【pytorch系列】多GPU并行训练 torch.nn.DataParallel用法
【问题】在使用nn.DataParallel时出现“ optimizer got an empty parameter list”问题。
model = nn.DataParallel(model, device_ids=[0,1,2,3])
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
[ValueError] : optimizer got an empty parameter list
【分析】 数据没有传输到GPU上
【尝试】
model = nn.DataParallel(model, device_ids=[0,1,2,3])
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
【依然报错】
[ValueError] : optimizer got an empty parameter list
【再次尝试】
model = model.to(device)
model = nn.DataParallel(model, device_ids=[0,1,2,3])
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
!!! 正确运行
【总结】 应当将model先放到GPU上,然后在进行并行训练(猜想,可能是因为实验采用的是远程服务器,应该先将数据和model传输到远程服务器端,然后进行并行操作)
【tips】
对于需要load的模型,应当先构建好模型,load参数,然后传到gpu上,最后并行。
设置CUDA相关命令
1. python
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,2,3"
2. linux
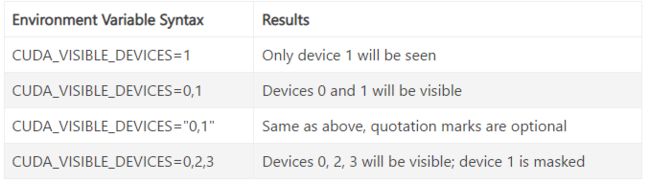
以上两种方式效果相同,第一种是python程序命令,第二种是linux命令。通过这两个命令控制CUDA应用可见的GPU。
【分析1】
CUDA应用运行时,CUDA将遍历当前可见的设备,并从零开始为可见设备编号。如果为CUDA_VISIBLE_DEVICES 设置了不存在的设备,所有实际设备将被隐藏,CUDA 应用将无法使用GPU设备;如果设备序列是存在和不存在设备的混合,那么不存在设备前的所有存在设备将被重新编号,不存在设备之后的所有设备将被屏蔽。当前上下文中可见的(重新编号后的)设备可使用CUDA SDK搭配的deviceQuery程序来查看。
【分析2】
CUDA将从零开始枚举可见设备。在最后一种情况下,设备0、2、3将显示为设备0、1、2。如果将字符串的顺序更改为“2,3,0”,则设备2,3,0将分别被枚举为0,1,2。如果CUDA_VISIBLE_DEVICES设置为不存在的设备,则所有设备都将被屏蔽。您可以指定有效和无效设备号的组合。将枚举无效值之前的所有设备,而隐藏无效值之后的所有设备。
【注意】
注意:对于在代码内通过代码修改可见设备的情况,只有在代码访问GPU设备之前设置CUDA_VISIBLE_DEVICES变量才有效。 如果你模型保存之前没有转换到CPU上,那么模型重加载的时候会直接加载到GPU设备中,具体加载到哪个设备依赖于模型的device属性,一般默认为 cuda:0,即加载到系统的第一块显卡。如果我们在重加载模型前设置CUDA_VISIBLE_DEVICES,就能起到设备屏蔽的左右,而如果是模型重加载完后才设置 CUDA_VISIBLE_DEVICES, 设置无效,因为GPU设备已经被访问了
【非常重要!!!】
可见的GPU设置一定要在所有的设置之前,包括device,model.to(device),以及input.to(device)
因为device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 命令是查看当前可用的gpu,如果不设置可见GPU,那么将return所有gpu,从而导致模型载入的gpu非我们设置的可见GPU,而是device中获得的所有gpu。
os.environ["CUDA_VISIBLE_DEVICES"] = "0,2,3"
【问题】
RuntimeError: CUDA error: out of memory
【原因分析】
在os.environ["CUDA_VISIBLE_DEVICES"] = "0,2,3"命令之前设置device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
【修改 案例】
import os
# 最先设置可见GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1,3" # 对于python而言仅0,2 GPU可见,pytorch对应的
# 设置device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 设置模型
model = ViT(in_channels=2)
# 查看device的属性:GPU个数,用于检查是否gpu设置是否正确
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
# 模型导入GPU
model.to(device)
# 数据导入GPU
input = torch.randn((32, 2, 1, 2500)).to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())
【总结】
严格按照上述步骤进行,否则可能导致某些命令失效。
【linux 测试代码】
# 直接使用命令 因为相关可见GPU已经在代码中设置过
python Run_Net.py