语义分割代码解读一(FCN, UNet, SegNet)
1.FCN
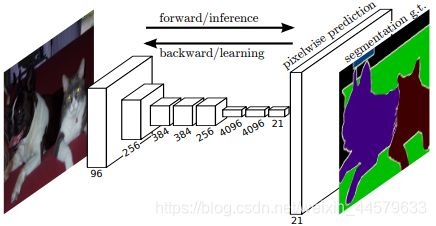
简单的来说,FCN与CNN的区别在把于CNN最后的全连接层换成卷积层,让卷积网络在一张更大的输入图片上滑动,得到多个输出,这样的转化可以让我们在单个向前传播的过程中完成上述的操作。
When these receptive fields overlap significantly, both feedforward computation and backpropagation are much more efficient when computed layer-by-layer over an entire image instead of independently patch-by-patch.
当这些接受域明显重叠时,在整个图像上逐层计算而不是逐个块地独立计算时,前馈计算和反向传播都要高效得多。
(1)正向传递过程
全卷积网络的基础网络即根据上图中的顺序依次通过几层卷积层,之后通过几层dropout层,得到不同层的预测结果,论文中还采用了如下图所示的方式来融合各个层之间的特征。
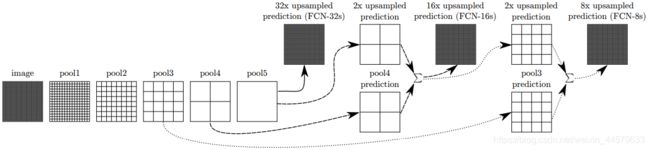
FCN32s表示特征图为原图像大小的1/32,可以采用任意一个普通的分类网络提取到代特征图大小,然后用上图所示方法融合,即:
pool5预测的结果FCN32s,经过上采样后被放大两倍,与pool4预测的结果相加,得到FCN16sFCN16s,经过上采样后被放大两倍,与pool3预测的结果相加,得到FCN8s
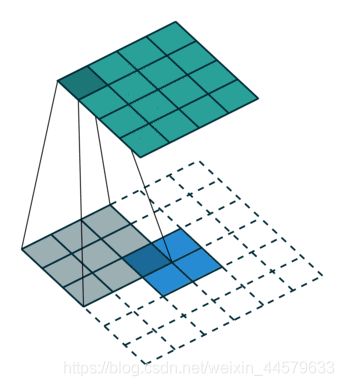
上采样的示意图如下图所示:
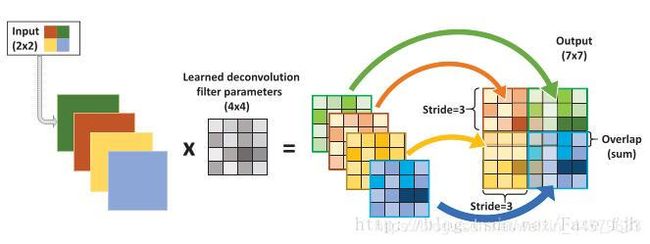
(2) 反向传递过程
用到了反卷积,示意图如下图所示:
例如下面是用pytorch实现fcn8s的一个例子,注意例子中每一层的卷积核数和论文中有差别。
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
# pretrained_net可以采用vggnet等分类网络
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv2(score)) # size=(N, 256, x.H/8, x.W/8)
score = self.bn2(score + x3) # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
2. UNet
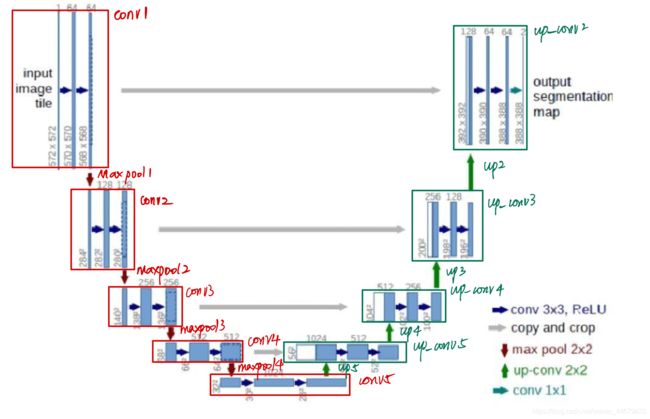
UNet 为对称语义分割模型,该网络模型主要由一个收缩路径和一个对称扩张路径组成,收缩路径用来获得上下文信息,对称扩张路径用来精确定位分割边界。下面是用pytorch实现unet的一个例子。
class conv_block(nn.Module):
"""
Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Module):
"""
Up Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
class U_Net(nn.Module):
"""
UNet - Basic Implementation
Paper : https://arxiv.org/abs/1505.04597
"""
def __init__(self, in_ch=3, out_ch=1):
super(U_Net, self).__init__()
n1 = 64
filters = [n1, n1 * 2, n1 * 4, n1 * 8, n1 * 16]
self.Maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(in_ch, filters[0])
self.Conv2 = conv_block(filters[0], filters[1])
self.Conv3 = conv_block(filters[1], filters[2])
self.Conv4 = conv_block(filters[2], filters[3])
self.Conv5 = conv_block(filters[3], filters[4])
self.Up5 = up_conv(filters[4], filters[3])
self.Up_conv5 = conv_block(filters[4], filters[3])
self.Up4 = up_conv(filters[3], filters[2])
self.Up_conv4 = conv_block(filters[3], filters[2])
self.Up3 = up_conv(filters[2], filters[1])
self.Up_conv3 = conv_block(filters[2], filters[1])
self.Up2 = up_conv(filters[1], filters[0])
self.Up_conv2 = conv_block(filters[1], filters[0])
self.Conv = nn.Conv2d(filters[0], out_ch, kernel_size=1, stride=1, padding=0)
# self.active = torch.nn.Sigmoid()
def forward(self, x):
# 收缩路径
e1 = self.Conv1(x)
e2 = self.Maxpool1(e1)
e2 = self.Conv2(e2)
e3 = self.Maxpool2(e2)
e3 = self.Conv3(e3)
e4 = self.Maxpool3(e3)
e4 = self.Conv4(e4)
e5 = self.Maxpool4(e4)
e5 = self.Conv5(e5)
# 扩张路径
d5 = self.Up5(e5)
d5 = torch.cat((e4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
# 特征融合(拼接)
d4 = torch.cat((e3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
# 特征融合(拼接)
d3 = torch.cat((e2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
# 特征融合(拼接)
d2 = torch.cat((e1, d2), dim=1)
d2 = self.Up_conv2(d2)
out = self.Conv(d2)
return out
3. SegNet
SegNet和FCN思路十分相似,只是Encoder、Decoder(Upsampling)使用的技术不一致,在SegNet中的Pooling与UnPooling多了一个index功能。
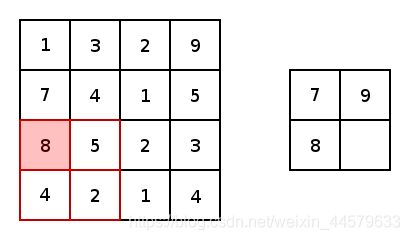
如上图所示,由左到右为一个最大池化过程,由右到左为一个上采样过程。但是在上采样当中存在着一个不确定性,即左图中的某个1x1区域将会被右图的1x1特征点取代,如果是随机将这个特征点分配到任意的一个位置或者分配到一个固定的位置会引入误差,这是我们所不希望的。
那么在Decoder中需要对特征图进行上采样的时候,我们就可以利用它对应的池化层的Pooling Indices来确定某个1x1特征点应该放到上采样后的2x2区域中的哪个位置。此过程的如下图所示。
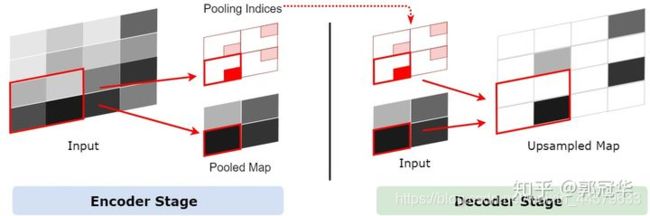
这一功能已经被添加在pytorch官方函数中。使用方法即在使用MaxPool2d时将return_indices设置为True(默认为False)。以下为MaxPool2d的参数:
一个使用return_indices的例子如下
import torch.nn as nn
pool = nn.MaxPool2d(2, stride=2, return_indices=True)
unpool = nn.MaxUnpool2d(2, stride=2)
下面是我用pytorch实现segnet的一个例子。
class conv_block(nn.Module):
def __init__(self, in_ch, out_ch, batchNorm_momentum = 0.1, three = False):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
nn.BatchNorm2d(out_ch, momentum= batchNorm_momentum),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class SegNet(nn.Module):
def __init__(self,input_nbr,label_nbr):
super(SegNet, self).__init__()
batchNorm_momentum = 0.1
self.Conv11 = conv_block(input_nbr, 64, batchNorm_momentum)
self.Conv12 = conv_block(64, 64, batchNorm_momentum)
self.Maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv21 = conv_block(64, 128, batchNorm_momentum)
self.Conv22 = conv_block(128, 128, batchNorm_momentum)
self.Maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv31 = conv_block(128, 256, batchNorm_momentum)
self.Conv32 = conv_block(256, 256, batchNorm_momentum)
self.Conv33 = conv_block(256, 256, batchNorm_momentum)
self.Maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv41 = conv_block(256, 512, batchNorm_momentum)
self.Conv42 = conv_block(512, 512, batchNorm_momentum)
self.Conv43 = conv_block(512, 512, batchNorm_momentum)
self.Maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv51 = conv_block(512, 512, batchNorm_momentum)
self.Conv52 = conv_block(512, 512, batchNorm_momentum)
self.Conv53 = conv_block(512, 512, batchNorm_momentum)
self.Maxpool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.MaxUnpool5 = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.Conv53d = conv_block(512, 512, batchNorm_momentum)
self.Conv52d = conv_block(512, 512, batchNorm_momentum)
self.Conv51d = conv_block(512, 512, batchNorm_momentum)
self.MaxUnpool4 = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.Conv43d = conv_block(512, 512, batchNorm_momentum)
self.Conv42d = conv_block(512, 512, batchNorm_momentum)
self.Conv41d = conv_block(512, 256, batchNorm_momentum)
self.MaxUnpool3 = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.Conv33d = conv_block(256, 256, batchNorm_momentum)
self.Conv32d = conv_block(256, 256, batchNorm_momentum)
self.Conv31d = conv_block(256, 128, batchNorm_momentum)
self.MaxUnpool2 = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.Conv22d = conv_block(128, 128, batchNorm_momentum)
self.Conv21d = conv_block(128, 64, batchNorm_momentum)
self.Conv22d = conv_block(64, 64, batchNorm_momentum)
self.Conv11d = nn.Conv2d(64, label_nbr, kernel_size=3, padding=1)
self.relu1d = nn.ReLU(inplace=True)
def forward(self, x):
# Stage 1
x1 = self.Conv11(x)
x1 = self.Conv12(x1)
x1 = self.Maxpool1(x1)
# Stage 2
x2 = self.Conv21(x1)
x2 = self.Conv22(x1)
x2 = self.Maxpool2(x2)
# Stage 3
x3 = self.Conv31(x2)
x3 = self.Conv32(x3)
x3 = self.Conv33(x3)
x3 = self.Maxpool3(x3)
# Stage 4
x4 = self.Conv41(x3)
x4 = self.Conv42(x4)
x4 = self.Conv43(x4)
x4 = self.Maxpool4(x4)
# Stage 5
x5 = self.Conv51(x4)
x5 = self.Conv52(x5)
x5 = self.Conv53(x5)
x5 = self.Maxpool5(x5)
# Stage 5d
x5d = self.MaxUnpool5(x5)
x5d = self.Conv53d(x5d)
x5d = self.Conv52d(x5d)
x5d = self.Conv51d(x5d)
# Stage 4d
x4d = self.MaxUnpool4(x5d)
x4d = self.Conv43d(x4d)
x4d = self.Conv42d(x4d)
x4d = self.Conv41d(x4d)
# Stage 3d
x3d = self.MaxUnpool3(x4d)
x3d = self.Conv33d(x3d)
x3d = self.Conv32d(x3d)
x3d = self.Conv31d(x3d)
# Stage 2d
x2d = self.MaxUnpool2(x3d)
x2d = self.Conv22d(x2d)
x2d = self.Conv21d(x2d)
# Stage 1d
x1d = self.MaxUnpool1(x2d)
x1d = self.Conv12d(x1d)
x1d = self.Bn1d(x1d)
x1d = self.ReLU(x1d)
x1d = self.Conv11d(x1d)
return x1d
4. Dilated Convolution
使用了空洞卷积,这是一种可用于密集预测的卷积层。示意图如下:
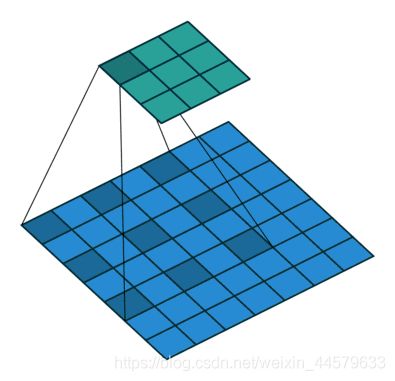
原论文中对于参数的介绍图如下:
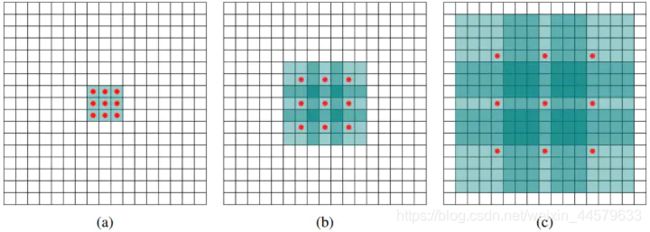
(a) 对应3x3的1-dilated conv,和普通的卷积操作一样。
(b) 对应3x3的2-dilated conv,实际的卷积核大小还是3x3,但是间隔为1,能达到7x7的感受野。
© 对应3x3的4-dilated conv,同理,能达到15x15的感受野。
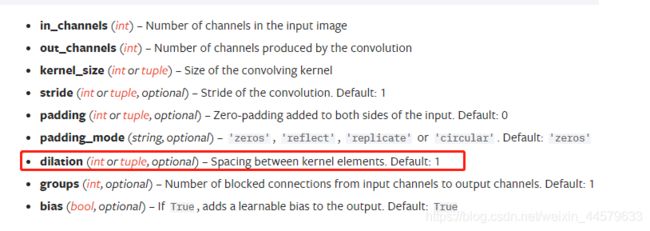
使用方法:在pytorch官方文档中使用dilation参数。
论文理解部分参考了以下博客:
【语义分割】一篇看完就懂的最新深度语义分割模型综述
史上最全语义分割综述(FCN,UNet,SegNet,Deeplab,ASPP…)