3d稀疏卷积——spconv源码剖析(一)
本节主要是介绍下卷积的理论基础。结合spconv代码剖析从第二小节开始介绍,本节介绍2D和3D卷积基础理论和稀疏卷积分类,后再详细介绍下3d稀疏卷积的工作原理。
2D卷积
2D卷积:卷积核在输入图像的二维空间进行滑窗操作
2D单通道卷积
对于2维卷积,一个3*3的卷积核,在单通道图像上进行卷积,得到输出的动图如下所示:

一张图像上使用卷积核进行扫描,得到一张特征图。这里的“被扫描图像”是一个通道,而非一张彩色图片。
2D多通道卷积
在一次扫描中,我们输入了一张拥有三个通道的彩色图像。对于这张图,拥有同样尺寸、但不同具体数值的三个卷积核会分别在三个通道上进行扫描,得出三个相应的“新通道”。由于同一张图片中不同通道的结构一定是一致的,卷积核的尺寸也是一致的,因此卷积操作后得出的“新通道”的尺寸也是一致的。

得出三个“新通道”后,我们将对应位置的元素相加,形成一张新图,这就是卷积层输入的三彩色图像的第一个特征图,如下图所示:
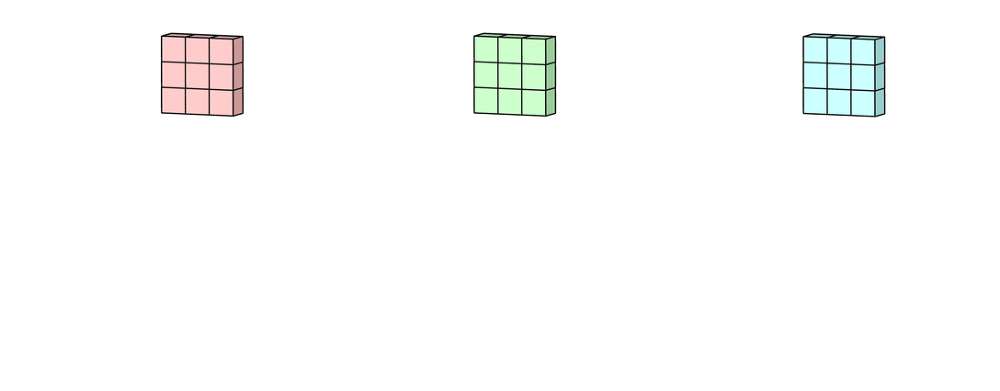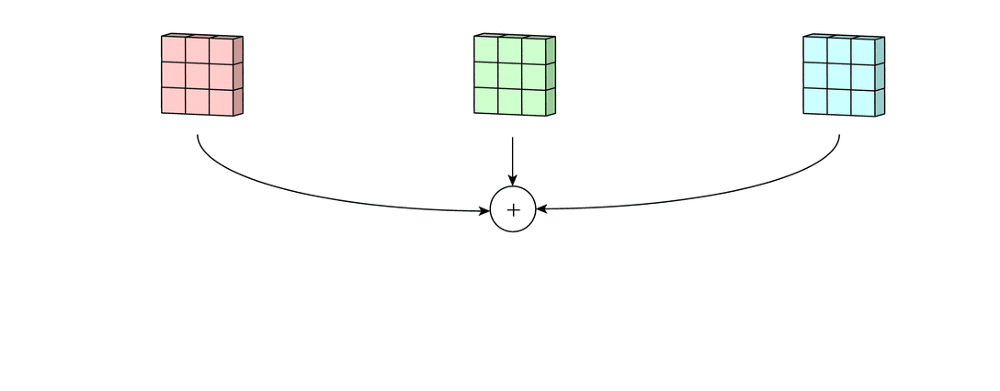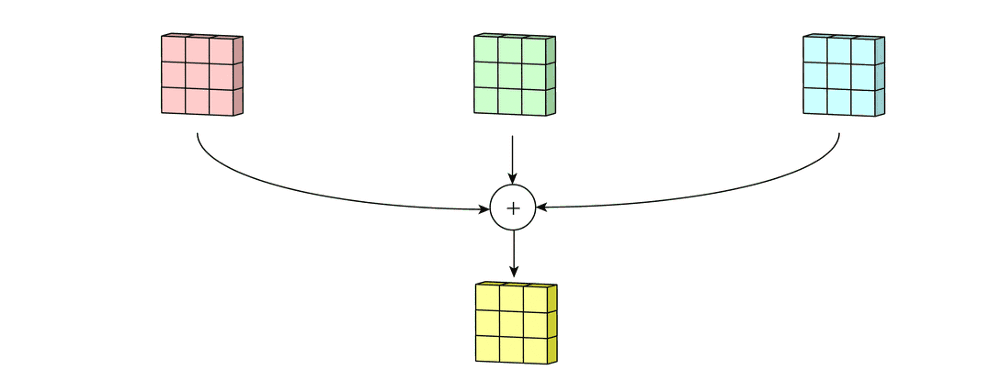
这个操作对于三通道的RGB图像、四通道的RGBA或者CYMK图像都是一致的。只不过, 如果是四通道的图像,则会存在4个同样尺寸、但数值不同的卷积核分别扫描4个通道。
因此,在一次扫描中,无论图像本身有几个通道,卷积核会扫描全部通道之后,将扫描结果加和为一张 feature map。所以,一次扫描对应一个feature map,无关原始图像的通道数目是多少,所以 out_channels就是扫描次数,这之中卷积核的数量就等于输入的通道数in_channels x 扫描次数 out_channels。
2D卷积的计算:
输入层: W i n ∗ H i n ∗ C i n W_{in}*H_{in}*C_{in} Win∗Hin∗Cin( C i n C_{in} Cin为输入的通道数)
超参数:
- 扫描次数:K
- 卷积核的维度:w*h
- 滑动步长stride:s
- 填充值padding:p
输出层: W o u t ∗ H o u t ∗ C o u t W_{out}*H_{out}*C_{out} Wout∗Hout∗Cout,输出层和输入层的参数关系:
- W o u t = W i n + 2 p − w s + 1 W_{out}=\frac{W_{in}+2p-w}{s}+1 Wout=sWin+2p−w+1
- H o u t = H i n + 2 p − h s + 1 H_{out}=\frac{H_{in}+2p-h}{s}+1 Hout=sHin+2p−h+1
- C o u t = k C_{out}=k Cout=k
考虑偏置参数量为: ( w ∗ h ∗ C i n + 1 ) ∗ C o u t (w*h*C_{in}+1)*C_{out} (w∗h∗Cin+1)∗Cout
考虑偏置计算量(乘加次数): C i n ∗ w ∗ h ∗ W o u t ∗ H o u t ∗ C o u t C_{in}*w*h*W_{out}*H_{out}*C_{out} Cin∗w∗h∗Wout∗Hout∗Cout
FLOPS(浮点运算量):
考虑偏置: 2 ∗ C i n ∗ w ∗ h ∗ W o u t ∗ H o u t ∗ C o u t 2*C_{in}*w*h*W_{out}*H_{out}*C_{out} 2∗Cin∗w∗h∗Wout∗Hout∗Cout
不考虑偏置: ( 2 ∗ C i n ∗ w ∗ h − 1 ) ∗ W o u t ∗ H o u t ∗ C o u t (2*C_{in}*w*h-1)*W_{out}*H_{out}*C_{out} (2∗Cin∗w∗h−1)∗Wout∗Hout∗Cout
乘和加分开,加的操作因为n个数相加所以减1,考虑偏置则补掉了加1
3D卷积
3D单通道
对于3维卷积,一个333的卷积核在立方体上进行卷积,得到输出如下:

注意:三维单通道跟二维多通道有什么区别吗?
有。二维多通道卷积不同通道上的卷积核的参数是不同的,而三维卷积的卷积核本身就是3D的。三维单通道的一个三维卷积核的参数在整个图像上权重共享。三维卷积核比二维卷积核多了一个depth维度。这个深度可能是视频上的连续帧,也可能是立体图像中的不同切片。
3D多通道
类似于2D多通道,例如,对于三维多通道,输入大小为(3, depth, height, width)的图像。
对于这张图,拥有同样尺寸、但不同具体数值的三个三维卷积核会分别在三个通道上进行扫描,得出三个相应的“新通道”。得出三个“新通道”后,我们将对应位置的元素相加,形成一张新图。
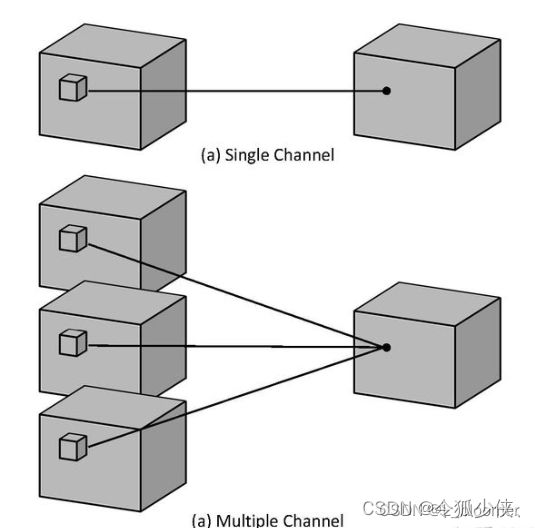
3D卷积的计算:
输入层: W i n ∗ H i n ∗ D i n ∗ C i n W_{in}*H_{in}*D_{in}*C_{in} Win∗Hin∗Din∗Cin( C i n C_{in} Cin为输入的通道数)
超参数:
- 扫描次数:K
- 卷积核的维度:w*h*d
- 滑动步长stride:s
- 填充值padding:p
输出层: W o u t ∗ H o u t ∗ D o u t ∗ C o u t W_{out}*H_{out}*D_{out}*C_{out} Wout∗Hout∗Dout∗Cout,输出层和输入层的参数关系:
- W o u t = W i n + 2 p − w s + 1 W_{out}=\frac{W_{in}+2p-w}{s}+1 Wout=sWin+2p−w+1
- H o u t = H i n + 2 p − h s + 1 H_{out}=\frac{H_{in}+2p-h}{s}+1 Hout=sHin+2p−h+1
- D o u t = D i n + 2 p − d s + 1 D_{out}=\frac{D_{in}+2p-d}{s}+1 Dout=sDin+2p−d+1
- C o u t = k C_{out}=k Cout=k
参数量为: ( w ∗ h ∗ d ∗ C i n + 1 ) ∗ C o u t (w*h*d*C_{in}+1)*C_{out} (w∗h∗d∗Cin+1)∗Cout
稀疏卷积分类
两种卷积操作:SC 和 VSC
SC(Sparse Convolution)
稀疏卷积操作sparse convolution,可以表示为SC(m, n, f, s), 其中m是input feature planes 的输入特征channel数;n是输出特征channel数; f是filter size; s是stride。
其中f可以是non-square filter。传统的filter size一般是3x3, 5x5 ...这里可以是1x7...
SC的input-output变化:当input大小是l的时候,输出就是 l − f + s s \frac{l-f+s}{s} sl−f+s 。没有涉及padding操作。- 传统dense卷积的
input-output变化为:当input大小是l的时候,输出就是 l − f + 2 p s + 1 \frac{l-f+2p}{s}+1 sl−f+2p+1 。其中p是padding像素数。
计算active site:site可以理解为image中的pixel和点云中的point,对第一层来说active site就是有数据的pixel或point,对之后层,如果这个site的感受野中存在active site,则这个site称为active site。SC卷积像传统的卷积一样计算active site
计算non-active site:把site的ground state(第一层的input值)直接设为0,之后输出也是0,这样non-active site相当被丢弃。在每一层SC卷积的input中是non-active的 site,在这一层输出的output中仍然是non-activa-site。这里跟传统卷积操作不一样。
VSC(valid sparse convolution)
有效的稀疏卷积(Valid Sparse Convolution)可以表示为VSC(m,n,f,1),是之前提到的SC(m,n,f,1)的变体。
VSC的input-output变化:VSC使用了大小为(f-1)/2的padding,输入和输出的大小相同- 计算
active site,对激活site进行限制(比如,下一层site的接收域中的中心site为激活的,该site才是激活的);SC的计算中,只要site的感受野中存在activate site,该site就会被看做active site。 - 计算
non-active site:与SC操作相同
使用SV或VSC构建的卷积网络会使用激活函数、BN层和pooling等组件
- 对于激活函数和
BN:操作只对active site使用- 对于
avg pooling:取active输入向量的和除以感受野的大小,不考虑non-active site- 对于
max-pooling: 取感受野内的最大值
稀疏卷积的原理
卷积神经网络已经被证明对于二维图像信号处理是非常有效的。然而,对于三维点云信号,额外的维数 z 显著增加了计算量。
另一方面,与普通图像不同的是,大多数三维点云的体素是空的,这使得三维体素中的点云数据通常是稀疏信号。
构建 Input Hash Table 和 Output Hash Table

input hash table和output hash table 对应上图的 Hash_in,和 Hash_out。对于 Hash_in:v_in 是下标,key_ in 表示value在input matrix中的位置。
现在的input一共两个元素 P1和P2,P1在input matrxi的(2, 1)位置, P2在 input matrix 的(3,2)的位置,并且是 YX 顺序。
这里只记录一下p1的位置 ,先不管 p1代表的数字把这个input hash table命名为 input position hash table。
input hash tabel的构建完成了,接下来构建 output hash table。
用一个kernel去进行卷积操作:
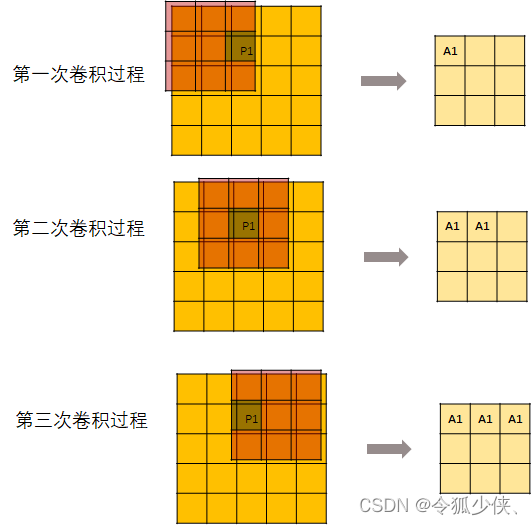
但是,并不是每次卷积kernel都可以刚好碰到P1。所以,从第7次开始,输出的这个矩阵就不再变化了。

然后记录每个元素的位置。
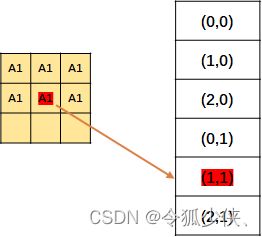
上面说的只是操作P1,当然P2也是同样的操作。

构建 GetOffset()
如下图所示,以output中(0,0)位置为例,该点的值是input左上角的窗口卷积得到,在这个窗口中只有右侧P1位置非零,其余位置均为零。那么这次卷积操作只需要通过这个位置的卷积权重和输入值计算得到。P1位置对应到卷积核中的位置就是(1,0)。我们把这个(1,0)放入GetOffset()结果中。
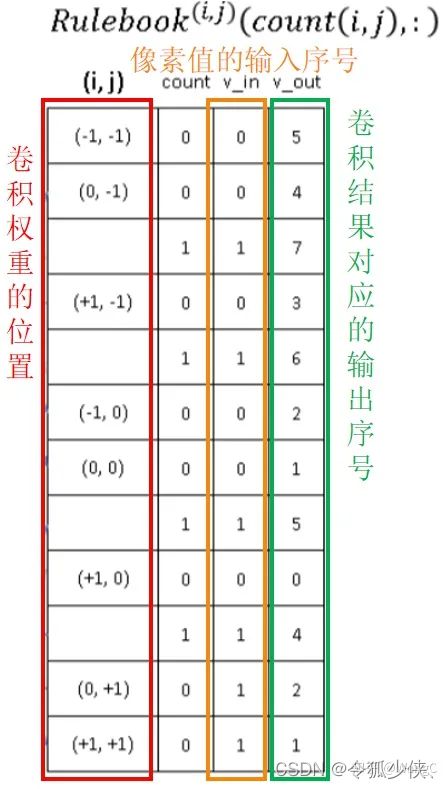
- GetOffset()就是用于找出output中某位置需要用卷积核中的那个weight来计算
构建 Rulebook
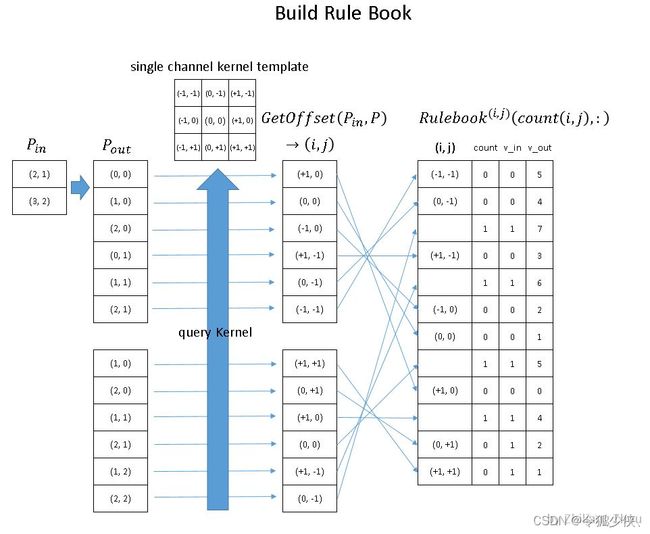
rulebook的每一行都是一个 atomic operation,rulebook的第一列是一个索引,第二列是一个计数器count, v_in和 v_ out 分别是atomic operation的 input hash table 的 index和 output hash tabel的index。(没错,到现在为止,依然是index,而没有用到真实的数据。)
稀疏卷积过程是:

红色箭头处理rulebook中第一个 atomic operation。从rulebook中,我们知道这个atomic operation 有来自 input index (v_in) =0 位置(2,1)的 P1 的输入,和 output index (v_out) =5 位置 (2,1)的输出。
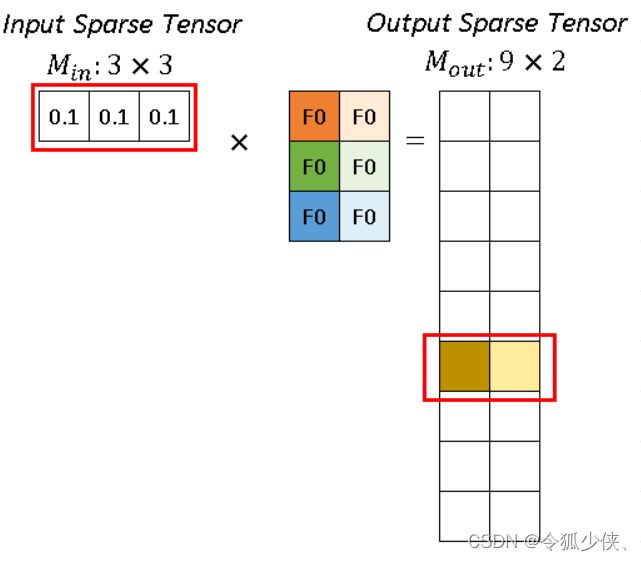
对于p1 代表的 (0.1, 0.1, 0.1),分别跟深色和浅色两个kernel进行卷积运算,得到深黄色和浅黄色两个channel的输出。
传统卷积通过img2col实现,稀疏卷积通过Rulebook来实现。 本质上来说就是一个表。先通过建立输入、输出的哈希表,分别将输入、输出的张量坐标映射到序号。再将输入、输出的哈希表中的序号建立起联系,这样就可以基本实现稀疏卷积,因此这也是稀疏卷积实现的关键。spconv库代码中建立rulebook这一步会调用Python函数get_indice_pairs,该函数进一步调用spconv共享模块中的函数getIndicePairs来一步步完成。
参考:
- https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215
- https://zhuanlan.zhihu.com/p/383299678
- https://zhuanlan.zhihu.com/p/382365889
- 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks