[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed
EfficientFormer:Vision Transformers at MobileNet Speed
- Abstract
- Section I Introduction
- Section II Related Work
- Section III On-Device Latency Analysis of Vision Transformers
- Section IV Design of EfficientFormer
-
- Part 1 Dimension-consistent Design
- Part 2 Latency Driven Slimming
- Section V Experimentd and Discussions
-
- Part 1 Image Classification
- Part 2 EfficientFormer as Backbone
- Part 3 Discussion
- Section IV Conclusion
EfficientFormer:达到MobileNet速度的Vision Transformer
Abstract
视觉Transformer在计算机视觉任务领域发展循序,取得了令人深刻的优异表现。但是由于模型中注意力机制的设计和海量的参数使得基于ViT的模型往往比轻量级的卷积模型慢好几倍。因此使得VT的实时性部署就十分具有挑战性,尤其想在移动端这种资源受限的硬件上。近期有的研究尝试通过NAS或混合设计化简ViT的计算复杂度,但是推理速度仍然不尽如人意。从而衍生一个重要的问题:Transformer真的能在保持高性能的前提下达到和MobileNet一样的速度吗?
为了回答这一问题本文首先回顾了ViT的网络结构额其中使用的运算操作,找到其中低效的部分。然后本文引入一个维度一致的Transformer模型作为设计范式。最后本文进行延迟驱动的裁剪惹怒来获得一系列EfficientFormer。
实验结果显示获得的模型在移动端上性能和推理速度都十分有益,最优秀的模型在ImageNet-1K上达到了79.2%的分类精度同时在iPhone12上的推理速度进位1.6ms,比MobineNet的速度还快。本文最大的模型L7则达到了7.0ms推理速度下83.3%的分类精度,本文的工作证明了对Transformer进行设计后可以在移动端同时保证高精度和快速推理。
Section I Introduction
Transformer最初用于NLP任务,其多投资注意力机制使得模型可以有效建模长程依赖并且十分便于并向华。ViT将transformer用于2D图像,输入图像被分成互不重叠的patch,每一块patch获得一个表征送入MHSA中进行处理和学习。
![[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed_第1张图片](http://img.e-com-net.com/image/info8/6a55a36b04ab4e3fa00a7ccac585d2dc.jpg)
ViT在图像处理方面取得了可与CNN相媲美的性能,后续也有对ViT做进一步改进,如网络结构改进、注意力机制的重设计以及用于分割、检测任务等。
但是Transformer模型一般比对应的CNN模型更慢,以下因素限制了ViT子硬件上的推理速度:海量的参数、随着token长度指数增长的计算复杂度,正则化层不可折叠,缺少编译优化。因此阻碍了Transformer的实时部署,尤其在可穿戴设备、移动端倪等资源有限的硬件上的部署。因此轻量化CNN依然是事实推理的默认首选。
为了缓解Transformer模型的延迟瓶颈,也提出了诸多改进。如将线性层替换为卷积层、将自注意力与MobileNet模块结合或者使用系数注意力来减少计算成本,亦或是引入搜索技术或者剪枝技术来提升效率。虽然取得了一定的成效,也自然产生衣蛾问题悬而未决:难道强大的ViT模型真的无法和MobileNet模型一样快,MobileNet依然是边缘设备的默认选项?
本文做了以下探索:
(1)首先本文重新回顾了ViT及其变体并且对延迟进行了分析。本文使用iPhone12作为硬件测试平台,CoreML作为编译器。
(2)基于前面的分析本文找到ViT中抵消的部分,提出一个新的维度一致的ViT设计范式。
(3)本文遵循这一设计范式从一个抄网开始,使用延迟驱动的修剪方法来获得一系列精简后的模型,称之为EfficientFormers,直接对延迟而不是MAC或者参数量进行了优化。
本文最快的模型EfficientFormer-L1达到了79.2%的分类精度,延迟仅有1.6ms,比MobileNetV2精度提升7.4%,延迟下降6%。最大的模型EfficientFromer-L7达到了83.3%的精度,延迟为7.0ms,比ViT-MobilNet混合设计更快。并且本文的EfficientFormer作为backbone用于检测和分割任务也取得了极其优异的性能。
也回答了本文最初的问题:ViT可以同时达到高精度和快速的推理速度。本文希望EfficientFormer可以作为一类baseline模型,并且为后续ViT在边缘设备的部署提供思路。
Section II Related Work
Transformer最初用于NLP任务中学习长序列,后来ViT将其用于图像分类和目标检测任务,取得了可与CNN相媲美的结果。DeiT进一步优化了Transformer的训练过程不用大规模的预训练,后续还有进一步研究卷积与ViT的结合。
但是Transformer还是无法与轻量级CNN相比较,主要是推理时间方面。
为了加速ViT也进行了一系列改进,如重新设计自注意力、稀疏化注意力或者使用搜索算法。代表性工作有LeViT,MobileViT。本文与他们不同的是设计的是纯Transformer模型,进一步优化延迟,而不是依靠混合设计来加速。
Section III On-Device Latency Analysis of Vision Transformers
大多数方法都是优化MAC乘累加或者吞吐量(每秒处理的图像数)但是这些指标并不能真正反映在硬件上的延迟,为了更好的找到到底是哪种操作或者设计减慢了ViT在边缘设备上的推理速度本文进行了大量全面的延迟分析,总结在Fig 2.
![[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed_第2张图片](http://img.e-com-net.com/image/info8/e9e9a92a681b4441a521161f48cac41d.jpg)
有以下观察现象:
现象1:以较大步长和卷积核的patch嵌入是移动端部署的速度瓶颈。
patch embedding通常通过使用较大卷积核的卷积层实现,经常这部分的计算成本可以忽略不计,但是本文发现使用较大卷积核和步长的patch embedding是主要的瓶颈所在。
因为大多数编译器不支持大核卷积对大核卷积的优化和支持也不够好,不能用Winograd等优化,但互不重叠的patch embedding可以替换为使用快速下采样的卷积stem实现。
现象2:保持一致的维度对于token mixer的选择十分重要。MHSA不一定就是速度瓶颈。
近期有工作将基于ViT的模型拓展到MetaFormer包含MLP模块和tokenmixer,其中token mixer的选择十分重要,但是选择项也很多,比如常规的MHSA mixer带有全局感受野,或者使用移动窗口注意力、池化等。本文将比较缩小到两种标记混合器,池化和MHSA,其中我们选择前者
因其简单和高效,而后者性能更好。更复杂的token mixer
像移动窗口这样的目前不支持大多数公共移动编译,放在本次研究范围之外。此外,我们不使用深度卷积来代替池化,因为我们专注于构建架构,不借助网络轻量化。
从以下方面比较二者的延迟:
首先通过比较PoolFormer-s24和LeViT-256本文发现Reshape操作是LeViT的瓶颈,LeViT主要处理4D卷积需要频繁的reshape操作,送入MHSA有序要丢掉额外的维度,限制了LeViT在移动设备上的表现。
另一方面池化天然适合4D张量尤其是主要是卷积的网络,这也是为什么PoolFormer推理速度更快的原因。
其次本文比较了DeiT和LeViT发现MHSA不会过于增加延迟,因为特征维度都是一致的,虽然DeiT更加计算密集但是可以达到LeViT相近的推理速度。
观察3:CONV-BN比LN-linear组合延迟更短,精度损失也可接受。
MLP的设计也很重要,通常LN搭配线性映射使用,BN搭配1x1卷积使用。
CONV-BN延迟更短,因为推理时BN可以折叠进卷积的计算过程中,而LN推理的时候需要运行时数据因此无法加速,使得延迟更久。基于本文的实验结果和前人的工作分析,一般LN引入的延迟占了整个网络的10%-20%。
基于本文进行的消融实验conv-bn只会使得精度略微下降,因此本文尽可能使用conv-bn而不是LN来缩短延迟。如果是处理3D特征再考虑使用LN。
观察4:非线性的延迟随着硬件和编译器的不同而变化。
最后本文分析了非线性计算部分,包括GeLU,ReLU,HardSwish等。前人的工作分析GeLU并不适合硬件部署会增加延迟,但是本文发现iPhone12上对GeLU的支持很好。而Hardswish可能是由于编译器支持的不好使得延迟很慢,达到了44.5ms而GeLU只有11.9ms。因此本文人为非线性的部分应该具体部署具体分析,取决于实验的硬件平台和编译器的支持效果。
![[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed_第3张图片](http://img.e-com-net.com/image/info8/641274671ce84df2b64cb870c15df676.jpg)
Section IV Design of EfficientFormer
基于上述对延迟的分析本文提出EfficientFormer的设计,具体参见Fig 3.可以看到网络包括patch embedding,meta transformer模块的堆叠(MB):

其中X0表示输入的一批图像,m表示最终深度。
MB包含一系列token mixer,之后经过MLP的处理:

整个网络包含4个阶段,每个阶段都有一次嵌入操作用于输入维度的映射和token长度的下采样。
整个网络是纯Transformer结构,并没有借助MobineNet。接下来对每一块进行详细介绍。
Part 1 Dimension-consistent Design
本文提出维度一致的设计方法,将整个网络分成4D部分和3D部分,4D部分堆叠MB,3D部分执行线性映射和MHSA,但前面都是4D部分只有最后一个阶段是3D
首先输入图像会经过conv stem的处理,这一步经过两个3x3卷积,步长为2,完成patch embedding操作:

其次送入MB模块和pool mixer进行处理。这里并没有使用LN或者GN 而只是用了BN。

经过完所有的MB模块进行一次reshape操作,将特征维度变为适合3D输入的情况,然后最后一个stage遵循常规的ViT结构,经过linear和MHSA的计算。
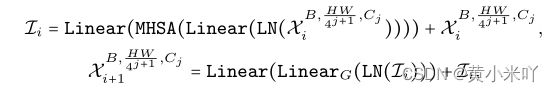

Part 2 Latency Driven Slimming
Design of Supernet
本文设计了一个超网用于寻找高效的网络模型,MetaPath(MP)是一系列可能模块的集合:
在这里插入图片描述
其中I代表identity path
每一个模块可以从MB和I中选择,最后两个stage规定只能从MB3D中选。主要有以下两个原因:
1-MHSA的计算复杂度会随着输入token的长度指数上升,使得计算成本也指数爆炸
2-全局的MHSA操作可以与早期的提取低级特征的操作互为补充,这样后面的模块主要负责学习长程依赖关系。
Searching space
搜索空间包含每个stage的宽度Cj,block的数目N以及最后几个stage使用MB3D模块
Searching Algorithm
早期的硬件感知的网络主要依赖于网络实际部署获得延迟数据,这十分费时因此本文提出基于梯度下降的候选网络算法来训练超网。
首先会训练超网,获得每个MP中不同模块的权重:
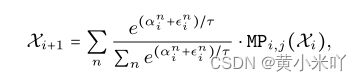
其次会建立一个延迟信息的查找表,基于已经收集到的数据
最后执行网络剪切操作,裁剪超网获得最终的网络。
因为如果根据不用的宽度设计网络这在内存上是无法负担的因此本文采用这种逐渐瘦身的方法。
本文会分别定义每个模块的重要性分数,最终将所有MP加和就获得了最终的总的重要性分数。基于重要性分数本文就可以确定action space:
(1)将重要性最低的MP替换为I
(2)将第一个MB3D移除
(3)将最不重要的stage减少宽度
然后计算每个操作的延迟,加和获得最终的延迟,同时计算精度
最后选择per-latency accuracy drop最高的作为最终网络。
Section V Experimentd and Discussions
本文的EfficientFormer基于Pytorch框架实现,在A100和V100上进行训练。取在iPhone12上运行1000次的平均值作为speed
Part 1 Image Classification
在ImageNet-1K上开始训练,输入的图像尺寸为224x224,遵循DeiT中的训练设置,训练300个epochs,优化器为Adam
Comparison to CNNs
和CNN模型相比EfficientFormer可以更好的权衡精度和延迟。比如EfficientFormer-L1比MobineNeV2提升了7.4%的分类精度,L7达到了超过83%的分类精度同时比EfficientNet-B5快3倍,充分说明EfficientFormer系列模型的有效性,并且也证实了ViT类的模型不需要为了模型精度而牺牲延迟,更精确的ViT模型可以达到和轻量级CNN同样的精度水平。
![[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed_第4张图片](http://img.e-com-net.com/image/info8/8593fb6a79a04cf1ac7799e28662d3c7.jpg)
Comparisons to ViTs
虽然传统ViT仍然无法与CNN在延迟方面相媲美,比如DeiT-Tiny能达到呢Efficient-B0同样的精度但是延迟慢3.4倍,但是EfficientFormer-L3的精度比DeiT-Small更高,(82.4% : 81.2%),同时推理速度提升了4倍。再比如PoolFormer比对应的ViT快因为MHSA限制了推理速度,但是本文的EfficientFormer-L3的精度更高同时推理延迟提升了123%。
Comparison to Hybrid Design
目前的混合设计有LeViT系列和MobileViT 仍然受限于延迟瓶颈问题,比如LeViT-256的推理速度比DeiT-Small慢,同时精度低1%MobileViT是将MHSA与MobileNet相结合的,让然比对应的CNN模型慢,精度也低2.3%。而本文的EfficientFormer作为一个纯Transformer模型可以同时保证高精度和快速的推理速度,比如L7在能达到MibileViT-XS同等推理速度的前提下精度提升了8.5%。
Part 2 EfficientFormer as Backbone
接下来测试做目标检测和实力分割的性能。首先将EfficientFormer做backbone结合Mask RCNN来验证目标检测,基于COCO数据集。结果参见Tab 2.
![[TinyML]EfficientFormer:Vision Transformers at MobileNet Speed_第5张图片](http://img.e-com-net.com/image/info8/3846ed3c54784b528fcc540497b58691.jpg)
可以看到EfficientFormer一直比对应的CNN网络Resnet和Transformer模型-PoolFormer更好,在计算成本接近的情况下比ResNet50提升3.4 波形AP,比PoolFormer高1.3x 实例分割则是基于ADE20K数据集,本文将EfficientFormer作为backbone,结合Semantic FPN作为decoder,可以看到EfficientFormer持续比对应的CNN和Transformer有提升,比如比PoolFormer-S24提升3.2mIoU
Part 3 Discussion
Relationship to MetaFormer
EfficientFormer一定程度受启发于MetaFormer,与PoolFormer相比EfficientFormer强调维度匹配问题,这是引起推理低效的主要原因。结果就是EfficientFormer可以达到比PoolFormer更高的精度,这样也可以不牺牲推理速度就充分利用MHSA。本文重新设计了4D维度的划分方式,这是一种对硬件更友好的方式,在多个任务上都展示了其优势。
Limitations
(1)虽然EfficientFormer的设计基于硬件但是实际的推理速度依旧会随着平台的变化有所波动。比如硬件平台对GeLU的支持没有HardSwish好或者编译器支持的不好那么也需要修改响应的操作设计。
(2)本文提出的延迟驱动的裁剪方法简洁高效,但是如果基于枚举进行诸项搜索也是可以获得优异的网络的。
Section IV Conclusion
本文验证了ViT在移动设备上可以达到与CNN同样的推理性能。本文首先对ViT各部分及延迟瓶颈进行了分析,并且针对瓶颈部分提出EfficientFormer,基于维度一致的设计提出硬件友好的4D MetaBlock和3D MHSA模块,本文进一步提出延迟驱动的裁剪方式来进一步优化设计空间。在广泛的实验上证明了EfficientFormer可以达到与CNN相媲美的延迟性能,并且证实了ViT可以在边缘设备上达到极快的推理速度。未来本文将进一步探索EfficientFormer在资源受限设备上的应用。