机器学习之綫性回归实战:單因子和多因子房价预测
文章目录
- 什麼是機器學習
- 機器學習簡介
-
-
- 统计机器学习三个要素:
- 基于学习方法的分类
- 基于学习方式的分类
- 基于数据形式的分类
- 基于学习目标的分类
-
- 實戰
-
- 單因子綫性回歸
- 多因子綫性回歸之房屋预测问题
- 總結
什麼是機器學習
機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。專門研究電腦怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。它是人工智慧的核心,是使電腦具有智能的根本途徑。它的應用已遍及人工智慧的各個分支,如專家系統、自動推理、自然語言理解、模式識別、電腦視覺、智能機器人等領域。其中尤其典型的是專家系統中的知識獲取瓶頸問題,人們一直在努力試圖採用機器學習的方法加以剋服。
機器學習簡介
统计机器学习三个要素:
模型(model):模型在未进行训练前,其可能的参数是多个甚至无穷的,故可能的模型也是多个甚至无穷的,这些模型构成的集合就是假设空间。
策略(strategy):即从假设空间中挑选出参数最优的模型的准则。模型的分类或预测结果与实际情况的误差(损失函数)越小,模型就越好。那么策略就是误差最小。
算法(algorithm):即从假设空间中挑选模型的方法(等同于求解最佳的模型参数)。机器学习的参数求解通常都会转化为最优化问题,故学习算法通常是最优化算法,例如最速梯度下降法、牛顿法以及拟牛顿法等。
基于学习方法的分类
- 归纳学习:
符号归纳学习:典型的符号归纳学习有示例学习、决策树学习。
函数归纳学习(发现学习):典型的函数归纳学习有神经网络学习、示例学习、发现学习、统计学习。 - 演绎学习
- 类比学习: 典型的类比学习有案例(范例)学习。
- 分析学习: 典型的分析学习有解释学习、宏操作学习。
基于学习方式的分类
- 监督学习:(有导师学习)
输入数据中有导师信号,以概率函数、代数函数或人工神经网络为基函数模型,采用迭代计算方法,学习结果为函数。
在已有的数据集中,训练数据包括正确结果,知道输入数据与输出结果的关系,并可以根据这种关系建立一个关系模型,在获得新数据后,就可以根据这种关系输出对应结果。 - 无监督学习:(无导师学习)
输入数据中无导师信号,采用聚类方法,学习结果为类别。典型的无导师学习有发现学习、聚类、竞争学习等。
训练数据不包括正确结果,让计算机自己去数据中寻找规律。 - 半监督学习:训练数据包含少量结果,可以理解为介于监督学习和无监督学习之间。
- 强化学习:(增强学习)
以环境反馈(奖/惩信号)作为输入,以统计和动态规划技术为指导的一种学习方法。
根据每次结果收获的奖惩进行学习,实现优化。就比如让机器人去做一件事,做得好就加5分,做的差就减5分,然后按照第一种方式做事获得的分比第二种方式高,那么机器人就知道第一种方式更好了。按照这种奖惩方式,程序就可以逐步寻找获得高分的方法了。
基于数据形式的分类
- 结构化学习: 以结构化数据为输入,以数值计算或符号推演为方法。典型的结构化学习有神经网络学习、统计学习、决策树学习、规则学习。
- 非结构化学习: 以非结构化数据为输入,典型的非结构化学习有类比学习案例学习、解释学习、文本挖掘、图像挖掘、Web挖掘等。
基于学习目标的分类
- 概念学习: 学习的目标和结果为概念,或者说是为了获得概念的学习。典型的概念学习主要有示例学习。
- 规则学习: 学习的目标和结果为规则,或者为了获得规则的学习。典型规则学习主要有决策树学习。
- 函数学习: 学习的目标和结果为函数,或者说是为了获得函数的学习。典型函数学习主要有神经网络学习。
- 类别学习: 学习的目标和结果为对象类,或者说是为了获得类别的学习。典型类别学习主要有聚类分析。
- 贝叶斯网络学习: 学习的目标和结果是贝叶斯网络,或者说是为了获得贝叶斯网络的一种学习。其又可分为结构学习和多数学习。
實戰
單因子綫性回歸
基于generated_data.csv数据
# load the data
import pandas as pd
data = pd.read_csv('generated_data.csv')
data.head()
print(type(data),data.shape)


# data賦值
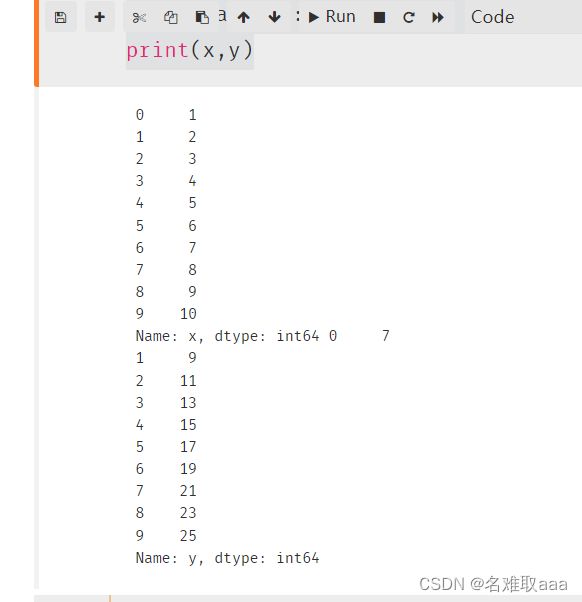
x = data.loc[:,'x']
y = data.loc[:,'y']
print(x,y)
# visualize the data
from matplotlib import pyplot as plt
plt.figure()
plt.scatter(x,y) #散點圖
plt.show()

#set up a linear regression model
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
import numpy as np
x=np.array(x)
x=x.reshape(-1,1) #改爲二維的
y=np.array(y)
y=y.reshape(-1,1)
print(x.shape) # 查看維度

訓練模型

直綫方程: y=ax+b
a=lr_model.coef_ #得到係數
b=lr_model.intercept_
print(a,b)

評估模型
y_predict = lr_model.predict(x)
from sklearn.metrics import mean_squared_error,r2_score
MSE = mean_squared_error(y,y_predict)
R2 = r2_score(y,y_predict)
print(MSE,R2)

MSE好像是越接近0越小越好因爲數據多也很難直觀看出好壞,R2分數越接近1越好
plt.figure()
plt.plot(y,y_predict)
plt.show()
可視化

多因子綫性回歸之房屋预测问题
基于usa_housing_price.csv数据,以人均收入、房屋年龄、房间数量、区域人口、房屋面积作为输入变量,来预测房屋价格
#load the data
data = pd.read_csv('usa_housing_price.csv')
data.head() #预览数据。数据很多,预览数据只是预览前五项。

# %matplotlib inline #老版本的才要這個新版本寫這個會報錯,後面的也不寫這個了
fig = plt.figure(figsize=(15,12)) #定義畫布大小,覺得效果還行也可以不定義畫布
fig1 =plt.subplot(231) #231是指两行三列的第一个图,下面的232是指两行三列的第二个图,依次类推
plt.scatter(data.loc[:,'Avg. Area Income'],data.loc[:,'Price']) #获取数据,画出一个散点图
plt.title('Price VS Income') #散点图的名称
fig2 =plt.subplot(232)
plt.scatter(data.loc[:,'Avg. Area House Age'],data.loc[:,'Price'])
plt.title('Price VS House Age')
fig3 =plt.subplot(233)
plt.scatter(data.loc[:,'Avg. Area Number of Rooms'],data.loc[:,'Price'])
plt.title('Price VS Number of Rooms')
fig4 =plt.subplot(234)
plt.scatter(data.loc[:,'Area Population'],data.loc[:,'Price'])
plt.title('Price VS Area Population')
fig5 =plt.subplot(235)
plt.scatter(data.loc[:,'size'],data.loc[:,'Price'])
plt.title('Price VS size')
plt.show() #展示散点图

#define X_multi
X_multi = data.drop(['Price'],axis=1) #去掉price所在列
y = data.loc[:,'Price']
X_multi.head()

LR_multi = LinearRegression()#建立模型
LR_multi.fit(X_multi,y) #训练模型
這樣就訓練好模型了

#模型预测
y_predict_multi = LR_multi.predict(X_multi)
print(y_predict_multi)

模型评估
mean_squared_error_multi = mean_squared_error(y,y_predict_multi)
r2_score_multi = r2_score(y,y_predict_multi)
print(mean_squared_error_multi,r2_score_multi)

可以發現R2分數的已經非常接近與1了,這就比下面單獨用一個因子的模型好
x_Income = data.loc[:,'Avg. Area Income']
x_Income=np.array(x_Income)
x_Income=x_Income.reshape(-1,1)
LR_Income = LinearRegression()#建立模型
LR_Income.fit(x_Income,y) #训练模型
y_predict_Income = LR_Income.predict(x_Income)
mean_squared_error_Income = mean_squared_error(y,y_predict_Income)
r2_score_Income = r2_score(y,y_predict_Income)
print(mean_squared_error_Income,r2_score_Income)
寫一個只有Avg. Area Income一個因子對price的影響

這裏可以看出MSE分數也是遠大於多因子的模型,R2分數只有0.4,綜合看出單因子比上面多因子的模型差的多
#图形评估
fig6 = plt.figure(figsize=(9,6))
plt.scatter(y,y_predict_multi)
因爲多維度難以畫圖所以使用y和預測y對比,若是直綫且越接近45°則越好

可以看出这里y值和y的预测值接近一条45度的直线

相比單因子的這個圖還是好很多
總結
附上數據集和源碼給需要的小夥伴
鏈接:https://github.com/fbozhang/python/tree/master/jupyter