Crafting Adversarial Input Sequences for Recurrent Neural Networks
作者: 19届 lz
论文:《Crafting Adversarial Input Sequences for Recurrent Neural Networks》
问题
对手可以制作对抗性序列来误导分类和顺序递归神经网络
贡献:
•我们在序列数据的上下文中形式化了对抗样本优化问题。我们使用前向导数来调整制作算法以适应 RNN 的特殊性。这包括展示如何计算循环计算图的前向导数。
• 我们研究将模型预处理输入的对抗性扰动转换为原始输入。
相关工作
循环神经网络 (RNN) 是从前馈神经网络改编而来的机器学习模型,与前馈神经网络不同,RNN 能够处理大长度且通常可变长度的序列数据。 RNN 在其计算图中引入循环以有效地模拟时间的影响 。循环计算的存在可能对基于模型微分的现有对抗样本算法的适用性提出挑战,因为循环通过应用链式法则直接阻止计算梯度。
我们研究了一个特定的对抗样本实例——我们称之为对抗序列——旨在误导 RNN 产生错误的输出。我们表明,使用一种名为计算图展开的技术,前向导数可以适用于具有循环计算图的神经网络。
神经网络是一类机器学习模型,可用于监督、无监督和强化学习的所有任务。它们由神经元(基本计算单元)组成,将激活函数 φ 应用于它们的输入 ~ x 以产生通常由其他神经元处理的输出。因此,神经元执行的计算采用以下形式:
其中~w是一个参数,称为权重向量,其作用在下文详述。在神经网络 f 中,神经元通常被分组在相互连接的层 fk 中。一个网络总是至少有两层对应于模型的输入和输出。可以在这些输入和输出层之间插入一个或多个中间隐藏层。如果网络只有一个或没有隐藏层,则称为浅层神经网络。否则,网络被称为深度网络,隐藏层的常见解释是它们提取产生输出所需的输入的连续和分层表示
Recurrent Neural Networks
循环神经网络的特性最重要的是在模型的计算图中引入了循环,这导致了一种参数共享的形式,负责对大序列的可扩展性。换句话说,除了不同层神经元之间的链接外,循环神经网络还允许位于同一层的神经元之间的链接,这导致网络架构中存在循环。循环允许模型在不同时间步长的给定输入值的连续值中共享权重——它们是连接神经元输出和输入的链接的参数。
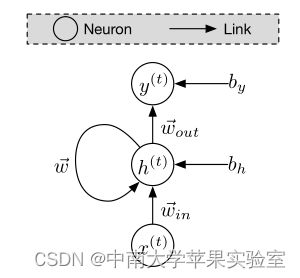
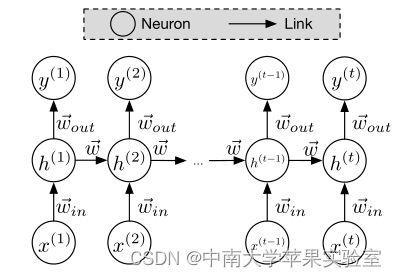
展开循环神经网络
对抗样本
在机器学习分类器 f 的上下文中,对抗样本 ~x* 是从合法样本 ~ x 通过选择最小的——根据适合输入域的范数——扰动 δ~ x 导致样本改变 ~ x∗ 被错误分类到与其合法类别 f(~ x) 不同的类别中。对抗性目标类可以是选定的类或任何不同于合法类的类。因此,对抗样本解决了以下优化问题,首先形式化为
![]()
当然,由于深度神经网络的非凸性和非线性,并不总是能够找到该问题的精确解决方案,尤其是在深度神经网络的情况下。
考虑 RNN 处理顺序数据。当输入和输出数据都是序列时,就像我们的一个实验中的情况一样,上述等式不成立,因为输出数据不是分类的。因此,对抗样本优化问题需要泛化以指定对抗目标向量~y∗,在处理对抗输入 ~x∗ 时,模型 f 将尽可能地匹配该向量。这可以表述为:
其中 ~y∗ 是对手想要的输出序列,|k · k| 是适合比较 RNN 输入或输出域中的向量的范数,Δ 是模型输出 f(~ x + ~ z) 在对抗序列上的可接受误差和对抗目标~y*。比较输入序列的一个示例规范是扰动的序列步数。
Fast Gradient Sign Method(快速梯度符号法)
速梯度符号方法通过将模型的成本函数围绕其输入线性化并使用成本函数相对于输入本身的梯度来选择扰动来近似等式中的问题。

其中 c 是与模型 f 相关的成本函数,ε 是控制扰动幅度的参数。增加输入变化参数 ε 增加了 ~x∗ 被错误分类的可能性,但同时增加了扰动的大小,从而增加了它的可区分性。
基于 LSTM 的 RNN
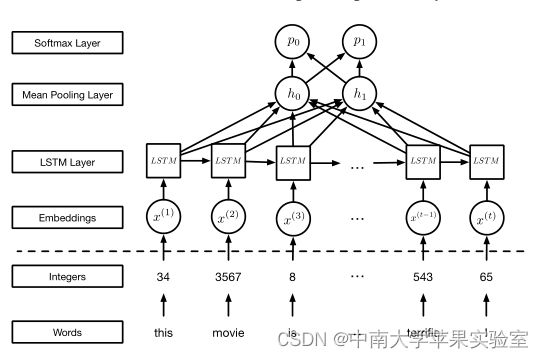
LSTM 通过引入记忆单元来防止训练时梯度爆炸和消失,与普通 RNN 相比,这为自循环连接提供了更大的灵活性,使其能够记住或忘记以前的状态。
对抗序列
对抗序列,即模型错误分类的句子。因此,我们需要识别字典单词,我们可以使用这些单词来修改句子 ~ x,从而将其预测类别从正面转换为负面(反之亦然)。

算法1迭代地修改输入句子~ x 中的单词 i 以产生被 LSTM 架构 f 错误分类的对抗序列 ~x∗
对于输入序列的每个词 i, 其中 给出了我们必须扰乱每个词嵌入组件的方向,以降低分配给当前类的概率,从而改变分配给句子。
实验结果
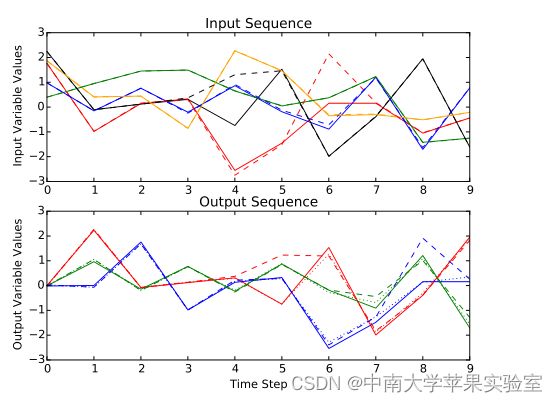
实验设置的示例输入和输出序列在输入图中,实线表示合法输入序列,而虚线表示精心制作的对抗序列。在输出中,实线表示训练目标输出,虚线表示模型预测,虚线表示模型对对抗序列的预测。
conclusion
在本文中,我们考虑了一个描述对手的威胁模型,该模型具有访问模型架构(其计算图)的能力,包括训练期间学习的参数值。在现实环境中,如果对手无法访问托管机器学习模型的系统,则并不总是能够获取这些参数的知识。我们形式化了制作对抗序列以操纵 RNN 模型输出的问题。我们展示了先前引入的用于制作被神经网络分类器错误分类的对抗样本的技术如何适应产生顺序对抗输入,特别是通过使用计算图展开。
未来的工作应该研究不同数据类型的对抗序列。正如我们的实验所示,从计算机视觉转换到自然语言处理应用程序带来了困难。与以前的工作不同,我们必须在攻击中考虑数据的预处理。在较弱的威胁模型下执行攻击也将有助于更好地了解漏洞并导致防御。