【重磅推荐】哥大开源“FinRL”: 一个用于量化金融自动交易的深度强化学习库
深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
编辑:DeepRL
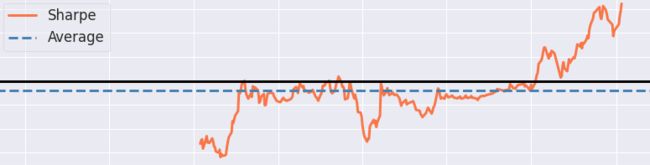
一、关于FinRL
目前,深度强化学习(DRL)技术在游戏等领域已经取得了巨大的成功,同时在量化投资中的也取得了突破性进展,为了训练一个实用的DRL 交易agent,决定在哪里交易,以什么价格交易以及交易的数量,这是一个具有挑战性的问题,那么强化学习到底如何与量化交易进行结合呢?下图是一张强化学习在量化交易中的建模图:

市面上有很多研究机构和高校正在研究强化学习技术解决量化交易问题,其中比较知名的有“FinRL”,它是一个解决量化交易的开放源代码库,可为从业人员提供流水线式的策略开发的统一框架。
我们知道在强化学习中,智能体通过试错方式与环境进行持续交互学习,以取得最大累计回报。很荣幸, FinRL(有效地实现交易自动化)提供了有关定量金融中的深度强化学习的教育资源,为各种市场、基准财务任务(投资组合分配,加密货币交易,高频交易),实时交易等提供了统一的机器学习框架,下面是两篇FinRL团队已发表的相关论文:


那么FinRL库是怎么来的?有哪些内容组成,包含哪些模块呢?
这还得从强化学习的发展说起,下图是该团队汇总的强化学习到FinRL的发展过程,其中FinRL中包含了很多现有的强化学习算法的描述和实现。
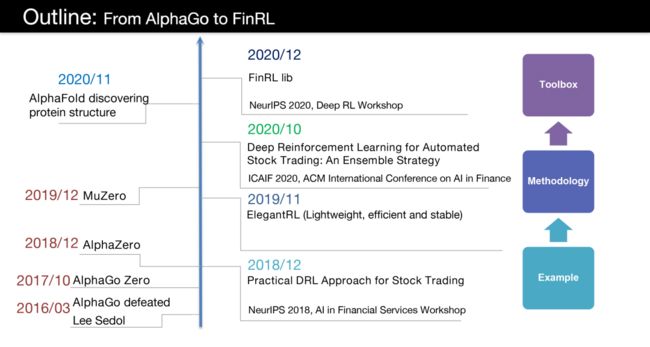
一方面,FinRL库可帮助初学者了解量化金融并制定自己的股票交易策略。其允许用户简化自己的开发并轻松地与现有方案进行比较。在FinRL中,虚拟环境配置有股票市场数据集,智能体利用神经网络进行训练,并通过股票回测验证算法性能。此外,它包含了重要的市场摩擦,例如交易成本,市场流动性和投资者的风险规避程度。
另外一方面, FinRL具有完整性,动手指南和可重复性的特点,特别适合初学者:
在多个时间粒度级别上,FinRL模拟了各个股票市场的交易环境,包括NASDAQ-100,DJIA,S&P 500,HSI,SSE 50,和CSI 300。
FinRL采用模块化结构的分层架构。提供了自己开发的轻量级的DRL算法库ElegantRL(https://github.com/AI4Finance-LLC/ElegantRL),其中包含DDPG,TD3, SAC, PPO(GAE),DQN,DoubleDQN, DuelingDQN, D3QN,并支持用户自定义算法。
高度可扩展,FinRL保留了一套完整的用户导入界面。
最后,FinRL的成功得益于对环境的定义, FinRL量化交易环境中:状态空间、动作空间和奖励函数的定义。
我们知道解决一个问题最难的部分是建模部分,强化学习整体由环境、智能体和奖励函数三部分组成,那么对于量化交易来说,环境,智能体算法,奖励分别对应什么呢,下图对FinRL-Gym等环境,状态,动作和奖励进行定义和阐述。



了解了上面FinRL的组成部分,下面我们解释一下FinRL的工作流程。
训练-验证-测试(如下图所示)

二、整体结构图
前文解释了FinRL的组成部分,状态定义等内容,下图为大家呈现FinRL框架的实现整体包含了环境(FinRL-Gym)、算法和应用三部分,如下图所示:

在了解FinlRL组成框架的基础上,下面我们对FinRL核心部件ElegantRL进行介绍。
三、核心部件简介:ElegantRL
从第二部分的整体框架图中,我们看到了算法部分由ElegantRL组成,其中它包含了目前存在的绝多数算法demo,但ElegantRL有其自身的优势,具体如下:


图中Agent.py中的智能体使用Net.py中的网络,并且通过与Env.py中的环境进行交互在Run.py中进行了训练。
目前ElegantRL已经包含了常见的各类强化学习算法,最关键的是它相比于其他开源框架,具有以下方面的优势:
轻量级:核心代码少于1,000行。
高效:性能可与Ray RLlib媲美。
稳定:比稳定基准更稳定,支持最新的DRL算法,包括离散算法和连续算法。
四、FinRL贡献
一个好的框架一定满足简单易用,高效稳定可拓展的特性,那么FinRL框架有哪些贡献或者说优点呢?如下图所示:

五、视频详解
本视频是论文、开源框架作者对FinRL的一个解读,B站链接见视频下方。
https://www.bilibili.com/video/bv1VZ4y1P7Dy
以上是对FinRL的原理,整体构架以及核心模块的介绍,但泰山还得一步一步爬,很多同学最担心的代码实现我们还是双手奉上。
代码整体包含两部分:
第一部分(六),直接采用克隆仓库,运行代码。
第二部分(七),通过jupyter一步步实现强化学习量化交易过程,值得每一位学习者认真学习(强烈推荐)。
六、安装使用(Installation)
bin操作
$ sudo chmod -R 777 docker/bin
# build the container!
$ ./docker/bin/build_container.sh
# start notebook on port 8887!
$ ./docker/bin/start_notebook.sh
手动操作
$ docker build -f docker/Dockerfile -t finrl docker/
Start the container:
$ docker run -it --rm -v ${PWD}:/home -p 8888:8888 finrl
克隆仓库及安装
git clone https://github.com/AI4Finance-LLC/FinRL-Library.git
Install the unstable development version of FinRL:
pip install git+https://github.com/AI4Finance-LLC/FinRL-Library.gitev libgl1-mesa-g导入代码
import pkg_resources
import pip
installedPackages = {pkg.key for pkg in pkg_resources.working_set}
required = {'yfinance', 'pandas', 'matplotlib', 'stockstats','stable-baselines','gym','tensorflow'}
missing = required - installedPackages
if missing:
!pip install yfinance
!pip install pandas
!pip install matplotlib
!pip install stockstats
!pip install gym
!pip install stable-baselines[mpi]
!pip install tensorflow==1.15.4
# import packages
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('Agg')
import datetime
from finrl.config import config
from finrl.marketdata.yahoodownloader import YahooDownloader
from finrl.preprocessing.preprocessors import FeatureEngineer
from finrl.preprocessing.data import data_split
from finrl.env.environment import EnvSetup
from finrl.env.EnvMultipleStock_train import StockEnvTrain
from finrl.env.EnvMultipleStock_trade import StockEnvTrade
from finrl.model.models import DRLAgent
from finrl.trade.backtest import BackTestStats, BaselineStats, BackTestPlot实验结果如下:
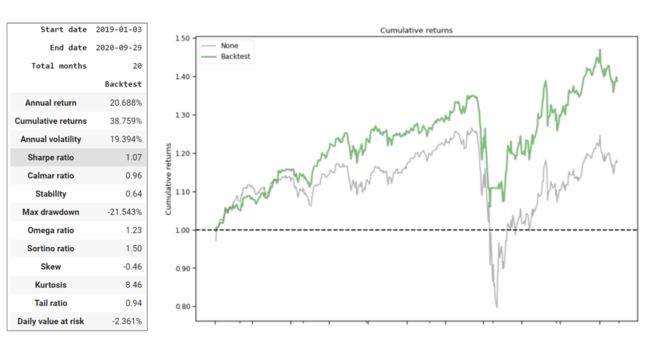
七、Jupyter论文复现,九步复现强化学习股票交易
(注:github代码见第九步后面)
7.1 Jupyter安装方法及过程
具体参考:https://www.jianshu.com/p/91365f343585
7.2 复现“Deep Reinforcement Learning for Stock Trading from Scratch: Multiple Stock Trading Using Ensemble Strategy”
第一步:安装依赖包

第二步:导入包
第三步:创建文件目录

第四步:下载数据

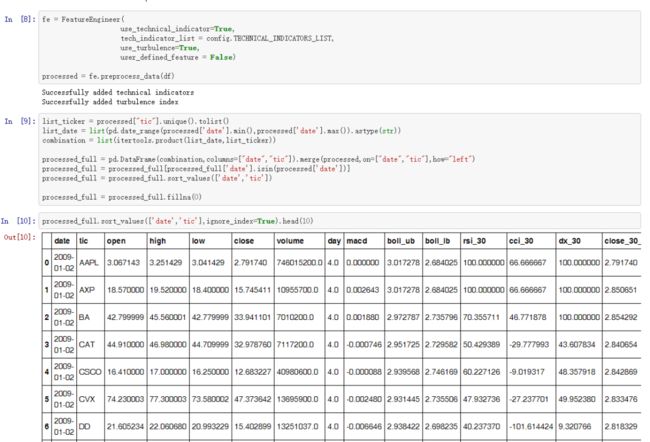
第五步:处理数据
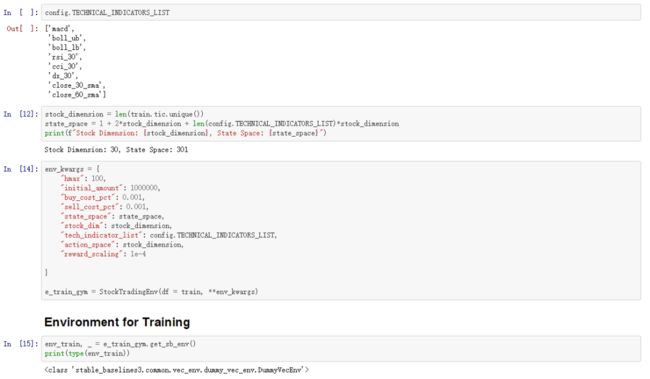
第六步:设计强化学习环境

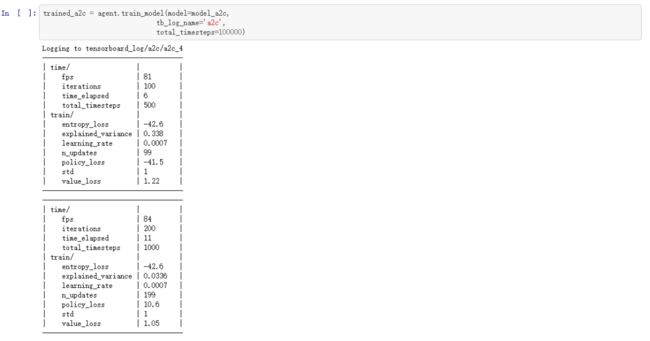
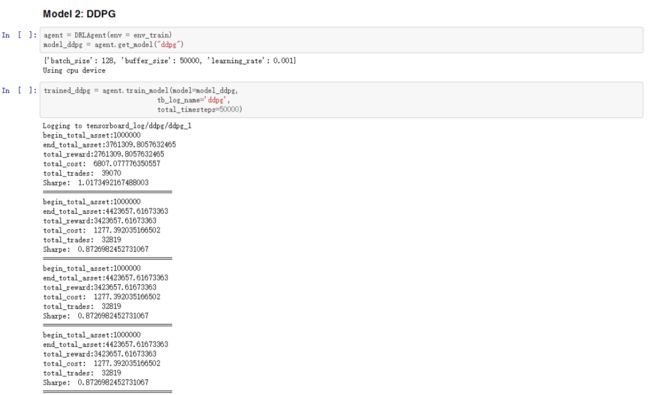
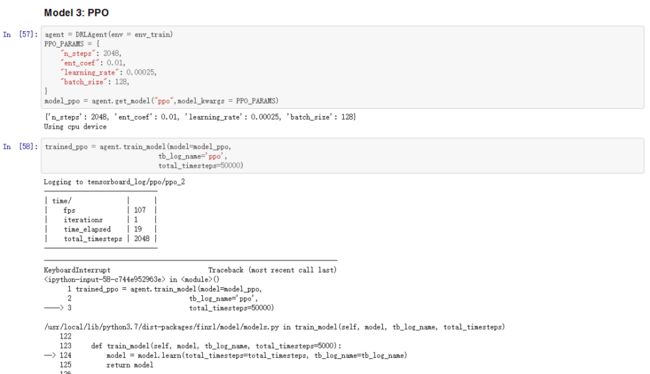
第七步:执行强化学习算法



第八步:测试算法策略

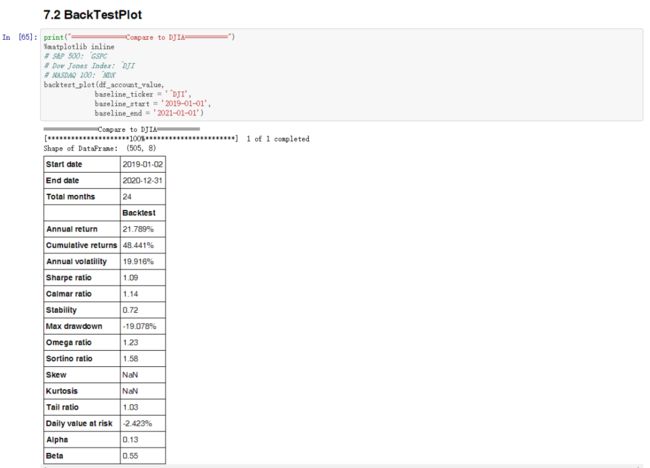

第九步:实验绘图



完整ipynb代码地址:
1.https://github.com/AI4Finance-LLC/FinRL-Library/blob/master/FinRL_stock_trading_NeurIPS_2018.ipynb
相关资料链接
Arxiv: https://arxiv.org/pdf/2011.09607v1.pdf
Github: https://github.com/AI4Finance-LLC/FinRL-Library
视频:https://www.youtube.com/watch?v=ZSGJjtM-5jA
B站视频:https://www.bilibili.com/video/bv1VZ4y1P7Dy
论文1: https://arxiv.org/abs/1811.07522
论文2. https://arxiv.org/abs/2011.09607
FinRL将持续更新和完善,更多请查看“阅读原文”
(http://deeprl.neurondance.com/t/finrl)
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第103篇:解决MAPPO(Multi-Agent PPO)技巧
第102篇:82篇AAAI2021强化学习论文接收列表
第101篇:OpenAI科学家提出全新强化学习算法
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第99篇:NeoRL:接近真实世界的离线强化学习基准
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第92篇:谷歌AI掌门人Jeff Dean获冯诺依曼奖
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
