deepsort原理快速弄懂——时效比最高的
主要转载自:DeepSort - 博博的Blog - 博客园
分模块的代码参考:目标跟踪初探(DeepSORT) - 知乎
补充
- 这个系列有两个算法,sort和deep sort,这里先介绍sort。sort的思路很简单,首先通过检测器例如faster rcnn把每一帧的物体检测出来,之后通过卡尔曼滤波器预测物体在下一帧的位置,将预测的位置与下一帧实际检测到的位置做IOU的计算,得到相邻两帧物体的相似度,最后利用匈牙利匹配得到相邻帧的对应id。由于这里只是计算框的重叠面积,因此如果两个物体发生遮挡,会出现id交换的情况,所以作者为了降低id交换,提出了deep sort算法。deep sort之所以可以把id交换降低45%,是因为它将面积匹配修改为了特征匹配。在匹配之前作者利用resnet50先将特征里取出来,由于一般情况下很少会遇到外观特征完全相同的两个物体,因此这种改进是有效的。deep dort由于很简单,因此没有在顶会上发表成功(发表在ICIP 2017),但是由于其可以保证在高速度的情况下的高准确度,所以广泛应用在了工程实践的过程中。
- Deepsort是对于sort的思想,进行的改进算法。SORT算法使用简单的卡尔曼滤波处理逐帧数据的关联性以及使用匈牙利算法进行关联度量,这种简单的算法在高帧速率下获得了良好的性能。但由于SORT忽略了被检测物体的表面特征,因此只有在物体状态估计不确定性较低是才会准确,在Deep SORT中,使用了更加可靠的度量来代替关联度量,并使用CNN网络在大规模行人数据集进行训练,并提取特征,已增加网络对遗失和障碍的鲁棒性。
- 问题:为什么有了高精度的目标检测器(如YOLO5)的观测值,每次还需要通过卡尔曼滤波修正目标框位置?
- 答:有时候,跟踪对象会被遮挡,即本帧某目标的观测值是没有的,如果只用观测值不用预测值,这个目标就跟丢了。
以下是转载内容:
目录
1、匈牙利算法
2、卡尔曼滤波
3、DeepSort工作流程
标跟踪任务的难度和复杂度要比分类和目标检测高不少,具有更大的挑战性。

目前主流的目标跟踪算法都是基于Tracking-by-Detection(检测加跟踪,使效果更稳定)策略,即基于目标检测的结果来进行目标跟踪。DeepSORT运用的就是这个策略,上面的视频是DeepSORT对人群进行跟踪的结果,每个bbox左上角的数字是用来标识某个人的唯一ID号。
这里就有个问题,视频中不同时刻的同一个人,位置发生了变化,那么是如何关联上的呢?答案就是匈牙利算法和卡尔曼滤波。匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同。卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。
1、匈牙利算法
首先,先介绍一下什么是分配问题(Assignment Problem):假设有N个人和N个任务,每个任务可以任意分配给不同的人,已知每个人完成每个任务要花费的代价不尽相同,那么如何分配可以使得总的代价最小。
举个例子,假设现在有3个任务,要分别分配给3个人,每个人完成各个任务所需代价矩阵(cost matrix)如下所示(这个代价可以是金钱、时间等等):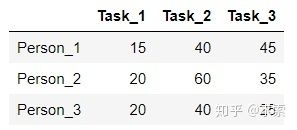
怎样才能找到一个最优分配,使得完成所有任务花费的代价最小呢?
匈牙利算法(又叫KM算法)就是用来解决分配问题的一种方法,它基于定理:
如果代价矩阵的某一行或某一列同时加上或减去某个数,则这个新的代价矩阵的最优分配仍然是原代价矩阵的最优分配。
算法步骤(假设矩阵为NxN方阵):
(1)对于矩阵的每一行,减去其中最小的元素
(2)对于矩阵的每一列,减去其中最小的元素
(3)用最少的水平线或垂直线覆盖矩阵中所有的(4)如果线的数量等于N,则找到了最优分配,算法结束,否则进入步骤5
(5)找到没有被任何线覆盖的最小元素,每个没被线覆盖的行减去这个元素,每个被线覆盖的列加上这个元素,返回步骤3
继续拿上面的例子做演示:
step1 每一行最小的元素分别为15、20、20,减去得到:
step2 每一列最小的元素分别为0、20、5,减去得到: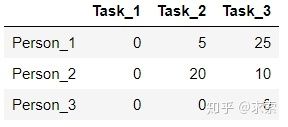
step3 用最少的水平线或垂直线覆盖所有的0,得到:
step4 线的数量为2,小于3,进入下一步;
step5 现在没被覆盖的最小元素是5,没被覆盖的行(第一和第二行)减去5,得到:
被覆盖的列(第一列)加上5,得到:
跳转到step3,用最少的水平线或垂直线覆盖所有的0,得到:
step4:线的数量为3,满足条件,算法结束。显然,将任务2分配给第1个人、任务1分配给第2个人、任务3分配给第3个人时,总的代价最小(0+0+0=0):
所以原矩阵的最小总代价为(40+20+25=85):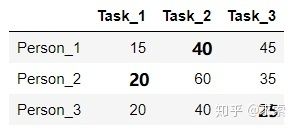
在DeepSORT中,匈牙利算法用来将前一帧中的跟踪框tracks与当前帧中的检测框detections进行关联,通过外观信息(appearance information)和马氏距离(Mahalanobis distance),或者IOU来计算代价矩阵。
2、卡尔曼滤波
卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域,简单来说,其作用就是基于传感器的测量值来更新预测值,以达到更精确的估计。
假设我们要跟踪小车的位置变化,如下图所示,蓝色的分布是卡尔曼滤波预测值,棕色的分布是传感器的测量值,灰色的分布就是预测值基于测量值更新后的最优估计。
在目标跟踪中,需要估计track的以下两个状态:
- 均值(Mean):表示目标的位置信息,由bbox的中心坐标 (cx, cy),宽高比r,高h,以及各自的速度变化值组成,由8维向量表示为 x = [cx, cy, r, h, vx, vy, vr, vh],各个速度值初始化为0。
- 协方差(Covariance ):表示目标位置信息的不确定性,由8x8的对角矩阵表示,矩阵中数字越大则表明不确定性越大,可以以任意值初始化。
卡尔曼滤波分为两个阶段:(1) 预测track在下一时刻的位置,(2) 基于detection来更新预测的位置。
预测
基于track在t-1时刻的状态来预测其在t时刻的状态。
![]()
![]()
在公式1中,x为track在t-1时刻的均值,F称为状态转移矩阵,该公式预测t时刻的x':

矩阵F中的dt是当前帧和前一帧之间的差,将等号右边的矩阵乘法展开,可以得到cx'=cx+dtvx,cy'=cy+dtvy...,所以这里的卡尔曼滤波是一个匀速模型(Constant Velocity Model)。
在公式2中,P为track在t-1时刻的协方差,Q为系统的噪声矩阵,代表整个系统的可靠程度,一般初始化为很小的值,该公式预测t时刻的P'。
更新
基于t时刻检测到的detection,校正与其关联的track的状态,得到一个更精确的结果。
![]()
![]()
![]()
![]()
![]()
- 公式3:z为detection的均值向量,不包含速度变化值,即z=[cx, cy, r, h],H称为测量矩阵,它将track的均值向量x'映射到检测空间,该公式计算detection和track的均值误差;
- 公式4:R为检测器的噪声矩阵,它是一个4x4的对角矩阵,对角线上的值分别为中心点两个坐标以及宽高的噪声,以任意值初始化,一般设置宽高的噪声大于中心点的噪声,该公式先将协方差矩阵P'映射到检测空间,然后再加上噪声矩阵R;
- 公式5:计算卡尔曼增益K,卡尔曼增益用于估计误差的重要程度;
- 公式6、公式7:得到更新后的均值向量x和协方差矩阵P。
3、DeepSort工作流程
DeepSORT对每一帧的处理流程如下:
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
Frame 0:检测器检测到了3个detections,当前没有任何tracks,将这3个detections初始化为tracks
Frame 1:检测器又检测到了3个detections,对于Frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配,得到(track, detection)匹配对,最后用每对中的detection更新对应的track