sklearn专题六:聚类算法K-Means
目录
1 概述
1.1 无监督学习与聚类算法
1.2 sklearn中的聚类算法
2 KMeans
2.1 KMeans是如何工作的
2.2 簇内误差平方和的定义和解惑
2.3 KMeans算法的时间复杂度
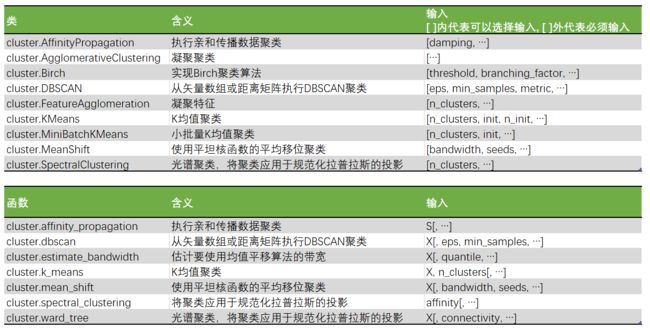
3 sklearn.cluster.KMeans
3.1 重要参数n_clusters
3.1.1 先进行一次聚类看看吧
3.1.2 聚类算法的模型评估指标
3.1.2.1 当真实标签已知的时候
3.1.2.2 当真实标签未知的时候:轮廓系数
3.1.2.3 当真实标签未知的时候:Calinski-Harabaz Index
3.1.3 案例:基于轮廓系数来选择n_clusters
3.3 重要参数max_iter & tol:让迭代停下来
3.4 重要属性与重要接口
3.5 函数cluster.k_means
4 案例:聚类算法用于降维,KMeans的矢量量化应用
1 概述
1.1 无监督学习与聚类算法
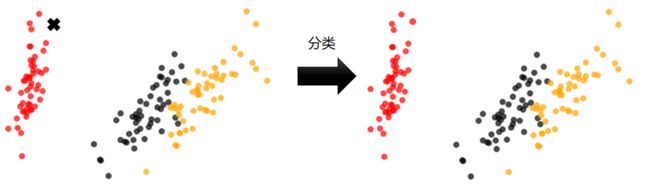


1.2 sklearn中的聚类算法
2 KMeans
2.1 KMeans是如何工作的



在数据集下多次迭代(iteration),就会有:

2.2 簇内误差平方和的定义和解惑

如我们采用欧几里得距离,则一个簇中所有样本点到质心的距离的平方和为:


2.3 KMeans算法的时间复杂度
3 sklearn.cluster.KMeans
3.1 重要参数n_clusters
3.1.1 先进行一次聚类看看吧
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
#自己创建数据集
# n_samples:表示数据样本点个数,默认值100
# n_features:是每个样本的特征(或属性)数,也表示数据的维度,默认值是2
# centers:表示类别数(标签的种类数),默认值3
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
#画图
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]#.scatter散点图
,marker='o' #点的形状
,s=8 #点的大小
)
plt.show() 
如果我们想要看见这个点的分布,怎么办?
#如果我们想要看见这个点的分布,怎么办?
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
plt.show()
基于这个分布,我们来使用Kmeans进行聚类。首先,我们要猜测一下,这个数据中有几簇?
1.导库,分3簇
from sklearn.cluster import KMeans
n_clusters = 32.建模
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
#重要属性Labels_,查看聚好的类别,每个样本所对应的类
y_pred = cluster.labels_
y_pred #分成0 1 2这么3个簇
KMeans因为并不需要建立模型或者预测结果,因此我们只需要fit就能够得到聚类结果了
KMeans也有接口predict和fit_predict,表示学习数据X并对X的类进行预测
但所得到的结果和我们不调用predict,直接fit之后调用属性labels一模一伴
pre = cluster.fit_predict(X)
pre我们什么时候需要predict呢?当数据量太大的时候!
其实我们不必使用所有的数据来寻找质心,少量的数据就可以帮助我们确定质心了
当我们数据量非常大的时候,我们可以使用部分数据来帮助我们确认质心
剩下的数据的聚类结果,使用predict来调用
3.提取200个样本确定质心
cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:200]) #选择200个样本
y_pred_ = cluster_smallsub.predict(X)
y_pred_y_pred == y_pred_#数据量非常大的时候,效果会好
但从运行得出这样的结果,肯定与直接fit全部数据会不一致。有时候,当我们不要求那么精确,或者我们的数据量实在太大,那我们可以使用这种方法,使用接口predict
如果数据量还行,不是特别大,直接使用fit之后调用属性.labels_提出来
4.重要属性cLuster_centers_,查看质心
centroid = cluster.cluster_centers_
centroid
'''
array([[-8.0807047 , -3.50729701],
[-1.54234022, 4.43517599],
[-7.11207261, -8.09458846]])
'''5.要属性inertia_,查看总距离平方和
inertia = cluster.inertia_
inertia
'''
1903.5607664611762
'''6.画图
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred==i, 0], X[y_pred==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
ax1.scatter(centroid[:,0],centroid[:,1]
,marker="x"
,s=15
,c="black")
plt.show()
7.如果我们把猜测的羡数换成4,Inertia会怎么样?
#如果我们把猜测的羡数换成4,Inertia会怎么样?
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
'''
908.3855684760613
'''3.1.2 聚类算法的模型评估指标

那我们可以使用什么指标呢?分两种情况来看。
3.1.2.1 当真实标签已知的时候

3.1.2.2 当真实标签未知的时候:轮廓系数


from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
X
y_pred
silhouette_score(X,y_pred)
silhouette_samples(X,y_pred)3.1.2.3 当真实标签未知的时候:Calinski-Harabaz Index
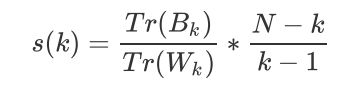
 是组间离散矩阵,即不同簇之间的协方差矩阵,
是组间离散矩阵,即不同簇之间的协方差矩阵,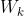 是簇内离散矩阵,即一个簇内数据的协方差矩阵,而 tr 表示矩阵的迹。在线性代数中,一个 n×n 矩阵 A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵 A的迹(或迹数),一般记作
是簇内离散矩阵,即一个簇内数据的协方差矩阵,而 tr 表示矩阵的迹。在线性代数中,一个 n×n 矩阵 A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵 A的迹(或迹数),一般记作from sklearn.metrics import calinski_harabasz_score
X
y_pred
calinski_harabasz_score(X, y_pred)
'''
1809.991966958033
'''from time import time
#time():记下每一次time()这一行命令时的时间戳
#时间戳是一行数字,用来记录此时此刻的时间
t0 = time()
calinski_harabasz_score(X, y_pred)
time() - t0 #0.0009980201721191406
t0 = time()
silhouette_score(X,y_pred)
time() - t0 #0.005983114242553711
#时间戳可以通过datetime中的函数fromtimestamp转换成真正的时间格式
import datetime
datetime.datetime.fromtimestamp(t0).strftime("%Y-%m-%d %H:%M:%S")
#'2021-12-22 17:44:21'3.1.3 案例:基于轮廓系数来选择n_clusters
#导库
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm #colormap
import numpy as np
import pandas as pd
n_clusters = 4
fig, (ax1, ax2) = plt.subplots(1, 2) #分成2个布
fig.set_size_inches(18,7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data"
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
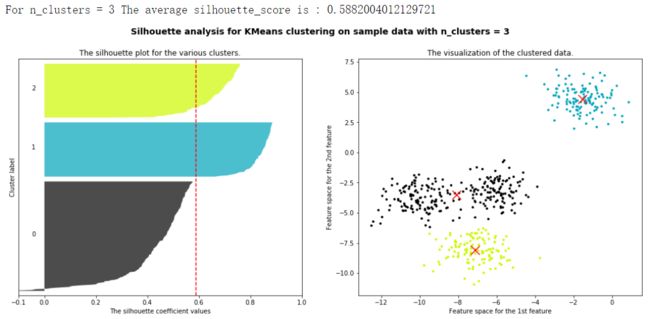
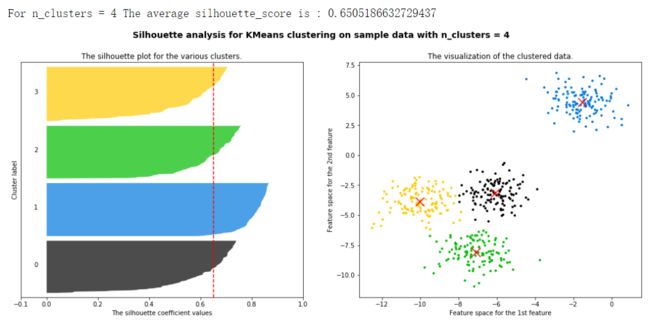
将上述过程包装成一个循环,可以得到:
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
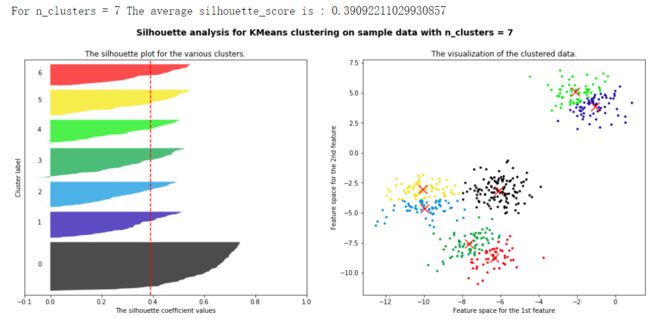
for n_clusters in [2,3,4,5,6,7]:
n_clusters = n_clusters
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()

X.shape
y.shape
plus = KMeans(n_clusters = 10).fit(X)
plus.n_iter_ #12
random = KMeans(n_clusters = 10,init="random",random_state=420).fit(X)
random.n_iter_ #19
3.3 重要参数max_iter & tol:让迭代停下来
random = KMeans(n_clusters = 10,init="random",max_iter=10,random_state=420).fit(X)
y_pred_max10 = random.labels_
silhouette_score(X,y_pred_max10)
'''
0.3952586444034157
'''
random = KMeans(n_clusters = 10,init="random",max_iter=20,random_state=420).fit(X)
y_pred_max10 = random.labels_
silhouette_score(X,y_pred_max10)
'''
0.3401504537571701
'''3.4 重要属性与重要接口


3.5 函数cluster.k_means
from sklearn.cluster import k_means
k_means(X,4,return_n_iter=True)4 案例:聚类算法用于降维,KMeans的矢量量化应用

import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin
#对两个序列中的点进行距离匹配的函数
from sklearn.datasets import load_sample_image
#导入图片数据所用的类
from sklearn.utils import shuffle #洗牌
# 实例化,导入颐和园的图片
china = load_sample_image("china.jpg")
#查看数据类型 dtype('uint8')
china.dtype
china.shape
#长度 x 宽度 x 像素 > 三个数决定的颜色 (427, 640, 3)
#包含多少种不同的颜色?
newimage = china.reshape((427 * 640,3))
import pandas as pd
pd.DataFrame(newimage).drop_duplicates().shape
#我们现在有9W多种颜色 (96615, 3)
# 图像可视化
plt.figure(figsize=(15,15))
plt.imshow(china) #导入3维数组形成的图片
#查看模块中的另一张图片
flower = load_sample_image("flower.jpg")
plt.figure(figsize=(15,15))
plt.imshow(flower)
n_clusters = 64
china = np.array(china, dtype=np.float64) / china.max()
w, h, d = original_shape = tuple(china.shape)
assert d == 3
image_array = np.reshape(china, (w * h, d))
#plt.imshow在浮点数上表现非常优异,在这里我们把china中的数据,转换为浮点数,压缩到[0,1]之间
china = np.array(china, dtype=np.float64) / china.max()
#把china从图像格式,转换成矩阵格式
w, h, d = original_shape = tuple(china.shape)
#展示assert的功能
d_ = 3
assert d_ == 3, "一个格子中特征数不等于3"
image_array = np.reshape(china, (w * h, d)) #reshape是改变结构
image_array
image_array.shape
a = np.random.random((2,4))
a.reshape((4,2)) == np.reshape(a,(4,2))
np.reshape(a,(2,2,2)).shape
np.reshape(a,(8,1))4. 对数据进行K-Means的矢量量化
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
kmeans.cluster_centers_
labels = kmeans.predict(image_array)
labels.shape
image_kmeans = image_array.copy()
for i in range(w*h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans
pd.DataFrame(image_kmeans).drop_duplicates().shape
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shapecentroid_random = shuffle(image_array, random_state=0)[:n_clusters]
labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0)
labels_random.shape
len(set(labels_random))
image_random = image_array.copy()
for i in range(w*h):
image_random[i] = centroid_random[labels_random[i]]
image_random = image_random.reshape(w,h,d)
image_random.shapeplt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(image_kmeans)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(image_random)
plt.show()

