ORB-SLAM2代码详解02: 特征点提取器ORBextractor
pdf版本笔记的下载地址: ORB-SLAM2代码详解02_特征点提取器ORBextractor,排版更美观一点,这个网站的默认排版太丑了(访问密码:3834)
ORB-SLAM2代码详解02: 特征点提取器ORBextractor
- 各成员函数/变量
-
- 构造函数: `ORBextractor()`
- 构建图像金字塔: `ComputePyramid()`
- 提取特征点并进行筛选: `ComputeKeyPointsOctTree()`
-
- 八叉树筛选特征点: `DistributeOctTree()`
- 计算特征点方向`computeOrientation()`
- 计算特征点描述子`computeOrbDescriptor()`
- `ORBextractor`类的用途
-
- `ORBextractor`类提取特征点的主函数`void operator()()`
- `ORBextractor`类与其它类间的关系
可以看看我录制的视频5小时让你假装大概看懂ORB-SLAM2源码
各成员函数/变量
构造函数: ORBextractor()
FAST特征点和ORB描述子本身不具有尺度信息,ORBextractor通过构建图像金字塔来得到特征点尺度信息.将输入图片逐级缩放得到图像金字塔,金字塔层级越高,图片分辨率越低,ORB特征点越大.

构造函数ORBextractor(int nfeatures, float scaleFactor, int nlevels, int iniThFAST, int minThFAST)的流程:

-
初始化图像金字塔相关变量:
下面成员变量从配置文件
TUM1.yaml中读入:成员变量 访问控制 意义 配置文件 TUM1.yaml中变量名值 int nfeaturesprotected所有层级提取到的特征点数之和金字塔层数 ORBextractor.nFeatures1000double scaleFactorprotected图像金字塔相邻层级间的缩放系数 ORBextractor.scaleFactor1.2int nlevelsprotected金字塔层级数 ORBextractor.nLevels8int iniThFASTprotected提取特征点的描述子门槛(高) ORBextractor.iniThFAST20int minThFASTprotected提取特征点的描述子门槛(低) ORBextractor.minThFAST7根据上述变量的值计算出下述成员变量:
成员变量 访问控制 意义 值 std::vectormnFeaturesPerLevel protected金字塔每层级中提取的特征点数
正比于图层边长,总和为nfeatures{61, 73, 87, 105, 126, 151, 181, 216}std::vectormvScaleFactor protected各层级的缩放系数 {1, 1.2, 1.44, 1.728, 2.074, 2.488, 2.986, 3.583}std::vectormvInvScaleFactor protected各层级缩放系数的倒数 {1, 0.833, 0.694, 0.579, 0.482, 0.402, 0.335, 0.2791}std::vectormvLevelSigma2 protected各层级缩放系数的平方 {1, 1.44, 2.074, 2.986, 4.300, 6.190, 8.916, 12.838}std::vectormvInvLevelSigma2 protected各层级缩放系数的平方倒数 {1, 0.694, 0.482, 0.335, 0.233, 0.162, 0.112, 0.078} -
初始化用于计算描述子的
pattern变量,pattern是用于计算描述子的256对坐标,其值写死在源码文件ORBextractor.cc里,在构造函数里做类型转换将其转换为const cv::Point*变量.static int bit_pattern_31_[256*4] ={ 8,-3, 9,5/*mean (0), correlation (0)*/, 4,2, 7,-12/*mean (1.12461e-05), correlation (0.0437584)*/, -11,9, -8,2/*mean (3.37382e-05), correlation (0.0617409)*/, 7,-12, 12,-13/*mean (5.62303e-05), correlation (0.0636977)*/, 2,-13, 2,12/*mean (0.000134953), correlation (0.085099)*/, // 共256行... } const Point* pattern0 = (const Point*)bit_pattern_31_; std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern)); -
计算一个半径为
16的圆的近似坐标后面计算的是特征点主方向上的描述子,计算过程中要将特征点周围像素旋转到主方向上,因此计算一个半径为
16的圆的近似坐标,用于后面计算描述子时进行旋转操作.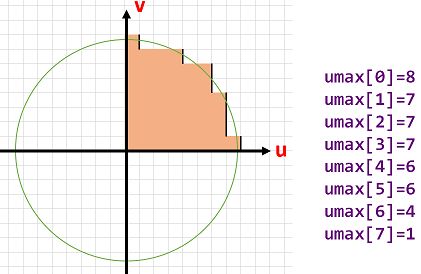
成员变量
std::vector里存储的实际上是逼近圆的第一象限内 1 4 \frac{1}{4} 41圆周上每个umax v坐标对应的u坐标.为保证严格对称性,先计算下45°圆周上点的坐标,再根据对称性补全上45°圆周上点的坐标.int vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1); // 45°射线与圆周交点的纵坐标 int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2); // 45°射线与圆周交点的纵坐标 // 先计算下半45度的umax for (int v = 0; v <= vmax; ++v) { umax[v] = cvRound(sqrt(15 * 15 - v * v)); } // 根据对称性补出上半45度的umax for (int v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v) { while (umax[v0] == umax[v0 + 1]) ++v0; umax[v] = v0; ++v0; }
构建图像金字塔: ComputePyramid()
根据上述变量的值计算出下述成员变量:
| 成员变量 | 访问控制 | 意义 |
|---|---|---|
std::vector |
public |
图像金字塔每层的图像 |
const int EDGE_THRESHOLD |
全局变量 | 为计算描述子和提取特征点补的padding厚度 |
函数void ORBextractor::ComputePyramid(cv::Mat image)逐层计算图像金字塔,对于每层图像进行以下两步:
- 先进行图片缩放,缩放到
mvInvScaleFactor对应尺寸. - 在图像外补一圈厚度为
19的padding(提取FAST特征点需要特征点周围半径为3的圆域,计算ORB描述子需要特征点周围半径为16的圆域).
下图表示图像金字塔每层结构:
- 深灰色为缩放后的原始图像.
- 包含绿色边界在内的矩形用于提取
FAST特征点. - 包含浅灰色边界在内的整个矩形用于计算
ORB描述子.

void ORBextractor::ComputePyramid(cv::Mat image) {
for (int level = 0; level < nlevels; ++level) {
// 计算缩放+补padding后该层图像的尺寸
float scale = mvInvScaleFactor[level];
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
Size wholeSize(sz.width + EDGE_THRESHOLD * 2, sz.height + EDGE_THRESHOLD * 2);
Mat temp(wholeSize, image.type());
// 缩放图像并复制到对应图层并补边
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
if( level != 0 ) {
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, cv::INTER_LINEAR);
copyMakeBorder(mvImagePyramid[level], temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101+BORDER_ISOLATED);
} else {
copyMakeBorder(image, temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
}
}
copyMakeBorder函数实现了复制和padding填充,其参数BORDER_REFLECT_101参数指定对padding进行镜像填充.
提取特征点并进行筛选: ComputeKeyPointsOctTree()

提取特征点最重要的就是力求特征点均匀地分布在图像的所有部分,为实现这一目标,编程实现上使用了两个技巧:
- 分
CELL搜索特征点,若某CELL内特征点响应值普遍较小的话就降低分数线再搜索一遍. - 对得到的所有特征点进行八叉树筛选,若某区域内特征点数目过于密集,则只取其中响应值最大的那个.

CELL搜索的示意图如下,每个CELL的大小约为30✖30,搜索到边上,剩余尺寸不够大的时候,最后一个CELL有多大就用多大的区域.
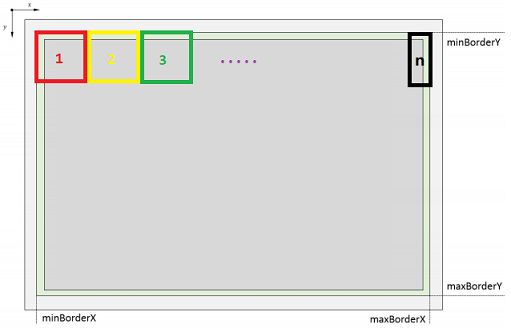
需要注意的是相邻的CELL之间会有6像素的重叠区域,因为提取FAST特征点需要计算特征点周围半径为3的圆周上的像素点信息,实际上产生特征点的区域比传入的搜索区域小3像素.

void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint> >& allKeypoints) {
for (int level = 0; level < nlevels; ++level)
// 计算图像边界
const int minBorderX = EDGE_THRESHOLD-3;
const int minBorderY = minBorderX;
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY);
const int nCols = width/W; // 每一列有多少cell
const int nRows = height/W; // 每一行有多少cell
const int wCell = ceil(width/nCols); // 每个cell的宽度
const int hCell = ceil(height/nRows); // 每个cell的高度
// 存储需要进行平均分配的特征点
vector<cv::KeyPoint> vToDistributeKeys;
// step1. 遍历每行和每列,依次分别用高低阈值搜索FAST特征点
for(int i=0; i<nRows; i++) {
const float iniY = minBorderY + i * hCell;
const float maxY = iniY + hCell + 6;
for(int j=0; j<nCols; j++) {
const float iniX =minBorderX + j * wCell;
const float maxX = iniX + wCell + 6;
vector<cv::KeyPoint> vKeysCell;
// 先用高阈值搜索FAST特征点
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX), vKeysCell, iniThFAST, true);
// 高阈值搜索不到的话,就用低阈值搜索FAST特征点
if(vKeysCell.empty()) {
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX), vKeysCell, minThFAST, true);
}
// 把 vKeysCell 中提取到的特征点全添加到 容器vToDistributeKeys 中
for(KeyPoint point :vKeysCell) {
point.pt.x+=j*wCell;
point.pt.y+=i*hCell;
vToDistributeKeys.push_back(point);
}
}
}
// step2. 对提取到的特征点进行八叉树筛选,见 DistributeOctTree() 函数
keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX, minBorderY, maxBorderY, mnFeaturesPerLevel[level], level);
}
// 计算每个特征点的方向
for (int level = 0; level < nlevels; ++level)
computeOrientation(mvImagePyramid[level], allKeypoints[level], umax);
}
}
八叉树筛选特征点: DistributeOctTree()
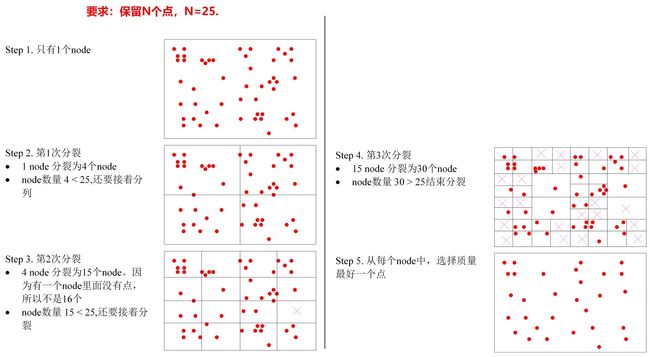
函数DistributeOctTree()进行八叉树筛选(非极大值抑制),不断将存在特征点的图像区域进行4等分,直到分出了足够多的分区,每个分区内只保留响应值最大的特征点.
其代码实现比较琐碎,程序里还定义了一个ExtractorNode类用于进行八叉树分配,知道原理就行,不看代码.
计算特征点方向computeOrientation()
函数computeOrientation()计算每个特征点的方向: 使用特征点周围半径19大小的圆的重心方向作为特征点方向.

static void computeOrientation(const Mat& image, vector<KeyPoint>& keypoints, const vector<int>& umax)
{
for (vector<KeyPoint>::iterator keypoint : keypoints) {
// 调用IC_Angle 函数计算这个特征点的方向
keypoint->angle = IC_Angle(image, keypoint->pt, umax);
}
}
static float IC_Angle(const Mat& image, Point2f pt, const vector<int> & u_max)
{
int m_01 = 0, m_10 = 0; // 重心方向
const uchar* center = &image.at<uchar> (cvRound(pt.y), cvRound(pt.x));
for (int u = -HALF_PATCH_SIZE; u <= HALF_PATCH_SIZE; ++u)
m_10 += u * center[u];
int step = (int)image.step1();
for (int v = 1; v <= HALF_PATCH_SIZE; ++v) {
int v_sum = 0;
int d = u_max[v];
for (int u = -d; u <= d; ++u) {
int val_plus = center[u + v*step], val_minus = center[u - v*step];
v_sum += (val_plus - val_minus);
m_10 += u * (val_plus + val_minus);
}
m_01 += v * v_sum;
}
// 为了加快速度使用了fastAtan2()函数,输出为[0,360)角度,精度为0.3°
return fastAtan2((float)m_01, (float)m_10);
}
计算特征点描述子computeOrbDescriptor()
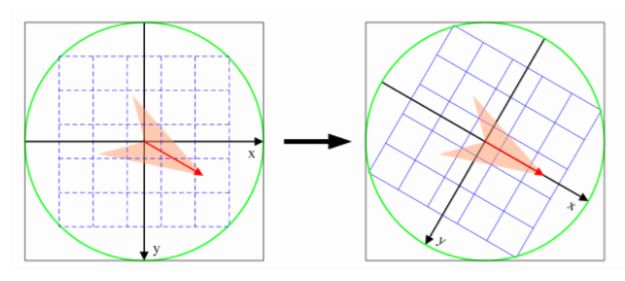
计算BRIEF描述子的核心步骤是在特征点周围半径为16的圆域内选取256对点对,每个点对内比较得到1位,共得到256位的描述子,为保计算的一致性,工程上使用特定设计的点对pattern,在程序里被硬编码为成员变量了.

在computeOrientation()中我们求出了每个特征点的主方向,在计算描述子时,应该将特征点周围像素旋转到主方向上来计算;为了编程方便,实践上对pattern进行旋转.
static void computeOrbDescriptor(const KeyPoint& kpt, const Mat& img, const Point* pattern, uchar* desc) {
float angle = (float)kpt.angle*factorPI;
float a = (float)cos(angle), b = (float)sin(angle);
const uchar* center = &img.at<uchar>(cvRound(kpt.pt.y), cvRound(kpt.pt.x));
const int step = (int)img.step;
// 旋转公式
// x'= xcos(θ) - ysin(θ)
// y'= xsin(θ) + ycos(θ)
#define GET_VALUE(idx) \
center[cvRound(pattern[idx].x*b + pattern[idx].y*a)*step + cvRound(pattern[idx].x*a - pattern[idx].y*b)]
for (int i = 0; i < 32; ++i, pattern += 16) {
int t0, t1, val;
t0 = GET_VALUE(0); t1 = GET_VALUE(1);
val = t0 < t1; // 描述子本字节的bit0
t0 = GET_VALUE(2); t1 = GET_VALUE(3);
val |= (t0 < t1) << 1; // 描述子本字节的bit1
t0 = GET_VALUE(4); t1 = GET_VALUE(5);
val |= (t0 < t1) << 2; // 描述子本字节的bit2
t0 = GET_VALUE(6); t1 = GET_VALUE(7);
val |= (t0 < t1) << 3; // 描述子本字节的bit3
t0 = GET_VALUE(8); t1 = GET_VALUE(9);
val |= (t0 < t1) << 4; // 描述子本字节的bit4
t0 = GET_VALUE(10); t1 = GET_VALUE(11);
val |= (t0 < t1) << 5; // 描述子本字节的bit5
t0 = GET_VALUE(12); t1 = GET_VALUE(13);
val |= (t0 < t1) << 6; // 描述子本字节的bit6
t0 = GET_VALUE(14); t1 = GET_VALUE(15);
val |= (t0 < t1) << 7; // 描述子本字节的bit7
//保存当前比较的出来的描述子的这个字节
desc[i] = (uchar)val;
}
}
ORBextractor类的用途

ORBextractor被用于Tracking线程对输入图像预处理的第一步.
ORBextractor类提取特征点的主函数void operator()()
这个函数重载了()运算符,使得其他类可以将ORBextractor类型变量当作函数来使用.
该函数是ORBextractor的主函数,内部依次调用了上面提到的各过程.
void operator()()
ComputeKeyPointsOctTree()
ComputeKeyPointsOctTree()
computeOrbDescriptor()
按CELL提取FAST特征点
computeOrientation()
计算每个特征点的主方向
DistributeOctTree()
筛选特征点,进行非极大值抑制
void ORBextractor::operator()(InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints, OutputArray _descriptors) {
// step1. 检查图像有效性
if(_image.empty())
return;
Mat image = _image.getMat();
assert(image.type() == CV_8UC1 );
// step2. 构建图像金字塔
ComputePyramid(image);
// step3. 计算特征点并进行八叉树筛选
vector<vector<KeyPoint> > allKeypoints;
ComputeKeyPointsOctTree(allKeypoints);
// step4. 遍历每一层图像,计算描述子
int offset = 0;
for (int level = 0; level < nlevels; ++level) {
Mat workingMat = mvImagePyramid[level].clone();
// 计算描述子之前先进行一次高斯模糊
GaussianBlur(workingMat, workingMat, Size(7, 7), 2, 2, BORDER_REFLECT_101);
computeDescriptors(workingMat, allKeypoints[level], descriptors.rowRange(offset, offset + allKeypoints[level].size());, pattern);
offset += allKeypoints[level].size();
}
}
这个重载()运算符的用法被用在Frame类的ExtractORB()函数中了,这也是ORBextractor类在整个项目中唯一被调用的地方.
// 函数中`mpORBextractorLeft`和`mpORBextractorRight`都是`ORBextractor`对象
void Frame::ExtractORB(int flag, const cv::Mat &im) {
if(flag==0)
(*mpORBextractorLeft)(im, cv::Mat(), mvKeys, mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}
ORBextractor类与其它类间的关系
Frame类中与ORBextractor有关的成员变量和成员函数
| 成员变量/函数 | 访问控制 | 意义 |
|---|---|---|
ORBextractor* mpORBextractorLeft |
public |
左目特征点提取器 |
ORBextractor* mpORBextractorRight |
public |
右目特征点提取器,单目/RGBD模式下为空指针 |
Frame() |
public |
Frame类的构造函数,其中调用ExtractORB()函数进行特征点提取 |
ExtractORB() |
public |
提取ORB特征点,其中调用了mpORBextractorLeft和mpORBextractorRight的()方法 |
// Frame类的两个ORBextractor是在调用构造函数时传入的,构造函数中调用ExtractORB()提取特征点
Frame::Frame(ORBextractor *extractorLeft, ORBextractor *extractorRight)
: mpORBextractorLeft(extractorLeft), mpORBextractorRight(extractorRight) {
// ...
// 提取ORB特征点
thread threadLeft(&Frame::ExtractORB, this, 0, imLeft);
thread threadRight(&Frame::ExtractORB, this, 1, imRight);
threadLeft.join();
threadRight.join();
// ...
}
// 提取特征点
void Frame::ExtractORB(int flag, const cv::Mat &im) {
if (flag == 0)
(*mpORBextractorLeft)(im, cv::Mat(), mvKeys, mDescriptors);
else
(*mpORBextractorRight)(im, cv::Mat(), mvKeysRight, mDescriptorsRight);
}
Frame类的两个ORBextractor指针指向的变量是Tracking类的构造函数中创建的
// Tracking构造函数
Tracking::Tracking() {
// ...
// 创建两个ORB特征点提取器
mpORBextractorLeft = new ORBextractor(nFeatures, fScaleFactor, nLevels, fIniThFAST, fMinThFAST);
if (sensor == System::STEREO)
mpORBextractorRight = new ORBextractor(nFeatures, fScaleFactor, nLevels, fIniThFAST, fMinThFAST);
// ...
}
// Tracking线程每收到一帧输入图片,就创建一个Frame对象,创建Frame对象时将提取器mpORBextractorLeft和mpORBextractorRight给构造函数
cv::Mat Tracking::GrabImageStereo(const cv::Mat &imRectLeft, const cv::Mat &imRectRight, const double ×tamp) {
// ...
// 创建Frame对象
mCurrentFrame = Frame(mImGray, imGrayRight, timestamp, mpORBextractorLeft, mpORBextractorRight);
// ...
}
由上述代码分析可知,每次完成ORB特征点提取之后,图像金字塔信息就作废了,下一帧图像到来时调用ComputePyramid()函数会覆盖掉本帧图像的图像金字塔信息;但从金字塔中提取的图像特征点的信息会被保存在Frame对象中.所以ORB-SLAM2是稀疏重建,对每帧图像只保留最多nfeatures个特征点(及其对应的地图点).
pdf版本笔记的下载地址: ORB-SLAM2代码详解02_特征点提取器ORBextractor,排版更美观一点,这个网站的默认排版太丑了(访问密码:3834)
ORBextractor()
pattern
umax
FAST特征点
iniThFAST搜索特征点
minThFAST搜索特征点
DistributeOctTree()对上一步找到的所有特征点进行八叉树筛选
对特征点密集区域进行非极大值抑制
computeOrientation()计算每个特征点的主方向