【Seq2Seq】相关理论基础与RNN的相应变体
文章目录
- 1. 发展历程
- 2. 基础理解
-
- 2.1 基础的神经网络
- 2.2 RNN网络的相应变体
-
- 2.2.1 RNN变体 N V 1
- 2.2.2 RNN变体 (1VN)Decode的变体
- 2.2.3 RNN变体 (NVN)
- 2.2.4 RNN变体(NVM) Seq2Seq
- 3.Seq2Seq基础理论
-
- 3.1 Seq2Seq的相应组成部分
-
- 3.2 Encoder部分
- 3.3 Decoder解码器
-
- 3.3.1 解码器1
- 3.3.2 解码器2
- 3.4 第一篇论文简介
-
- 3.4.1 Encoder部分
- 3.4.2 Decoder部分
- 3.5 第二篇论文
- 4. Seq2Seq存在的问题
-
- 4.1 Encoder-Decoder局限性
- 4.2 Attention解决的问题
1. 发展历程

Seq2Seq在2014年顶会正式被提出,其中在同一年有两篇文章都用到了序列到序列,编码器解码器的方式实现机器翻译。其中GPU也在2014年被提出。
在2015年,针对Seq2Seq的一些问题,提出了注意力Attention机制,已经逐步开始爆发。
在2017年,谷歌发表了一篇Attention is All you need,将注意力机制推到了顶峰,其中也有学者用Self-Attention来替代cnn和Rnn
2. 基础理解
2.1 基础的神经网络
传统的单层神经网络,就是传入一个输出,对应的传出相应的输出。
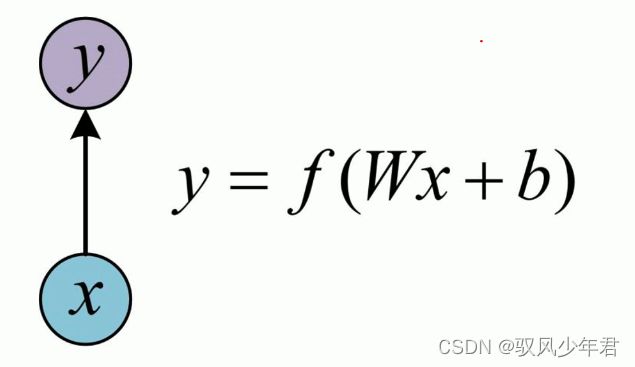
相对于传统的神经网络,经典的RNN网络如下所示,就是每一个输入都是依赖于上一层次的隐藏层状态和当前的输入。
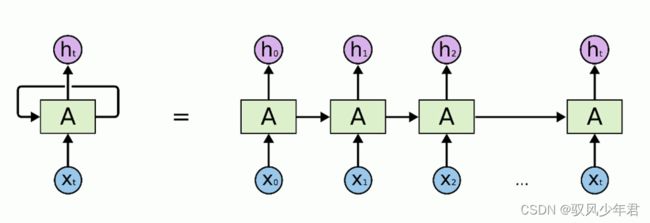
2.2 RNN网络的相应变体
2.2.1 RNN变体 N V 1
传统的NV1使用的还是比较频繁的,基本都用于对于文本的分类的任务,对于一个序列数据的多个的一个输入,最终得到一个输出的结果的一个数据。
首先有一个隐藏层的h0数据,相应的输入x1~x5,最终得到一个y。
当前层h5依赖于上一层的h5和当前的输入x5。将最终结果接上一个softmax,完成相应的分类任务。

2.2.2 RNN变体 (1VN)Decode的变体
1VN是表示一个输入,N个输出的结果,比如输入一个当前数据x,得到多个输出y1~y5。
这种的应用经常用于,看图说话等任务,比如输入一个图片数据x,输入就是一段的文字。
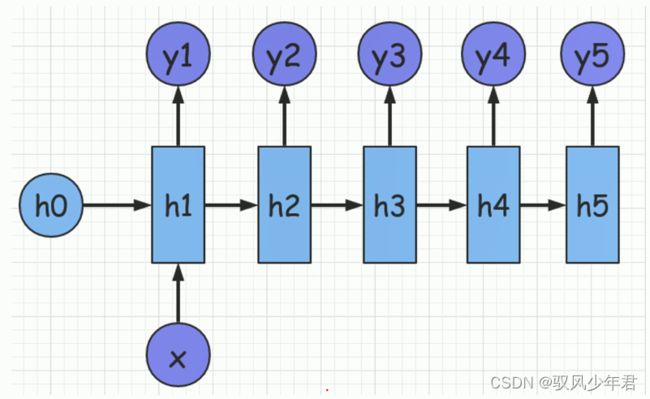
相应的1VN 变体还有一种情况,就是将输入,对应的输入到相应的隐藏层的状态当中,相对于上面的只利用一次的x的方式,当前的方式,可以更好的利用x的数据。
一个输入x输入多次。之前的Seq2Seq的作者就是基础这个基础上完成相应的任务。

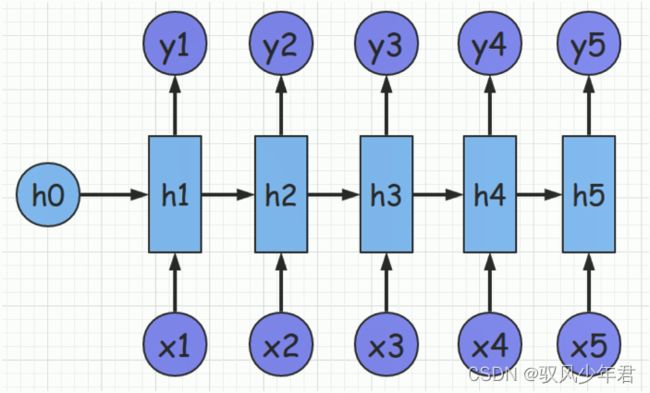
2.2.3 RNN变体 (NVN)
理解好了上面的模型,当前的模型也类似,对于的相应的N个的输入结果,会输出相应的N个结果,适用于11对应的任务。
不是很适合于相应的不对称的任务。
2.2.4 RNN变体(NVM) Seq2Seq
Seq2Seq是相应的RNN的一种变体,编码器和解码器模型
可以将当前的模型理解为两个的RNN网络,decode和encode都是理解为不同的RNN网络。
Encode针对每个输入,进行计算,最终得到一个语义编码向量C。
将C输入到Decode中,得到不同的编码结果。
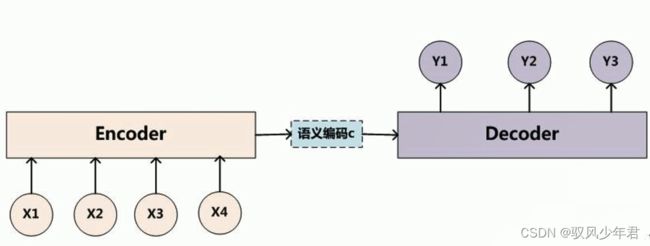
3.Seq2Seq基础理论
3.1 Seq2Seq的相应组成部分
Seq2seq模型可简单理解为由三部分组成: Encoder、 Decoder 和连接两者的State Vector
Seq2Seq有两种不同的变体,如下两个图所示,基本的两种Decode的变体,和上文说的两种的1VN的变体类似。
第一种的变体,就是将中间向量C作为decode解码器中的,每个隐藏层的输入,得到结果y。
比如,当前的中间结果y2的结果输入,包含y1以及encode得到的结果c,两者结果的评价拼接,输入。

第二种的相应的decode的变体,相应于第一种的变体,更简单点。将encoder得到的最终的中间向量c最为decoder的初始向量输入到rnn网络中,c仅仅参与第一层的网络,后面的网络并不参与计算。
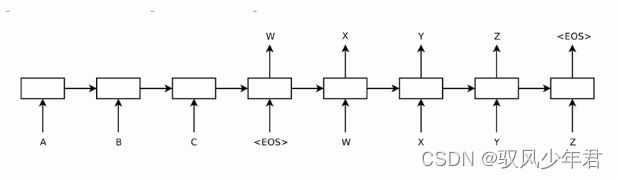
3.2 Encoder部分
Seq2Seq主要用于对于机器翻译的任务,我们希望通过给定句子《X,Y》,通过模型完成将句子X翻译成句子Y的任务,其中X和y是由不同数量的单词组成。
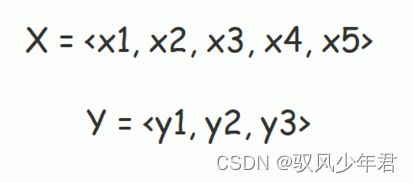
首先,我们的Encoder会对输入的句子X进行相应的编码,经过相应的函数计算得到中间向量C
C向量的得到,可以通过多种的方法得到:
- 1.C = h5,将最终的结果h5 赋值给c
- 2.在h5的基础上,再添加一个函数q的运算得到C
- 3.将h1~h5都堆叠起来,添加一个函数,得到结果C
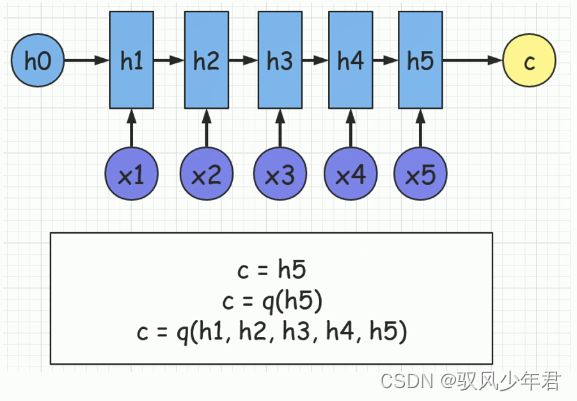
主要通过Encoder,将相应的数据都凝结成精华C,C包含了前面的所有向量的数据。
3.3 Decoder解码器
3.3.1 解码器1
得到中间语义向量C后,使用Decoder进行解码。
Decoder根据中间状态向量 C和已经生成的历史信息y1, y2…yi-1 去生成t时刻的单词yi
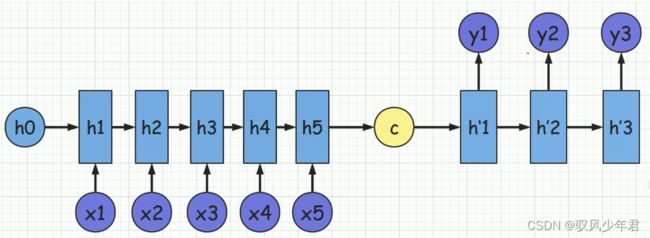
上图并为画出,相应在h‘1时刻其实还有一个起始的触发词,如EOS。还有终止词汇n
3.3.2 解码器2
如果将C当作Decoder的每-时刻输入,则是可以得到Seq2Seq模型的另- -种模型
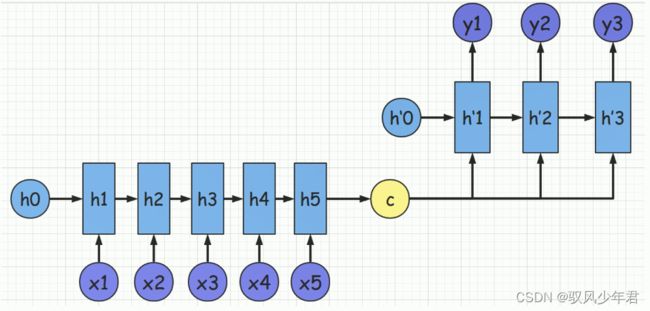
3.4 第一篇论文简介
3.4.1 Encoder部分
该框架由这篇论文提出: Cho et al.(2014) Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation。
这篇论文主要是用GRU完成对于机器翻译任务,但是这里主要是用RNN来讲解
其中Encoder的中的softmax函数中的c是偏置,不要与语义向量C混淆。Encoder部分是典型的RNN网络。
通过Tanh得到最终的C

3.4.2 Decoder部分
decoder的ht,依赖于上一层的ht-1,y,C,还需要有偏置的计算b。
其中还需要有一个起始信号与终止信号,start与end信号。

3.5 第二篇论文
该框架由这篇论文提出: Sutskever et al.(2014) Sequence to Sequence Learning with NeuralNetworks。这个框架也是最常用的-种,结构图如下:
这篇论文主要用LSTM完成,为了简便,用RNN简介,
解码Decoder仅仅依赖于ht-1和yt-1,并没有多次依赖C

将C作为初始状态,但是不用于后面的时刻,用EOS用于起始与终止。其中只有h0 = C
4. Seq2Seq存在的问题
4.1 Encoder-Decoder局限性
从下图中可以看出Encoder和Decoder的唯- -联系只有语义编码C,即将整个输入序列的信息编码成-一个固定大小的状态向量再解码,相当于将信息”有损压缩”。
很明显这样做有两个缺点:
➢中间语义向量无法完全表达整个输入序列的信息。
➢随着输入信息长度的增加,由于向量长度固定,先前编码好的信息会被后来的信息覆盖,.
丢失很多信息。
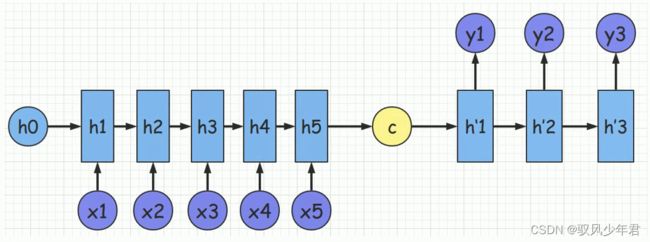
从下图中可以明显可以发现在生成y1、y2、 y3时,语义编码C对它们所产生的贡献都是一样的。
例如翻译: Cat chase mouse,模型逐字生成:“猫” "捉”、 “老鼠”。在翻译mouse单词时,每一-个英语单词对"老鼠”的贡献都是相同的。
如果引入了Attention模型,那么mouse对于它的影响应该是最大的。
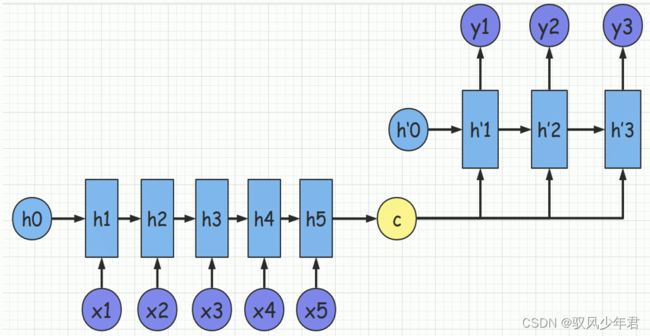
4.2 Attention解决的问题
Attention: 为了解决上面两个问题,引入了Attention模型。
A ttention模型的特点:
➢是Decoder不再将整个输入序列编码为固定长度的中间语义向量C,而是根据当前生成的新单词计算新的C(i),使得每个时刻输入不同的C ;
➢这样就解决了单词信息丢失的问题。引入了Attention的Encoder-Decoder模型如下图:

本次的分享就差不多结束了,自然语言处理的学习还真的还有很长的路呢。