迁移学习与Fine-tuning微调
理论基础
深度学习确实需要大量数据训练;
但可以站在巨人的肩膀——预训练模型;
迁移学习:借助预训练模型进行特征提取,泛化到我们自己的数据集上。
迁移学习的理论基础
卷积神经网络底层提取的是一些底层的特征如边缘、转角、颜色,中层提取比较高级的特征如形状、条纹、斑点,越到高层提取的高维特征越来越复杂,即我们提取到不同数据集的底层的特征都是普适、通用的。并且卷积层之间有脆弱的耦合关系,如果在某一层之前把网络结构冻住,紧跟着的那一层就学不太好。
操作
比如分类问题,预训练模型中最后一层FC-1000有1000个神经元,我们可以改成自己分类个数比如C类个神经元,然后把前面所有层的结构和权重参数都冻结住(不参与训练,即不会反向传播),只在自己数据集上训练新加的FC-C层,这个层随机初始化。
当我们自己数据集比较大时,可以少冻结几层,多往前训练几层但是一般卷积层不动。
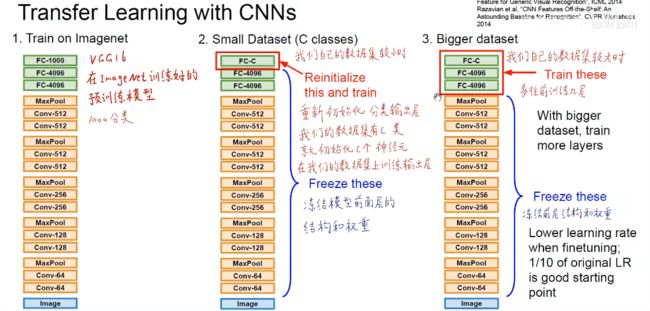
总结的来说,如果拿ImageNet做预训练模型,归纳如下所示
| 类似ImageNet数据集 | 非常不类似 | |
|---|---|---|
| 自己的数据集小 | 改动线性分类输出层(新的全连接层随机初始化) | 不要全连接层甚至部分卷积层,重新提取自己数据集上的高维特征 |
| 自己的数据集大 | 少冻结几层卷积层,多往前训练几层 | 往前训练更多层(甚至不冻结,进行retrain重新训练,初始化还是用预训练模型参数) |
代码
只微调预训练模型最后的一层全连接分类层(修改输入输出的类别数)
model = models.resnet18(pretrained=True) # 载入预训练模型
# 修改全连接层,使得全连接层的输出与当前数据集类别数对应
# 新建的层默认 requires_grad=True
model.fc = nn.Linear(model.fc.in_features, len(class_names))
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.SGD(model.fc.parameters(), lr=0.001, momentum=0.9)
# 微调训练所有层
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
把整个backbone或预训练模型的某一部分结构和参数替换到自己的网络上
更换backbone(以Faster RCNN为例)
#以下是替换骨干网的示例
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 先加载一个预训练模型的特征
# only the features:其实就是不包含最后的classifier的两层
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# 或者自己选取backbone中feature模块结束的节点,即选取合适的特征输出维度,其中feature模块的索引通过打印backbone得到
backbone=create_feature_extractor(backbone,return_nodes={"features.42":"0"})
# 需要知道backbone的输出通道数,这样才能在替换时保证通道数的一致性
'''
可以通过传入tensor来获取输出通道
out=backbone(torch.rand(1,3,224,224))
print(out["0"].shape)
'''
backbone.out_channels = 1280
# 设置RPN的anchor生成器,下面的anchor_generator可以在每个空间位置生成5x3的anchors,即5个不同尺寸×3个不同的比例
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 定义roipool模块
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# 将以上模块集成到FasterRCNN中
model = FasterRCNN(backbone,
num_classes=4,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
重写预训练网络的中间层结构,再加载预训练模型参数(最重要)
Pytorch 加载部分预训练模型并冻结某些层
多GPU并行训练时层名即key值多一个’module’
Pytorch修改预训练模型的方法汇总
- 导入预训练模型参数
torch.save(model, 'net.pth') # 保存整个神经网络的模型结构以及参数
pretrained_model = torch.load('net.pth') # 加载预训练网络的模型结构及参数
pretrained_dict = pretrained_model.state_dict()
torch.save(model.state_dict(), 'net_params.pth') # 只保存模型参数
pretrained_dict = torch.load('net_params.pth') # key是layer名称, value是对应的tensor值,cpu加载方式ckpt = torch.load(model_file, map_location='cpu')
- 获取预训练模型的结构和参数信息
layer_name = list(pretrained_dict.keys()) # 获取预训练模型各层的名称,并转为list
print(pretrained_dict[layer_name[2]) # 查看第2个层的参数值
# 删除预训练模型跟当前模型层名称相同,层结构却不同的元素;假如这里有两个'fc.weight'、'fc.bias'
pretrained_dict.pop('fc.weight')
pretrained_dict.pop('fc.bias')
- 创建自己的模型对象
model = MyNet() # 初始化一个自己的网络模型结构,这个结构一般是在预训练模型结构的基础上重写部分中间层
model_dict = model.state_dict() # 自己模型的所有参数,网络层名对应层的参数
print(model) # 打印模型结构
print(list(model.parameters())) # 打印模型加载参数前的可训练即可导参数
- 加载预训练模型的部分参数
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 将pretrained_dict里不属于model_dict的键剔除掉
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
model.load_state_dict(model_dict)
print(list(model_conv.parameters())) # 打印加载预训练模型参数后的可训练参数值,没有对应的网络层名称
- 冻结部分层
# 将要冻结层参数的requires_grad属性设置为False
for name, value in model.named_parameters():
if (name != 'fc.weight') and (name != 'fc.bias'):
value.requires_grad = False
# filter 函数将模型中属性 requires_grad = True 的参数选出来
params_grad = filter(lambda p: p.requires_grad, model.parameters())
model = model.to(device)
optimizer = optim.SGD(params_grad, lr=0.001, momentum=0.9)
快速去除预训练模型本身的网络层并添加新的层
#先将模型的网络层列表化,每一层对应列表一个元素,bottleneck对应一个序列层
net_structure = list(model.children())
print(net_structure)
#去除最后两层得到新的网络
resnet_modified = nn.Sequential(*net_structure[:-2])
#去除后两层后构建新网络
class Net(nn.Module):
def __init__(self , model):
super(Net, self).__init__()
#去掉model的后两层
self.resnet_layer = nn.Sequential(*list(model.children())[:-2])
self.transion_layer = nn.ConvTranspose2d(2048, 2048, kernel_size=14, stride=3)
self.pool_layer = nn.MaxPool2d(32)
self.Linear_layer = nn.Linear(2048, 8)
def forward(self, x):
x = self.resnet_layer(x)
x = self.transion_layer(x)
x = self.pool_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
训练代码模板
'''训练配置'''
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 学习率指数下降策略,每 4 个 epoch, 降为原来的 0.1
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练轮次 Epoch
EPOCHS = 20
'''train'''
# 遍历每个 EPOCH
for epoch in tqdm(range(EPOCHS)):
model.train()
# 遍历每个 batch
for images, labels in train_loader: # 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''test'''
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in tqdm(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
total += labels.size(0)
correct += (preds == labels).sum()
print('测试集上的准确率为 {:.3f} %'.format(100 * correct / total))
不足
但是fine-tuning不是万能的,
经典的预训练模型(可以做backbone)
经典的卷积神经网络,可以用这些最优秀的预训练模型当backbone来做上游任务特征提取,从而来fine-tuning做我们自己的各种下游任务,如目标检测、语义分割等。
| ImageNet图像分类竞赛历年冠军 | … |
|---|---|
| AlexNet | 2012冠军 Hinton团队 多伦多大学 |
| VGG | 2014亚军 VGG16和VGG19 牛津大学 |
| GoogleNet | 2014冠军 Inception模块 谷歌 |
| ResNet | 2015冠军 残差模块 何恺明团队 微软亚洲研究院 |
| ---- | ---- |
| Also | … |
| SENet | 2017冠军 SE模块 Momenta+牛津 胡杰团队 |
| NiN(Network in Network) | 网中网 1×1卷积 global average pooling |
| Wide ResNet | 增加残差块中军机和数量(宽度) |
| ResNetXT | ResNet + Inception |
| DenseNet | 2017CVPR最佳论文 Dense模块 我的附庸的附庸,也是我的附庸 |
| FractalNet | 分形网络 |
| MobileNets | Group卷积核Depthwise Seperable卷积 |
| NASNet | 2018 神经架构搜索 强化学习 谷歌大脑 |