CNN与Transformer的结合-BoTNet
简单学习BoTNet
1.简单介绍
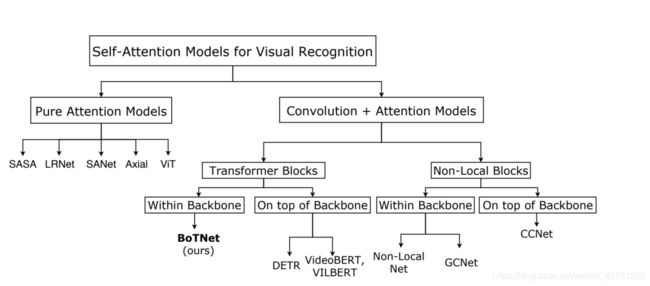
如今transformer热度较高,越来越多的人都来研究transformer,并将其用于CV领域,下图(出自BoTNet论文)就介绍了当前self-Attention在CV领域的应用,而本篇文章的主角BoTNet就是利用CNN+transformer的方式提出一种Bottleneck Transformer来代替ResNet Bottleneck。
2.大体结构
如图所示总体结构比较简单,就是在ResNet-50的结构基础上将C5的三个Bottleneck替换为带MHSA的Bottleneck。
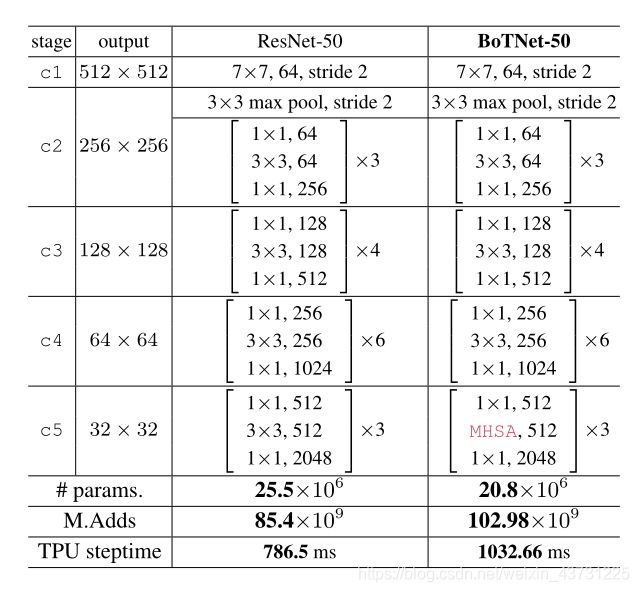
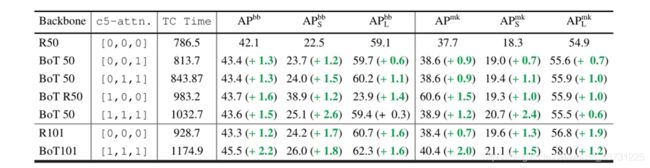
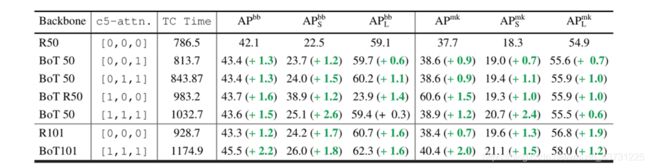
这里C5的Bottleneck也不一定3个全用MHSA,为此文章也做了对比实验

实验结果
带MHSA的Bottleneck如下图所示
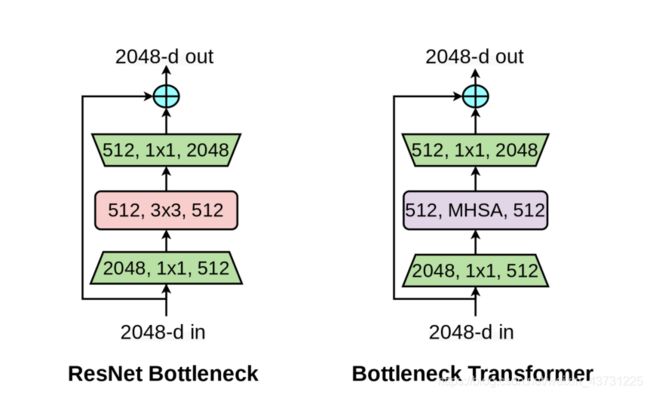
接下来我们看看MHSA是怎么具体实现的
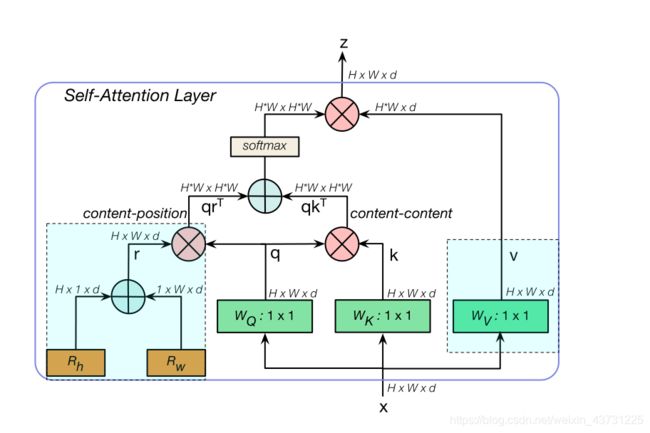
结构大体与transformer一致,不过值得注意的是这个content -position与transformer的位置嵌入还是有区别的,有兴趣的同学可以去单独了解下content-position。
MHSA的代码实现如下
class MHSA(nn.Module):
def __init__(self, n_dims, width, height):
super(MHSA, self).__init__()
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
# nn.Parameter 含义是将一个固定不可训练的tensor转换成可以训练的类型parameter
self.rel_h = nn.Parameter(torch.randn([1, n_dims, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, n_dims, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, C, -1)
k = self.key(x).view(n_batch, C, -1)
v = self.value(x).view(n_batch, C, -1)
# 对存储在两个批bach1和batch内的矩阵进行批矩阵乘操作。batch1和2都包含相同数量矩阵的三维张量
content_content = torch.bmm(q.permute(0, 2, 1), k)
content_position = (self.rel_h + self.rel_w).view(1, C, -1).permute(0, 2, 1)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.bmm(v, attention.permute(0, 2, 1))
out = out.view(n_batch, C, width, height)
return out
这个代码快也还是比较容易理解的
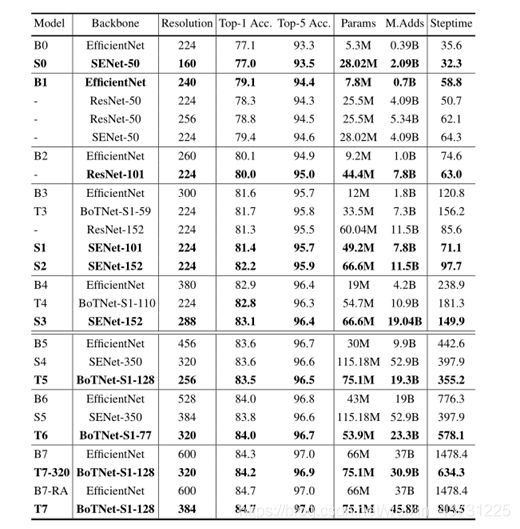
3.实验结果
单独使用的BoTNet在目标检测中取得了不错的结果
但在图像分类中效果取并没有很强,为此文章又提出了BoTNet-S1结构哦,如下图
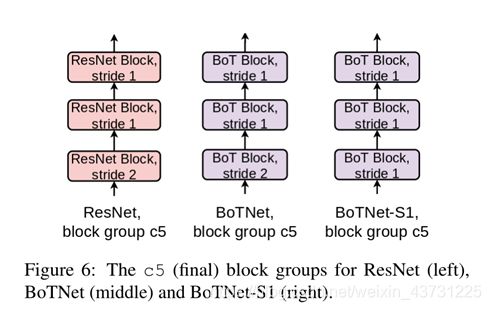
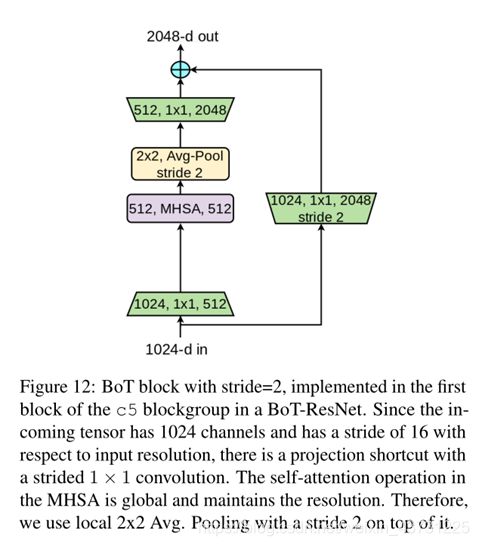
这里将stride由2改为了1,改为1后其实就是上图的平均池化还有卷积的stride改为了1,然而却取得了非常不错得效果

另外文章还有做了一些其他的对比实验,就放在下面了
其中BoTNet的卷积块添加了SE(注意力机制)模块

(上述有发现任何错误和问题可随时联系我)