtype=dtype)
data_sets.test = DataSet(test_images, test_labels, dtype=dtype)
return data_sets
mnist_int16.py
# -*- coding: utf-8 -*-
import input_data
import tensorflow as tf
import numpy as np
from tf_fix import *
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
sess = tf.InteractiveSession()
with tf.name_scope('input'):
x = tf.placeholder("float", shape=[None, 784])
y_ = tf.placeholder("float", shape=[None, 10])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1);
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_4x4(x):
return tf.nn.max_pool(x, ksize=[1, 4, 4, 1], strides=[1, 4, 4,1], padding='SAME')
#First Convolutional Layer
with tf.name_scope('1st_CNN'):
W_conv1 = weight_variable([3, 3, 1, 32]) #[Kx][Ky][CHin][CHout]
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = conv2d(x_image, W_conv1) #[28,28,32]
h_pool1 = max_pool_4x4(h_conv1) #[7,7,32]
#Densely Connected Layer
with tf.name_scope('Densely_NN'):
W_fc1 = weight_variable([ 7* 7* 32, 256])
h_pool2_flat = tf.reshape(h_pool1, [-1, 7* 7* 32])
h_fc1= tf.matmul(h_pool2_flat , W_fc1) # [256]
#Dropout
with tf.name_scope('Dropout'):
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#Readout Layer
with tf.name_scope('Softmax'):
W_fc2 = weight_variable([256, 10])
h_fc2 = tf.matmul(h_fc1_drop, W_fc2)
y_conv=tf.nn.softmax(h_fc2)
with tf.name_scope('Loss'):
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
with tf.name_scope('Train'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#train_step = tf.train.AdamOptimizer(5e-5).minimize(cross_entropy)
with tf.name_scope('Accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv ,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction , "float"))
tf.initialize_all_variables().run()
for i in range(10000):
batch = mnist.train.next_batch(400);
if i%200 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob:1.0});
print("step %d, training accuracy %g"%(i, train_accuracy));
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob:0.5});
print("test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
print("=================================================")
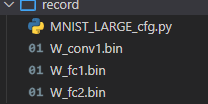
f_cfg = open('./record/MNIST_LARGE_cfg.py', 'w')
Get_Feature_Fraction_Part(x,"img",{x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0},f_cfg)
Record_Weight(W_conv1,"W_conv1",f_cfg)
#print(W_conv1.eval())
Get_Feature_Fraction_Part(h_conv1,"h_conv1",{x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0},f_cfg)
Get_Feature_Fraction_Part(h_pool1,"h_pool1",{x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0},f_cfg)
Record_Weight(tf.reshape(W_fc1,[7,7,32,256]),"W_fc1",f_cfg)
Get_Feature_Fraction_Part(h_fc1,"h_fc1",{x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0},f_cfg)
Record_Weight(tf.reshape(W_fc2,[1,1,256,10]),"W_fc2",f_cfg)
Get_Feature_Fraction_Part(h_fc2,"h_fc2",{x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0},f_cfg)
f_cfg.close();
print("=================================================")
sess.close()
量化
tf_fix.py
# -*- coding: utf-8 -*-
import input_data
import tensorflow as tf
import numpy as np
import math
import struct
K=8
BIT_WIDTH=16;
def Get_WeightLength(Ky,Kx,CHin,CHout):
return (K*Kx*Ky*CHout*((CHin+K-1)/K))
def To_Fixed(tensor,bitwidth):
array=tensor.eval();
range=max(np.max(array),-np.min(array))
int_part=max(math.ceil(math.log(range,2)+0.000001),0) + 1 #1 bit for sign
fraction_part=bitwidth-int_part
return ( np.round(array*pow(2,fraction_part)) , fraction_part ) #/pow(2,fraction_part)
def Feature_To_Fixed(tensor,bitwidth,feed_dict):
array=tensor.eval(feed_dict=feed_dict);
range=max(np.max(array),-np.min(array))
#print range;
int_part=max(math.ceil(math.log(range,2)+0.000001),0) + 1 #1 bit for sign
fraction_part=bitwidth-int_part
return ( np.round(array*pow(2,fraction_part)) , fraction_part ) #/pow(2,fraction_part)
def Map_Weight_Data(kernel,array_map,Ky,Kx,in_ch,out_ch):
for cout in range(out_ch):
for i in range(Ky):
for j in range(Kx):
for cin in range(in_ch):
array_map[cout][i][j][cin//K][cin%K]=kernel[i][j][cin][cout];
def Get_Feature_Fraction_Part(tensor,name,feed_dict,file):
(array,fraction_part)=Feature_To_Fixed(tensor,BIT_WIDTH,feed_dict);
file.write("%s=%d\n" % ("PTR_"+name.upper(),int(fraction_part)) );
#print(name+' fraction_part: ' + str(int(fraction_part)));
def Record_Weight(tensor,name,file):
(array,fraction_part)=To_Fixed(tensor,BIT_WIDTH);
file.write("%s=%d\n" % ("PTR_"+name.upper(),int(fraction_part)) );
# Feature: [C/K][H][W][K] kernel: [Kx][Ky][CHin][CHout]===>[CHout][Ky][Kx][CHin/K][K]
array_map=np.zeros([np.shape(array)[3],np.shape(array)[0],np.shape(array)[1],(np.shape(array)[2]+K-1)//K,K])
Map_Weight_Data(array,array_map,np.shape(array)[0],np.shape(array)[1],np.shape(array)[2],np.shape(array)[3]);
with open('./record/'+name+'.bin', 'wb') as fp:
for i in range(np.shape(array_map)[0]):
for j in range(np.shape(array_map)[1]):
for k in range(np.shape(array_map)[2]):
for l in range(np.shape(array_map)[3]):
for m in range(np.shape(array_map)[4]):
a=struct.pack('h',int(array_map[i][j][k][l][m])) # write 2binary number to file
#print(array_map[i][j][k][l][m]);
fp.write(a)
生成权重和量化结果:
硬件设计
将之前的卷积和数据流风格的池化单元IP加到工程里,生成bit流文件对FPGA进行配置
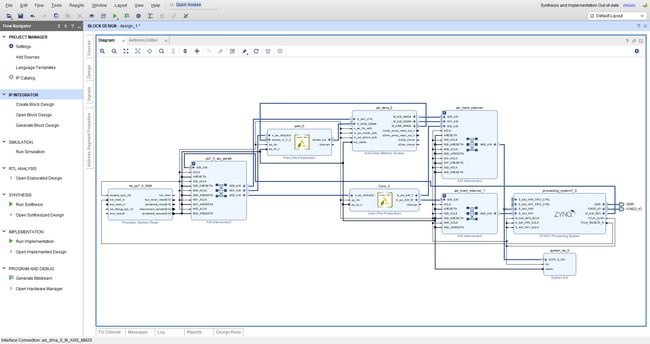
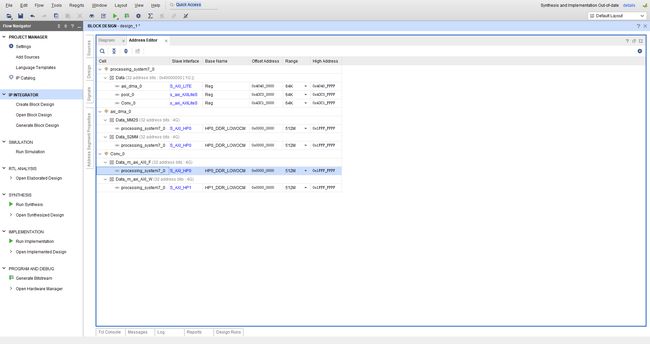
PYNQ工程开发
将测试图片的文件、生成的权重文件,复制到pynq中
 将硬件设计文件hwh, bit文件和量化的小数点位置等配置放入pynq中
将硬件设计文件hwh, bit文件和量化的小数点位置等配置放入pynq中
driver.py
包含对卷积IP和池化IP的配置,以及包含软件版本便于检测是否错误
from pynq import Overlay
import numpy as np
from pynq import Xlnk
import struct
K=8
def Disp_Feature(feature):
for i in range(np.shape(feature)[0]):
for j in range(np.shape(feature)[1]):
for k in range(np.shape(feature)[2]):
for l in range(np.shape(feature)[3]):
if(feature[i][j][k][l]!=0):
print("out[%d,%d,%d,%d]=%d"%(i,j,k,l,feature[i][j][k][l]));
def Disp_Weight(weight):
for i in range(np.shape(weight)[0]):
for j in range(np.shape(weight)[1]):
for k in range(np.shape(weight)[2]):
for l in range(np.shape(weight)[3]):
for m in range(np.shape(weight)[4]):
print("out[%d,%d,%d,%d,%d]=%d"%(i,j,k,l,m,weight[i][j][k][l][m]));
def Load_Weight_From_File(weight,file):
with open(file,'rb') as fp:
for i in range(np.shape(weight)[0]):
for j in range(np.shape(weight)[1]):
for k in range(np.shape(weight)[2]):
for l in range(np.shape(weight)[3]):
for m in range(np.shape(weight)[4]):
dat=fp.read(2) # 每次读两个字节,因为weight是16位的=2个byte
a=struct.unpack("h",dat) # 两个byte合并成一个int16的数
#print(a[0])
weight[i][j][k][l][m]=a[0] # 把数字给weight
def Run_Pool(pool,dma,ch,kx,ky,feature_in,feature_out):
pool.write(0x10,(ch+K-1)//K);
pool.write(0x18,feature_in.shape[1])
pool.write(0x20,feature_in.shape[2])
pool.write(0x28,feature_out.shape[1])
pool.write(0x30,feature_out.shape[2])
pool.write(0x38,kx)
pool.write(0x40,ky)
#print("start");
pool.write(0, (pool.read(0)&0x80)|0x01 ) #start pool IP
dma.recvchannel.transfer(feature_out)
dma.sendchannel.transfer(feature_in)
dma.sendchannel.wait();
#print("send done")
dma.recvchannel.wait()
#print("recv done")
tp=pool.read(0)
while not((tp>>1)&0x1):
tp=pool.read(0)
#print("pool ip done")
def Run_Conv(conv,chin,chout,kx,ky,sx,sy,mode,relu_en,feature_in,feature_in_precision,weight,weight_precision,feature_out,feature_out_precision):
conv.write(0x10,chin)
conv.write(0x18,feature_in.shape[1])
conv.write(0x20,feature_in.shape[2])
conv.write(0x28,chout)
conv.write(0x30,kx)
conv.write(0x38,ky)
conv.write(0x40,sx)
conv.write(0x48,sy)
conv.write(0x50,mode)
conv.write(0x58,relu_en)
conv.write(0x60,feature_in.physical_address)
conv.write(0x68,feature_in_precision)
conv.write(0x70,weight.physical_address)
conv.write(0x78,weight_precision)
conv.write(0x80,feature_out.physical_address)
conv.write(0x88,feature_out_precision)
#print("conv ip start")
conv.write(0, (conv.read(0)&0x80)|0x01 ) #start pool IP
#poll the done bit
tp=conv.read(0)
while not((tp>>1)&0x1):
tp=conv.read(0)
#print("conv ip done")
def Run_Pool_Soft(ch,kx,ky,feature_in,feature_out):
for i in range(ch):
for j in range(feature_out.shape[1]):
for k in range(feature_out.shape[2]):
tp=-32768;
for ii in range(ky):
for jj in range(kx):
row=j*kx+ii
col=k*ky+jj
dat=feature_in[i//K][row][col][i%K]
if(dat>tp):
tp=dat
feature_out[i//K][j][k][i%K]=tp
def Run_Conv_Soft(chin,chout,kx,ky,sx,sy,mode,relu_en,feature_in,feature_in_precision,weight,weight_precision,feature_out,feature_out_precision):
if(mode==0):
pad_x=0
pad_y=0
else:
pad_x=(kx-1)//2
pad_y=(ky-1)//2
for i in range(chout):
for j in range(feature_out.shape[1]):
for k in range(feature_out.shape[2]):
sum=np.int64(0)
for c in range(chin):
for ii in range(ky):
for jj in range(kx):
row=j*sy-pad_y+ii
col=k*sx-pad_x+jj
if not (row<0 or col<0 or row>=feature_in.shape[1] or col>=feature_in.shape[2]):
dat=feature_in[c//K][row][col][c%K]
wt=weight[i][ii][jj][c//K][c%K]
#print("%d %d=%d, wt=%d "%(row,col,dat,wt))
sum=sum+int(dat)*int(wt)
res=sum>>(feature_in_precision+weight_precision-feature_out_precision)
if(res>32767):
res=32767
else:
if(res<-32768):
res=32768
feature_out[i//K][j][k][i%K]=res
mnist.ipynb
- 导入库
from driver import *
from MNIST_LARGE_cfg import *
from pynq import Overlay
import numpy as np
from pynq import Xlnk
import time
import cv2
import matplotlib.pyplot as plt
- fpga烧写,获取ip
ol=Overlay("conv_pool.bit")
ol.download();
dma=ol.axi_dma_0
pool=ol.pool_0
conv=ol.Conv_0
- 加载权重
xlnk=Xlnk()
# input_feature = [div_tile_num, H, W, K] = [1/8, 28, 28, 8]
image=xlnk.cma_array(shape=(1,28,28,K),cacheable=0,dtype=np.int16)
# weight = [out_channel, kernel_x, kernel_y, div_tile_num, K] = [32, 3, 3, 1, 8]
W_conv1=xlnk.cma_array(shape=(32,3,3,1,K),cacheable=0,dtype=np.int16)
# conv1_output_feature = [div_tile_num, H, W, K] = [32/8, 28, 28, 8] = [4, 28, 28, 8]
h_conv1=xlnk.cma_array(shape=(4,28,28,K),cacheable=0,dtype=np.int16)
# 经过4*4的池化后:pool_output_feature = [4, 28/4, 28/4, 8] = [4, 7, 7, 8]
h_pool1=xlnk.cma_array(shape=(4,7,7,K),cacheable=0,dtype=np.int16)
# full connection kernel
W_fc1=xlnk.cma_array(shape=(256,7,7,4,K),cacheable=0,dtype=np.int16)
# full connection output div_tile_num:32 = 256/K
h_fc1=xlnk.cma_array(shape=(32,1,1,K),cacheable=0,dtype=np.int16)
# softmax activation function kernel
W_fc2=xlnk.cma_array(shape=(10,1,1,32,K),cacheable=0,dtype=np.int16)
# softmax activation output div_tile_num:2 = 10/K = 2
h_fc2=xlnk.cma_array(shape=(2,1,1,K),cacheable=0,dtype=np.int16)
Load_Weight_From_File(W_conv1,"record/W_conv1.bin")
Load_Weight_From_File(W_fc1,"record/W_fc1.bin")
Load_Weight_From_File(W_fc2,"record/W_fc2.bin")
调用driver里的Load_Weight_From_File函数,加载权重放入fpga里,等待fpag读

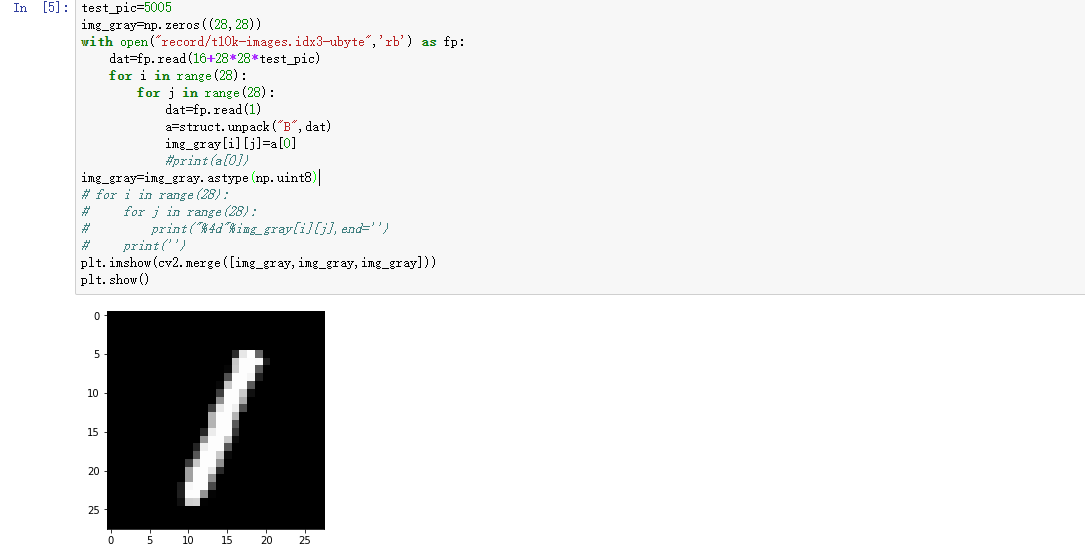
- 查看测试的数据
test_pic=5005 # 测试图片索引
img_gray=np.zeros((28,28))
with open("record/t10k-images.idx3-ubyte",'rb') as fp:
dat=fp.read(16+28*28*test_pic) # 前16个字节是头文件,后面每28*28个字节是一张图片,把光标移到图片的开始
for i in range(28):
for j in range(28):
dat=fp.read(1) # 每次读出一个字节
a=struct.unpack("B",dat) # 把读出的字节转换位Byte型数据
img_gray[i][j]=a[0]
#print(a[0])
img_gray=img_gray.astype(np.uint8)
# for i in range(28):
# for j in range(28):
# print("%4d"%img_gray[i][j],end='')
# print('')
plt.imshow(cv2.merge([img_gray,img_gray,img_gray]))
plt.show()
- 图片0-255 转换为0-1
for i in range(np.shape(img_gray)[0]):
for j in range(np.shape(img_gray)[1]):
image[0][i][j][0]=int((img_gray[i][j]/255)*(2**PTR_IMG)); # 小数转换为整数的定点数
- 调用硬件完成运算
start=time.time()
# 第一层卷积 conv,chin,chout,kx,ky,sx,sy,mode,relu_en,f_in,f_in_precision,weight,weight_precision,f_out,f_out_precision
# [1, 28, 28, K]conv[32, 3, 3, 1, K]--> h_conv1 = [32/8, 28, 28, K]
Run_Conv(conv,1,32,3,3,1,1,1,0,image,PTR_IMG,W_conv1,PTR_W_CONV1,h_conv1,PTR_H_CONV1)
# Run_Pool_Soft(32,4,4,h_conv1,h_pool1)
# 池化(div_tile_num, padding_x, padding_y, F_in, F_out)
# [4, 28, 28, K]pool[4, 4] --> [4, 7, 7, K]
Run_Pool(pool,dma,32,4,4,h_conv1,h_pool1)
# 全连接, channel: 32-->256的
# [32/8, 7, 7, K] full_connect [256, 7, 7, 32/8, K] --> [256/K, 1, 1, K]
Run_Conv(conv,32,256,7,7,1,1,0,0,h_pool1,PTR_H_POOL1,W_fc1,PTR_W_FC1,h_fc1,PTR_H_FC1)
# [256/K, 1, 1, K] full_connect [10, 1, 1, 256/K, K] --> [10/K, 1, 1, K]
Run_Conv(conv,256,10,1,1,1,1,0,0,h_fc1,PTR_H_FC1,W_fc2,PTR_W_FC2,h_fc2,PTR_H_FC2)
end=time.time()
print("Hardware run time=%s s"%(end-start))

- 获取最大概率的预测值
