YOLOv3学习笔记
1.论文出处
论文:YOLOv3: An Incremental Improvement
论文地址:https://arxiv.fenshishang.com/abs/1804.02767
2.网络结构

CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用。
Concat:张量拼接,会扩充两个张量的维度,例如26x26x256和26x26x512两个张量拼接,结果是26x26x768。Concat和cfg文件中的route功能一样。

Backbone中卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2x1)+(1+2x2)+(1+2x8)+(1+2x8)+(1+2x4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
3. YOLOv3的设计思想
YOLOv3算法的基本思想可以分成两部分:

1.按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
2.使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
4.产生候选区域
4.1生成锚框
实现思想:
Step1:将原图划分成mxn个小方块区域。
Step2:在每个小方块的中心生成一系列的锚框。

将原始图片划分成m×n个区域,如下图所示,原始图片高度H=640, 宽W=480,如果我们选择小块区域的尺寸为32×32。则m和n分别为m=640/32=20,n=480/32=15。将原始图像分成20行15列的小方块区域。


以每个小方块为中心,生成一些列锚框。上图左代表在图片中第10行第4列小方块位置生成的3个锚框。
锚框总数:m x n x num=20x15x3=900个
4.2 生成预测框
预测框要在锚框的基础上做一些小的调整。

由于sigmoid的值域在0-1之间,所以计算出来的预测狂的中心点一直会在小方块区域的内部。
4.3 标注候选区域

4.3.1 标注Objectness标签
找出真实框中心点所在的小方框区域,从这个区域的3个锚框中选出跟它形状最匹配的锚框。
当锚框与真实框的IoU最大时,将Objectness标注为1,其余的标注为0。
问题:如果某个锚框跟真实框IoU比较大,但不是最大的那个。将其标注为负样本是否合适?
解决方案:如果预测狂跟某个真实框的IoU大于阈值,但锚框并不是最匹配的那个,就将objectness设置为-1,不计算损失函数。阈值超参数:ignore_thresh=0.7。
4.3.2 标注锚框-Location标签
问题:当[tx,ty,tw,th]取值为多少时,预测狂跟真实框重合?
4.3.3 标注锚框-Classification标签
当objectness=1时,需要确定包含的物体所属的类别classification。
YOLOv3模型对每个类别独立计算概率,标注的时候,将类别标签表示为one-hot向量。比如:一个5个分类,真实框包含的物体属于第二类,则classification标签为[0,0,1,0,0]。
标注过程:

所以每个锚框需要的标注数据个数为:
Location(4)+objectness(1)+classification(5)
m*n个方块区域,每个区域有k个锚框,则标注数据的维度是:[k(5+C)] x m x n
伪代码思路:
Step1:对一个batchsize的图片做循环,找出真实框中心所在的区域(i,j)
Step2:对第i行第j列小方块区域内的所有锚框做循环,找出与真实框形状最匹配的锚框,将IoU最大的锚框的objectness设置为1,类别设置为对应真实框类别。
Step3:对Objectness=1的标签,求其Location标签。
5.特征提取

6.将特征图与候选区域关联起来
原图尺寸[1,3,M,N],以3232大小划分小方块。m=M/32 n=N/32
原图一共可以被划分为mn个小方块区域,每个小方块有3个锚框
每个锚框有Location(4),Objectness(1),classification(class=7)个标注数据。
所有锚框标注数据的维度是[1,3*(4+1+7),m,n]=[1,36,m,n]
特征图C0输出通道数1024,步幅stride=32,尺寸为[1,1024,m,n]
问题:怎么将特征图C0与标注数据关联起来?
通过head调整特征图的输出通道数


6.1计算预测框是否包含物体的概率
P0[t,4,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框的objectness对应,P0[t,4+12,i,j]与第2个预测框的objectness对应,…,则可以使用pred_objectness = reshaped_p0[:, :, 4, :, :]将objectness相关的预测取出,并使用pred_objectness_probability = F.sigmoid(pred_objectness)算输出概率。
6.2计算预测框位置坐标
P0[t,0:4,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框的位置对应,P0[t,12:16,i,j]与第2个预测框的位置对应,依此类推,则使用pred_location = reshaped_p0[:, :, 0:4, :, :]可以从P0中取出跟预测框位置相关的预测值。
取出位置的相关的值[tx,ty,tw,th],还需要计算出预测框坐标[x1,y1,x2,y2]
6.3计算物体属于每个类别概率
P0[t,5:12,i,j]与输入的第t张图片上小方块区域(i,j)第1个预测框包含物体的类别对应,P0[t,17:24,i,j]与第2个预测框的类别对应,依此类推,则使用下面的pred_classification = reshaped_p0[:, :,5:5+NUM_CLASSES, :, :] pred_classification_probability = F.sigmoid(pred_classification)可以从P0中取出那些跟预测框类别相关的预测值。

7.建立损失函数
损失函数:预测框的位置损失+预测框预测的类别损失+预测框置信度损失

8.多尺度检测
8.1 FPN特征金字塔
FPN主要解决的问题是目标检测在处理多尺度变化问题的不足,现在很多网络都使用了利用单个高层特征,但是这样做有一个明显的缺陷,即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失,为了处理这种物体大小差异十分明显的检测问题,经典的方法是利用图像金字塔的方式进行多尺度变化增强,但是这样会带来极大的计算量。所以这篇论文提出了特征金字塔的网络结构,能在增加极少计算量的情况下,处理好物体检测中的多尺度变化问题。
众所周知,识别尺寸差异很大的物体是计算机视觉所面临的基本挑战之一。这篇论文总结出针对这个问题的几种解决办法:

(a)通过图像金字塔来构建不同尺度的特征金字塔。
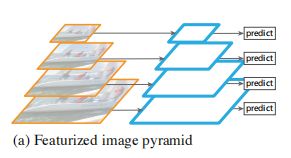
该方法的优点:
1.对每一种尺度的图像进行特征提取,能够产生多尺度的特征表示,并且所有等级的特征图都具有较强的语义信息,甚至包括一些高分辨率的特征图。
注:语义一般指的是图像每个像素点的类别归属,语义信息可以理解为与类别划分有关的信息。
该方法的缺点:
1.推理时间大幅度增加
2.由于内存占用较大,用图像金字塔的形式训练一个端到端的深度神经网络变得不可行。
3.如果只在测试阶段使用图像金字塔,那么会造成一个问题:由于训练时,网络只是针对于某一个特点的分辨率进行训练,推理时运用图像特征金字塔,可能会在训练与推理时产生“矛盾”。
(b)通过图像金字塔来构建不同尺度的特征金字塔。

利用单个高层特征图进行预测。
©金字塔型特征层级

比如SSD one-stage目标检测模型就是再次利用不同多尺度的特征图。

SSD没有解决以下问题:
浅层特征图语义信息不够和深层特征图的分辨率也不高。
(d)特征金字塔
为了解决以上三种结构的不足之处,这篇论文提出了FPN,使每一层不同尺度的特征图都具有较强的语义信息。这种网络结构,能够在增加较少计算量的前提下融合低分辨率语义信息较强的特征图和高分辨率语义信息较弱但空间信息丰富的特征图。
其实在这篇论文之前,也有人提到得出一张具有高分辨率又具有较强语义信息的特征图进行预测,但是FPN的独到之处在于,它是以特征金字塔为基础结构上,对每一层级的特征图分别进行预测。

9.预测
预测流程:
Step1:输入图片预处理,减去均值,除以方差,尺寸缩放到608*608
Step2:提取特征P0,P1,P2,计算3个层级的预测框坐标和得分
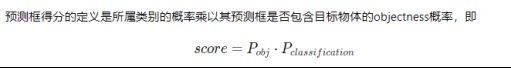
Step3:使用非极大值抑制算法(NMS)消除重叠较大的预测框。

目标检测模型会产生很多预测框,其中有大量的框预测的是相同目标,而只需要留下一个最合适的框。
9.1 NMS非极大值抑制
原理:对于预测框的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空。

NMS算法的具体流程:
输入 boxes,scores, iou_threshold
step-1:将所有检出的output_bbox按cls score划分(如pascal voc分20个类);
step-2:在每个类集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k;
step-3:对所有的list_k进行遍历,如有20个类,就得对这20个list都进行遍历。从list_k中top1 cls score开始,计算该bbox_x与list中其他bbox_y的IoU,若IoU大于阈值T,则剔除该bbox_y,最终保留bbox_x,从list_k中取出,保存在output_k中最后作为结果输出;
step-4:继续选择list_k中top1 cls score,重复step-3中的迭代操作,直至list_k中所有bbox都完成筛选;
step-5:对每个集合的list_k,重复step-3、4中的迭代操作,直至所有list_k都完成筛选;

9.2 Soft-NMS
动机:当俩个目标框接近时,分数更低的框会因为与之重叠面积过大而被删掉。

Soft NMS算法的具体流程:

f权重函数的形式:

Soft NMS的优点:
1.只需要对传统的NMS算法进行简单的改动而不需要增加其他的参数,该Soft-NMS算法在标准数据集PASCAL VOC2007(较R-FCN和Faster-RCNN提升1.7%)和MS-COCO(较R-FCN提升1.3%,较Faster-RCNN提升1.1%)上均有提升。
2.Soft NMS和NMS算法复杂度相同,使用高效
3.Soft-NMS不需要额外的训练,并易于实现,它可以轻松的被集成到任何物体检测流程中。
10.参考
https://aistudio.baidu.com/aistudio/projectdetail/2995444