yolov3 训练及数据集准备【记录】
------------------------------ 本文仅供学习交流,如有错误,望交流指教 ------------------------------
yolov3 训练及数据集准备【记录】
一、数据集的准备
0x00.文件目录结构
VOCdevkit
——VOC2018这个年号可以自行替换,但是注意同时修改脚本上的年号,否则找不到目录
————Annotations 存放所有的mxl标记文件,可由labelimg标注工具进行标注生成
————ImageSets
——————Main 存放4个txt文件,其中test.txt是测试集,train.txt是训练集,val.txt是验证集,trainval.txt是测试和验证集
————JPEGImages用于存放图片
————labels用于存转换后yolo标记格式的txt文件
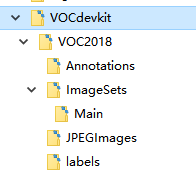
首先如上图新建好目录
0x01.生成 test.txt、train.txt、val.txt、trainval.txt
这里我使用了一个现成的python脚本,用于生成txt文件,脚本自动会获取图片名称,按比例生成不同的集图片名,使用的时候注意修改路径。
生成完毕后,应该会看到Main文件夹下会有四个txt文件,如果生成失败可以检查下:当前目录权限及脚本内的路径,注意图片命名不能有中文。
生成完毕后,因为接下来我们只用:val.txt验证集和train.txt训练集,所以将test.txt是测试集里的东西复制到验证集,我这只有10个图片用作简单测试,如果你的数据量大对模型有质量要求的,请仔细调整训练集和验证集的比例
目前为止我们就完成了voc的数据集制作

目前为止我们就完成了voc的数据集制作
需要转换成yolo的数据集格式,将.xml文件转换成yolo的txt
#python3
import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
0x02.voc标签文件.xml转yolo标签文件.txt
下载voc_label.py文件,将文件下载到VOCdevkit同级的路径下,生成训练和验证的文件列表
这个文件在darknet-master里面也有可以拿过来用,需要改下样本集的名称,及类的标签
wget https://pjreddie.com/media/files/voc_label.py
sets=[('2018', 'train'), ('2018', 'val')]#修改自己的年号只使用了训练和验证集
classes = ["wheel", "armor"]#修改为自己的标签
运行python voc_label.py跑完后它会在labels这个文件夹下,转换好所需要的yolo标签文件,
同时在VOCdevkit同级目录下生成:2018_train.txt、2018_val.txt 两个文件,yolo训练是要用这两个文件
在生成过程中发现,voc_label生成的直接是voc文件夹里的路径,这里我也就不改了,路径问题,大家都懂得,存哪都一样![]() 也就是说,其实不用把jpg文件放到data/images这个文件夹下,直接把yolo的标签文件txt复制到JPEGImages文件夹里就可以了
也就是说,其实不用把jpg文件放到data/images这个文件夹下,直接把yolo的标签文件txt复制到JPEGImages文件夹里就可以了
0x03.yolo的文件结构
yolov3 这个名字随意
——backup存储训练好的模型
——cfg用于存放配置文件.cfg和.data文件
——data存放图片、标签文件、名字文件(.names)
————images存放图片和yolo的txt文本,图片名和txt文本名对应
————labels存放用于opencv绘制图片框的图片文件
ps:
labels这个文件夹有的教程说存放yolo标签文件就是xml生成的txt文件,但是我尝试了下,会提示找不到标签文件,可能是yolov3的原因。
二、文件的修改配置
0x00.文件修改配置.cfg、.data、.names、下载权重文件
.cfg文件一会再说,咳咳。。。

.data文件的配置
cfg文件夹下新建:myv3_det.data文件
.data存放的各个文件的路径,修改成自己的路径,很容易修改。
classes= 4 #classes为训练样本集的类别总数
train = C:\Users\***\Desktop\win_yolo_xl\yolo3\yolo3\2018_train.txt #train的路径为训练样本集所在的路径
valid = C:\Users\***\Desktop\win_yolo_xl\yolo3\yolo3\2018_val.txt #valid的路径为验证样本集所在的路径
names = data\voc.names #names的路径为data/voc.names文件所在的路径
backup = backup
.names文件的配置
data文件夹下新建myv3.names文件
.name文件存放标签的名字,内部是通过ID转换的名字,例如下面,一行一个。
可以直接从labelimg标注工具中的predefined_classes.txt把名字复制出来
众所周知
labelimg工具是要先配置predefined_classes.txt再标注
别问我怎知道的,多画两遍框框就能理解我的痛
vehicle
armor
wheel
people

.cfg文件的配置
直接上一个我的配置吧,这个不全根据自己的情况修改
[net]
# Testing ### 测试模式
#batch=1
#subdivisions=1
# Training ### 训练模式,每次前向的图片数目 = batch/subdivisions
batch=16
subdivisions=8
width=416 ### 网络的输入宽、高、通道数
height=416
channels=3
momentum=0.9 ### 动量
decay=0.0005 ### 权重衰减
angle=0
saturation = 1.5 ### 饱和度
exposure = 1.5 ### 曝光度
hue=.1 ### 色调
learning_rate=0.001 ### 学习率
burn_in=1000 ### 学习率控制的参数
max_batches = 50200 ### 迭代次数
policy=steps ### 学习率策略
steps=40000,45000 ### 学习率变动步长
scales=.1,.1 ### 学习率变动因子
[convolutional]
batch_normalize=1### BN
filters=32 ### 卷积核数目
size=3 ### 卷积核尺寸
stride=1 ### 卷积核步长
pad=1 ### pad
activation=leaky ### 激活函数
#"此处省略并没卵用的若干"
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20 #类别
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1 #1,如果显存很小,将random设置为0,关闭多尺度训练;
#"此处省略并没卵用的若干"
[convolutional]
size=1
stride=1
pad=1
filters=27###75
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20 #类别
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1 #1,如果显存很小,将random设置为0,关闭多尺度训练;
#"此处省略并没卵用的若干"
[convolutional]
size=1
stride=1
pad=1
filters=27###75 27
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20 #类别
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1 #1,如果显存很小,将random设置为0,关闭多尺度训练;
这里引用下:https://blog.csdn.net/lilai619/article/details/79695109
A.filters数目是怎么计算的:3x(classes数目+5),和聚类数目分布有关,论文中有说明;
B.如果想修改默认anchors数值,使用k-means即可;
C.如果显存很小,将random设置为0,即关闭多尺度训练;
D.其他参数如何调整,有空再补;
E.前100次迭代loss较大,后面会很快收敛;
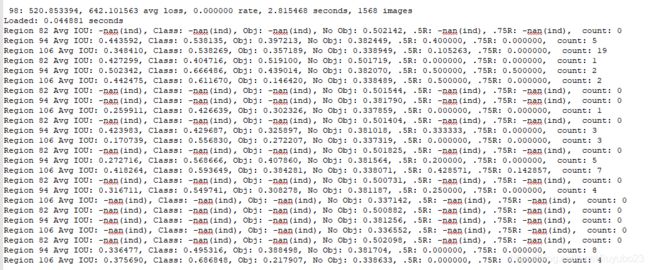
Region xx: cfg文件中yolo-layer的索引;
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count: 正样本数目。
下载Imagenet上预先训练的权重:
https://pjreddie.com/media/files/darknet53.conv.74
到目前为止就凑齐所有训练需要的文件了,
大家可以和下面的仔细核对一下
文件夹树
└─yolo3
│ 2018_train.txt#两个集
│ 2018_val.txt
│ Adarknet_yolo_v3_test.bat#用于启动训练
│ bad.list
│ darknet.exe
│ darknet53.conv.74#预训练权重文件
│ log.txt#日志文件非必须
│ predictions.jpg#输出标记好的图
│ pthreadGC2.dll
│ pthreadVC2.dll
│ test.bat
│ voc_label.py
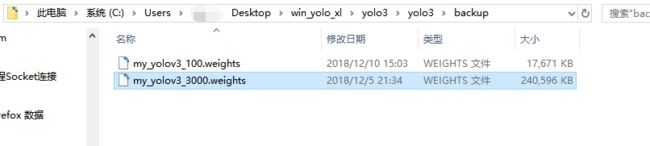
├─backup
│ my_yolov3_100.weights#训练好的模型
│ my_yolov3_3000.weights
├─cfg
│ myv3_det.data#不说了
│ my_yolov3.cfg
├─data
│ │ myv3.names
│ │ timg.jpg#只是用于最后测试顺手放这了
│ │
│ ├─images
│ └─labels
└─VOCdevkit
└─VOC2018
│ main4.py#生成4个txt
├─Annotations#存放所有voc的.xml文件
│ 1(1).xml
│ 1(10).xml
├─ImageSets
│ └─Main
│ test.txt
│ train.txt
│ trainval.txt
│ val.txt
├─JPEGImages
│ 1(1).jpg#所有图片
│ 1(1).txt
│ 1(10).jpg
│ 1(10).txt
└─labels
1(1).txt#由voc_label.py生成好的yolo的标签文件
1(10).txt
三、训练(吃火锅)
运行:
聪明的你一定会写一个命令,并且保存在xxx.bat文件里,这个命令直接把输出保存到了log.txt所以看不到输出,可以打开txt查看进度
darknet.exe detector train cfg/myv3_det.data cfg/my_yolov3.cfg darknet53.conv.74 -ext_outputpause>>log.txt
葛洲坝水利枢纽工程38公里处,来自三峡水力发电站的电力,通过1060.7公里长的输电电路,不远万里来到这里,在这个冰冷无情的寒夜里唯有训练模型和火锅,配的上这样的电力。
在火锅沸腾和一遍一遍的续水中,不知不觉模型已经训练了3000多次。
啥?你问我啥硬件?GTX1060呀,为啥训练那么快?3000次训练一顿火锅的时间?

吃火锅不小心睡着了。。。
先刷个锅,一会回来。。。
三、测试
经前面的训练相信你已经得到了这个文件,他是每100次保存一次,所以一开始是没有的。
随后我们用这个文件测试下:
darknet.exe detector test cfg/myv3_det.data cfg/my_yolov3.cfg backup/my_yolov3_3000.weights -i 0 -thresh 0.25 data/timg.jpg -ext_outputpause

参考:
https://blog.csdn.net/maweifei/article/details/81137563
https://blog.csdn.net/lilai619/article/details/79695109
非常有参考价值,很感谢作者