EdiBERT, a generative model for image editing(一种用于图像编辑的生成模型)
1.EdiBERT, a generative model for image editing(一种用于图像编辑的生成模型)
机构:法国国立路桥学院

2. github地址: https://github.com/EdiBERT4ImageManipulation/EdiBERT
3.介绍和摘要:
计算机视觉的进步正在推动图像处理的极限,生成模型在各种任务中对详细图像进行采样。然而,通常针对每个特定任务开发和训练专门的模型,即使许多图像编辑任务有相似之处。在去噪、修复或图像合成中,人们总是旨在从低质量图像生成逼真的图像。在本文中,我们的目标是朝着统一的图像编辑方法迈出一步。为此,我们提出了 EdiBERT,这是一种在由矢量量化自动编码器构建的离散潜在空间中训练的双向变换器。我们认为这种双向模型适用于图像处理,因为任何补丁都可以有条件地重新采样到整个图像。使用这个独特而直接的训练目标,我们表明生成的模型在各种任务上与最先进的性能相匹配:图像去噪、图像补全和图像合成

第一列是输入,第二列和第三列是来自EdiBERT的不同样本,显示了真实感和一致性
EdiBERT 尝试通过双向注意模式恢复原始标记。通过这种独特而简单的训练方案,所获得的生成模型现在可以用于许多不同的图像处理任务,例如去噪、修复或基于涂鸦的编辑,如图 1 所示。
(1)我们分析了VQGAN潜在表示,并说明了它们的空间特性,以激励使用双向transformer进行图像编辑。
(2)我们展示了如何从单个模型中推导出两种不同的算法: 一种用于图像去噪,其中编辑的位置未知,第二个用于修复或图像合成,其中遮罩指定要编辑的区域。
(3)最后,我们证明了使用这种通用且简单的训练算法可以使我们在各种任务上获得有竞争力的结果。
this framework consists of three main steps(训练的三个步骤)
1.训练一个VQGAN,一组具有感知和对抗性损失的编码器/解码器/码本 (E,D,Z)。
2.训练自回归变换器以最大化编码序列的对数似然。
3.在推理时,使用转换器对序列进行采样并使用解码器 D 对其进行解码。
4. Motivating EdiBERT for image editing.
(1)Notations 符号
(E,D,Z) 分别为 VQVAE 和 VQGAN [12, 34] 中定义的编码器、解码器和码本。


其中 QZ 指的是使用码本 Z 的量化操作。回想一下,在量化步骤之后,我们得到一个序列 s ∈ Zl

(二)自回归模型学习序列。

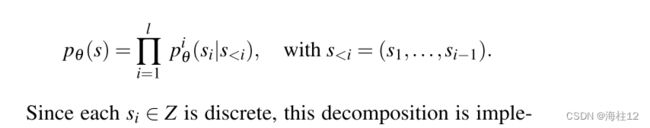
对于给定的离散标记序列 s=(s1, . . . , sl) ∈DS,使用以下公式给出序列 s 的似然性 pθ(s)
由于每个 si ∈ Z 都是离散的,因此这种分解是通过一个从左到右的因果注意掩码和一个 softmax 输出层实现的。最后,给定一组指定的参数 Θ 。
给定一组指定的参数 Θ,自回归模型的目标是:

(三)EdiBERT 的独特训练目标
定义 EdiBERT 的训练目标。对于任何序列 s = (s1, ..., sL),函数 φ 随机选择 k 个索引 {φ1, ...,φk} 的子集,其中 φk < L。在每个选定位置,对记号 sφi 。与 [10] 类似,我们以概率 p 赋予随机标记,或以概率 1− p 保留相同标记。因此,扰动的令牌 ![]() φi 变为:
φi 变为:

其中U(Z)指的是标记空间Z上的均匀分布。请注意,我们在目前的表述中不使用任何掩码标记。采样函数 φ是用二维屏蔽策略定义的,训练位置是通过在从编码器中提取的二维补丁中随机抽取二维矩形来选择。现在,让我们把![]() 和
和 s分别称为扰动的序列和数据集
s分别称为扰动的序列和数据集

培训包括以下目标

(四) On the locality of Vector Quantization encoding 关于矢量量化编码的局域性

问题回答一:

问题二:

如图四:

因此,VQGANs潜空间和图像空间之间的这种空间对应关系对于局部图像编辑任务很有用,即,仅需要修改像素的子集而不更改其他像素
5.使用edibert进行图像编辑

(1)图像去噪

效果:

(2)图像修复

效果:
(3)图像合成
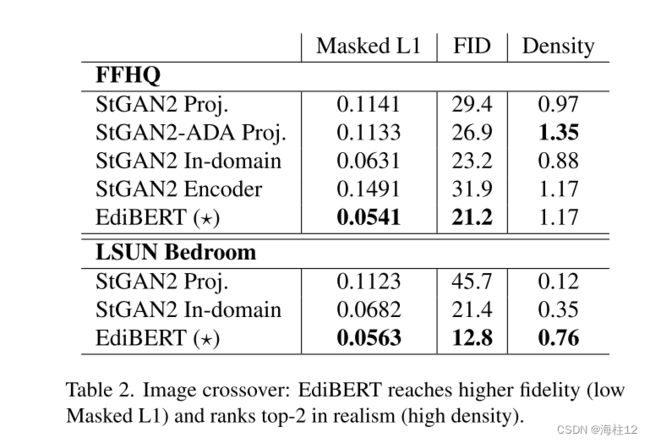
性能
6 Conclusion
展示了使用相同的预训练模型执行多个编辑任务的可能性。所提出的框架很简单,旨在朝着能够对图像执行任何可能的操作任务的统一模型迈出一步。