Teacher-Forcing, Student-Forcing, Schedual sampling , Teacher-Recommended and Professor-Forcing训练策略
「Teacher forcing」
如果我们能够在每一步的预测时,让老师来指导一下,即提示一下上一个词的正确答案,decoder就可以快速步入正轨,训练过程也可以更快收敛。因此大家把这种方法称为teacher forcing。所以,这种操作的目的就是为了使得训练过程更容易。
缺点:(1)预测(inference stage)时我们没有老师给你做标记了!纯靠自己很可能挂掉。
(2)对于NMT任务来说,不可能保证某种语言中的每一个词在另一种语言中都有对应的词语 【1】。(3)强制词语对应消除了语义相似的其他翻译结果,扼杀了翻译的多样性,(4)Overcorrect 问题 【1】,解释如下:
1. 待生成句的Reference为: "We should comply with the rule."
2. 模型在解码阶段中途预测出来:"We should abide"
3. 然而Teacher-forcing技术把第三个ground-truth "comply" 作为第四步的输入。那么模型根据以往学习的pattern,有可能在第四步预测到的是 "comply with"
4. 模型最终的生成变成了 "We should abide with"
5. 事实上,"abide with" 用法是不正确的,但是由于ground-truth "comply" 的干扰,模型处于矫枉过正的状态,生成了不通顺的语句。

「Free running」/「Student forcing」 一步错,步步错。这样会导致训练时的累积损失太大(「误差爆炸」问题,exposure bias),训练起来就很费劲。
为了兼得二者优势,规避二者劣势
提出更好的办法、更常用的办法,是老师只给适量的引导,学生也积极学习。即我们设置一个概率p,每一步,以概率p靠自己上一步的输入来预测,以概率1-p根据老师的提示来预测,这种方法称为「计划采样」[2](「scheduled sampling」/「Curriculum Learning」):

另外有一个小细节:在seq2seq的训练过程中,decoder即使遇到了
标识也不会结束,因为训练的时候并不是一个生成的过程 ,我们需要等到“标准答案”都输入完才结束。
在transformer中的应用【3】。
对于以上三种decoding方式,其实都是「Greedy Decoding」
「Greedy Decoding」,即每一步,都预测出概率最大的那个词,然后输入给下一步。
存在的问题就是:「每一步最优,不一定全局最优」
改进的方法,就是使用「Beam Search」方法:每一步,多选几个作为候选,最后综合考虑,选出最优的组合。
面我们来具体看看Beam Search的操作步骤:
- 首先,我们需要设定一个候选集的大小beam size=k;
- 每一步的开始,我们从每个当前输入对应的所有可能输出,计算每一条路的“序列得分”;
- 保留“序列得分”最大的k个作为下一步的输入;

这个score代表了当前到第t步的输出序列的一个综合得分,越高越好。
具体而言,转载至蝈蝈
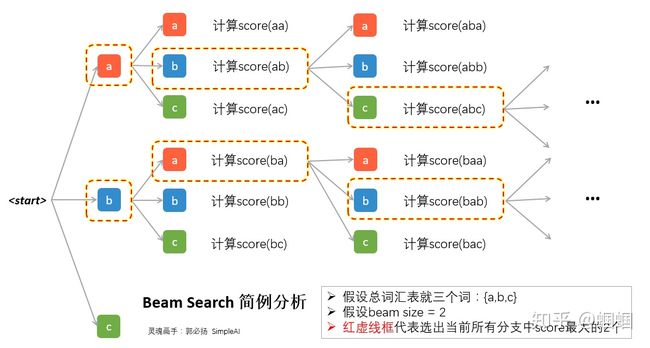
在每一步,我们都会去对所有的可能输出,计算一次score,假设beam size为k,词汇量为V,那么每一步就需要分出k×V个分支并逐一计算score。所以在图中我们可以看到除了第一步,后面每一步都是分出来2×3=6支。然后综合这k×V个score的结果,只选择其中最大的k个保留。
最后还有一个问题:由于会有多个分支,所以很有可能我们会遇到多个
一个细节:在search结束之后,我们需要对已完成的N个序列做一个抉择,挑选出最好的那个,那不就是通过前面定义的score函数来比较吗?确实可以,但是如果直接使用score来挑选的话,会导致那些很短的句子更容易被选出。因为score函数的每一项都是负的,序列越长,score往往就越小。因此我们可以使用长度来对score函数进行细微的调整:对每个序列的得分,除以序列的长度。根据调整后的结果来选择best one。
接下来介绍下Teacher-recommended 【4】
因为上面的单词没有考略sufficient training for content-related words due to long-tailed problems,可能造成经常生成某几个单词,缺少泛化能力。下图所示

因此本文采用了一种引入外部预训练的预料模型(External Language Model,ELM),比如BERT,GPT,基于知识蒸馏的思想,使用KL散度(由于ELM fixed,简化之后就是交叉熵损失),对原模型进行优化。
1、把teacher-forcing 定义的输入作为hard target,其他的可选目标叫做soft target。
2、然后选择top-k个候选词,作为soft target label。

最后说下,Professor-Forcing,【5】:
该方法使生成行为和teacher-forced行为尽可能地匹配。这对于允许RNN继续产生远远超过其在训练期间看到的序列长度的特别重要。
为什么提出Professor-Forcing,
(1)Inference stage没有单词引导。当使用RNN来进行预测时,真实样本序列是无效的条件,我们只能通过在给定先前生成的样本的条件分布中对每个y_t进行采样来从序列上的联合分布中进行采样。不幸的是,在序列生成过程中,当一个小的预测错误发生时,这个过程会产生问题。当RNN的条件上下文(即先前生成的样本的序列)与训练时所使用的序列不一致时,这会导致一个非常差的性能。
When using the RNN for prediction, the ground-truth sequence is not available conditioning and we sample from the joint distribution over the sequence by sampling each y_t from its conditional
(2)schedule sampling基于采样缺乏全局一致性。 当模型连续生成几个后,正确的目标序列(就其分布而言)是否仍然是真实训练序列中的目标序列,这是不确定的。通过使自生成的子序列缩短并使用自生成序列对比真实样本序列的概率退火,可以通过各种方式减轻这种情况。然而,正如Huszár所说,scheduled sampling产生一个有偏估计,即使样本数和容量变为无穷大,此过程也可能无法收敛到正确的模型。然而,值得注意的是,scheduled sampling的实验清楚地显示了生成序列的健壮性方面的一些改进,表明确实需要通过生成RNN的最大似然(或teacher forcing)训练来修复(或替换)某些事物。【机翻】
when the model generates several consecutive y_t’s, it is not clear anymore that the correct target (in terms of its distribution) remains the one in the ground truth sequence. This is mitigated in various ways, by making the self-generated subsequences short and annealing the probability of using self-generated vs ground truth samples. However, scheduled sampling yields a biased estimator, in that even as the number of examples and the capacity go to infinity, this procedure may not converge to the correct model. It is however good to note that experiments with scheduled sampling clearly showed some improvements in terms of the robustness of the generated sequences, suggesting that something indeed needs to be fixed (or replaced) with maximum-likelihood (or teacher forcing) training of generative RNNs.
具体做法就是

简单说就是利用一个生成器和判别器,让student forcing去学习teacher forcing,进而泛化到test stage。摘至nopSled的博客

【1】Bridging the Gap between Training and Inference for Neural Machine Translation, ACL 2019 最佳长论文
【2】Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks NIPS 2015
【3】Scheduled Sampling for Transformers ACL 2019
【4】Object Relational Graph With Teacher-Recommended Learning for Video Captioning CVPR 2020
【5】Professor Forcing: A New Algorithm for Training Recurrent Networks NIPS 2016