半监督3D医学图像分割(四):SASSNet
形状感知半监督医学图像分割
Shape-aware Semi-supervised 3D Semantic Segmentation for Medical Images
研究背景

- 随着人工智能技术在医疗领域的应用越来越广泛,开发自动、准确和可靠的医学图像处理算法对于计算机辅助诊断和手术导航系统至关重要。
- 传统的图像处理算法需要手动设计特征提取算子,深度学习算法基于给定数据和标签进行端到端的训练,并自动提取出对于目标最显著的特征。
- 图像分割是医学图像处理中的重要任务之一,基于深度学习的自动分割方法不需要医生进行手动标注,分割效率高且不会受到主观因素的影响。
- 深度学习归根结底是数据驱动的,模型训练的好坏取决于图像和标签的质量。
- 医学图像需要专业医师标注,特别是3D图像,标注代价昂贵。
- 有标签的数据集有限,而无标签的数据集有很多。
- 在医学图像处理领域,自监督学习、半监督学习以及无监督学习应用前景广阔。
自监督学习先使用大量无标签的数据集,通过对比学习和图像重建等方式构建损失函数,进行预训练,然后在特定任务上使用有标签的数据集进行微调。
半监督学习则是将少量有标注的数据和大量无标注的数据直接输入到网络中,构建损失函数,达到比单独用有标注数据集更好的结果。
半监督图像分割的方法大致可以分为三类:一是引入对抗损失,让无标和有标签图像的预测结果的分布尽量接近;二是引入一致性损失,
对图像加上不同的噪声或扰动,分别输入学生和教师模型中,让二者的输出保持一致,提高网络训练的稳定性。三是引入先验信息,例如
目标区域的解剖结构,在特定任务上提高分割精度。对抗损失和一致性损失是一种泛化的方法,在所有下游任务都起作用,但缺乏对空间
信息的挖掘,对边缘处理的不好。当分割区域的位置和形状差异较大时,先验解剖信息可能会起到反作用。
网络设计
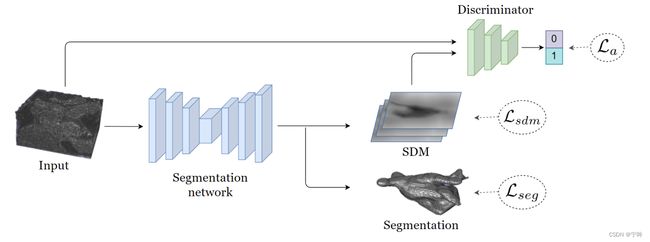
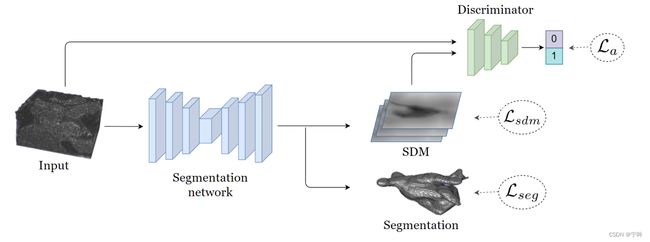
这篇文章提出的形状感知半监督分割方法,在网络中加入更灵活的几何表示,以便对分割输出执行全局形状约束,同时处理具有不同位置或形状的目标,探究有标签和无标签图像的预测结果在几何空间上的一致性。
作者在分割网络的最后一层,增加一条支路输出SDM(signed distance map,带符号距离映射),SDM是分割二值图中,每个像素到目标边界的距离,包含目标的表面和形状信息。为了利用无标签的图像,作者设计了一个判别器,利用有标签和无标签的图像的SDM计算对抗损失,目的是让网络学习到更丰富的形状感知信息。
M = f s e g ( X ; θ ) , S = f s d m ( X ; θ ) M=f_{seg}(X;\theta),S=f_{sdm}(X;\theta) M=fseg(X;θ),S=fsdm(X;θ)
θ 是网络参数, M ∈ [ 0 , 1 ] H × W × D 是分割预测结果, S ∈ [ − 1 , 1 ] H × W × D 是归一化后的距离映射 \theta是网络参数,M\in[0,1]^{H\times W\times D}是分割预测结果,S\in[-1,1]^{H\times W\times D}是归一化后的距离映射 θ是网络参数,M∈[0,1]H×W×D是分割预测结果,S∈[−1,1]H×W×D是归一化后的距离映射
SDM分支由一个1x1x1卷积层和激活函数tanh组成,值域限制在[-1, 1]。
有监督损失
L s ( θ ) = L s e g + α L s d m L_s(\theta)=L_{seg}+\alpha L_{sdm} Ls(θ)=Lseg+αLsdm
L s e g = 1 N ∑ i = 1 N l d i c e ( f s e g ( X i ; θ ) , Y i ) ; L s d m = 1 N ∑ i = 1 N l m s e ( f s d m ( X i ; θ ) , Z i ) L_{seg}=\frac{1}{N}\sum_{i=1}^{N}{l_{dice}(f_{seg}(X_i;\theta),Y_i)}; L_{sdm}=\frac{1}{N}\sum_{i=1}^{N}l_{mse}(f_{sdm}(X_i;\theta),Z_i) Lseg=N1i=1∑Nldice(fseg(Xi;θ),Yi);Lsdm=N1i=1∑Nlmse(fsdm(Xi;θ),Zi)
对抗损失
有标签的图像和无标签的图像,分别标记为1和0,判别器(D)的输出在[0, 1],越接近1,说明和有标签的图像越相似。
- 生成器损失:让有标签和无标签的图像的SDM尽量相似
L g ( θ , ζ ) = 1 M ∑ i = 1 M l o g D ( X i , f s d m ( X ; θ ) ; ζ ) L_g(\theta,\zeta)=\frac{1}{M}\sum_{i=1}^{M}logD(X_i,f_{sdm}(X;\theta);\zeta) Lg(θ,ζ)=M1i=1∑MlogD(Xi,fsdm(X;θ);ζ)
- 判别器损失:让判别器学会区分有标签和无标签的图像的SDM
L a ( θ , ζ ) = 1 N ∑ i = 1 N l o g D ( X i , S i ; ζ ) + 1 M ∑ i = N + 1 N + M l o g ( 1 − D ( X i , S i ; ζ ) ) L_a(\theta,\zeta)=\frac{1}{N}\sum_{i=1}^{N}logD(X_i,S_i;\zeta)+\frac{1}{M}\sum_{i=N+1}^{N+M}log(1-D(X_i,S_i;\zeta)) La(θ,ζ)=N1i=1∑NlogD(Xi,Si;ζ)+M1i=N+1∑N+Mlog(1−D(Xi,Si;ζ))
总体损失:
L o s s = L s e g ( θ ) + α L g ( θ , ζ ) + β L a ( θ , ζ ) Loss=L_{seg}(\theta)+\alpha L_g(\theta,\zeta)+\beta L_a(\theta,\zeta) Loss=Lseg(θ)+αLg(θ,ζ)+βLa(θ,ζ)
生成器损失L_g在论文中没有介绍,但代码中是用到了的,这里我做了一个补充。
有监督损失和对抗损失比较简单,具体看看代码就知道了,SDM的计算在代码部分会讲。
代码解读
在V-Net解码器的最后一层加了一个分支,输出SDM的预测结果
self.out_conv = nn.Conv3d(n_filters, n_classes, 1, padding=0)
self.out_conv2 = nn.Conv3d(n_filters, n_classes, 1, padding=0)
self.tanh = nn.Tanh()
out = self.out_conv(x9)
out_tanh = self.tanh(out)
out_seg = self.out_conv2(x9)
return out_tanh, out_seg
segmentation network与VNet的区别仅在于self.conv2和self.tanh- out_tanh和out_seg的形状都是
batch_size x n_classes x H x W x D
for epoch_num in iterator:
for i_batch, sampled_batch in enumerate(trainloader):
volume_batch, label_batch = sampled_batch['image'], sampled_batch['label']
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda()
# Generate Discriminator target based on sampler
Dtarget = torch.tensor([1, 1, 0, 0]).cuda()
model.train()
D.eval()
outputs_tanh, outputs = model(volume_batch)
outputs_soft = torch.sigmoid(outputs)
- 这里用的batch_size=4,前两张有标签,后两张无标签
- Dtarget是判别器的标签,用来区分SDM属于有标签的图像还是无标签的图像
# calculate the loss
with torch.no_grad():
gt_dis = compute_sdf(label_batch[:].cpu().numpy(), outputs[:labeled_bs, 0, ...].shape)
gt_dis = torch.from_numpy(gt_dis).float().cuda()
loss_sdf = mse_loss(outputs_tanh[:labeled_bs, 0, ...], gt_dis)
loss_seg = ce_loss(outputs[:labeled_bs, 0, ...], label_batch[:labeled_bs].float())
loss_seg_dice = losses.dice_loss(outputs_soft[:labeled_bs, 0, :, :, :], label_batch[:labeled_bs] == 1)
supervised_loss = loss_seg_dice + args.beta * loss_sdf
- 有监督的损失 = 分割损失 + SDM损失,对应公式
L s ( θ ) = L s e g + α L s d m L_s(\theta)=L_{seg}+\alpha L_{sdm} Ls(θ)=Lseg+αLsdm
L s e g = 1 N ∑ i = 1 N l d i c e ( f s e g ( X i ; θ ) , Y i ) ; L s d m = 1 N ∑ i = 1 N l m s e ( f s d m ( X i ; θ ) , Z i ) L_{seg}=\frac{1}{N}\sum_{i=1}^{N}{l_{dice}(f_{seg}(X_i;\theta),Y_i)}; L_{sdm}=\frac{1}{N}\sum_{i=1}^{N}l_{mse}(f_{sdm}(X_i;\theta),Z_i) Lseg=N1i=1∑Nldice(fseg(Xi;θ),Yi);Lsdm=N1i=1∑Nlmse(fsdm(Xi;θ),Zi)
分割损失没啥好讲的,重点看后一项,带符号距离映射(signed distance map)
def compute_sdf(img_gt, out_shape):
"""
compute the signed distance map of binary mask
input: segmentation, shape = (batch_size, x, y, z)
output: the Signed Distance Map (SDM)
sdf(x) = 0; x in segmentation boundary
-inf|x-y|; x in segmentation
+inf|x-y|; x out of segmentation
normalize sdf to [-1,1]
"""
img_gt = img_gt.astype(np.uint8)
normalized_sdf = np.zeros(out_shape)
for b in range(out_shape[0]): # batch size
posmask = img_gt[b].astype(np.bool)
if posmask.any():
negmask = ~posmask
posdis = distance(posmask)
negdis = distance(negmask)
boundary = skimage_seg.find_boundaries(posmask, mode='inner').astype(np.uint8)
# 归一化,分割区域内部为负,外部为正
sdf = (negdis-np.min(negdis))/(np.max(negdis)-np.min(negdis)) - (posdis-np.min(posdis))/(np.max(posdis)-np.min(posdis))
# 边界置零
sdf[boundary==1] = 0
normalized_sdf[b] = sdf
assert np.min(sdf) == -1.0, print(np.min(posdis), np.max(posdis), np.min(negdis), np.max(negdis))
assert np.max(sdf) == 1.0, print(np.min(posdis), np.min(negdis), np.max(posdis), np.max(negdis))
return normalized_sdf
- distance计算分割二值图中,每个像素到目标边界的距离
- 目标区域为1,背景为0,posdis是目标内部的距离图,negdis是目标内部的距离图,归一化得到SDM
- 左图是根据分割标签,计算得到的SDM;右图是标签在原图中的轮廓曲线。
生成器损失
consistency_weight = get_current_consistency_weight(iter_num//150)
Doutputs = D(outputs_tanh[labeled_bs:], volume_batch[labeled_bs:])
# G want D to misclassify unlabel data to label data.
loss_adv = F.cross_entropy(Doutputs, (Dtarget[:labeled_bs]).long())
loss = supervised_loss + consistency_weight*loss_adv
- D是判别器,根据输入图像和SDM,判断当前图像有无标签
loss_adv是判别器对无标签图像的预测结果,与真实标签之间的差异。相当于GAN网络中的生成器损失,目的拉近无标签的图像SDM和有标签图像的SDM
判别器由卷积层和线性层组成,是一个轻量级的网络

class FC3DDiscriminator(nn.Module):
def __init__(self, num_classes, ndf=64, n_channel=1):
super(FC3DDiscriminator, self).__init__()
# downsample 16
self.conv0 = nn.Conv3d(num_classes, ndf, kernel_size=4, stride=2, padding=1)
self.conv1 = nn.Conv3d(n_channel, ndf, kernel_size=4, stride=2, padding=1)
self.conv2 = nn.Conv3d(ndf, ndf*2, kernel_size=4, stride=2, padding=1)
self.conv3 = nn.Conv3d(ndf*2, ndf*4, kernel_size=4, stride=2, padding=1)
self.conv4 = nn.Conv3d(ndf*4, ndf*8, kernel_size=4, stride=2, padding=1)
self.avgpool = nn.AvgPool3d((7, 7, 5))
self.classifier = nn.Linear(ndf*8, 2)
self.leaky_relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
self.dropout = nn.Dropout3d(0.5)
def forward(self, map, image):
batch_size = map.shape[0]
map_feature = self.conv0(map)
image_feature = self.conv1(image)
x = torch.add(map_feature, image_feature)
x = self.leaky_relu(x)
x = self.dropout(x)
x = self.conv2(x)
x = self.leaky_relu(x)
x = self.dropout(x)
x = self.conv3(x)
x = self.leaky_relu(x)
x = self.dropout(x)
x = self.conv4(x)
x = self.leaky_relu(x)
x = self.avgpool(x)
x = x.view(batch_size, -1)
x = self.classifier(x)
x = x.reshape((batch_size, 2))
return x
- Image和SDM经过卷积层下采样一半后,特征相加,batch_size个分类概率向量
判别器损失
model.eval()
D.train()
with torch.no_grad():
outputs_tanh, outputs = model(volume_batch)
Doutputs = D(outputs_tanh, volume_batch)
# D want to classify unlabel data and label data rightly.
D_loss = F.cross_entropy(Doutputs, Dtarget.long())
- outputs_tanh是输入图像的SDM预测
- D_loss是判别器损失,目的是区分有标签图像的SDM和无标签图像的SDM
- loss_adv和D_loss相互对抗
L a ( θ , ζ ) = 1 N ∑ i = 1 N l o g D ( X i , S i ; ζ ) + 1 M ∑ i = N + 1 N + M l o g ( 1 − D ( X i , S i ; ζ ) ) L_a(\theta,\zeta)=\frac{1}{N}\sum_{i=1}^{N}logD(X_i,S_i;\zeta)+\frac{1}{M}\sum_{i=N+1}^{N+M}log(1-D(X_i,S_i;\zeta)) La(θ,ζ)=N1i=1∑NlogD(Xi,Si;ζ)+M1i=N+1∑N+Mlog(1−D(Xi,Si;ζ))
实验结果
论文实验
论文是在左心房数据集(LAHeart2018)上做的实验,一共100例,划分80例作为训练集,20例测试

我的实验
同样是LAHeart数据集,测试集的标签开源后,一共是154例,我用123例当训练集,31例当测试集
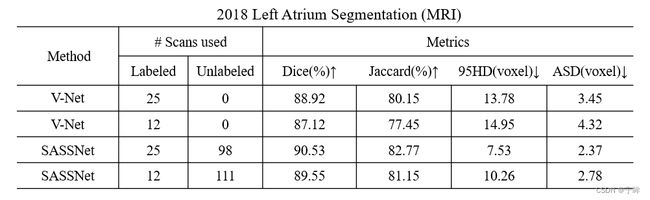
- 指标都有提升,20%的标签率时dice提高了1.61%,10%的标签率时dice提高了2.43%
训练曲线

- GAN损失,波动是正常的

loss是总的损失,loss_adv是对抗损失,loss_dice是dice损失,loss_seg是交叉熵,loss_hausdorff是SDM损失- 除对抗损失外,其他损失都是收敛的。对抗损失受生成器(V-Net)和判别器(D)的影响,波动是正常的。
论文里说SSASNet比UA-MT强不少,但是我用起来感觉两个差不多,最后放一个论文的可视化结果

SSASNet是生成对抗网络在半监督图像分割中的典型应用,在网络最后一层增加一个分支额外执行一个任务,让判别器学会区分有标签和无标签的图像预测结果,从而将无标签图像利用起来。
参考资料:
Li, Shuailin, Chuyu Zhang, and Xuming He. “Shape-aware semi-supervised 3D semantic segmentation for medical images.” International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2020.
项目地址:
LASeg: 2018 Left Atrium Segmentation (MRI)
如有问题,欢迎联系 ‘[email protected]’