Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
一、摘要
自下而上的机制(基于Faster R-CNN):提取出图像区域,每个区域都有一个相关的特征向量。
自上而下的机制:确定特征权重。
提出了一种自下而上和自上而下的结合注意力机制,使注意力能够在对象和其他显著图像区域上计算。这是注意力(Attention)被考虑的基础。
二、简介
视觉注意机制:基于深度神经网络架构,通过学习 关注图像中显著的区域来提高性能。
自上而下(Top-Down ):非视觉或任务特定环境驱动的注意机制。
自下而上(Bottom-Up ):纯视觉前馈注意机制。
图像字幕(Image Captioning)和视觉问答(VQA) 通常需要执行一些细粒度的可视化处理,甚至多个推理步骤来生成高质量的输出。
大多数用于图像字幕和VQA的传统视觉注意机制都是自上而下的。它们一般被训练为只是选择性地关注CNN输出中的某一层或某几层。然而,这种方法很少考虑如何确定受注意的图像区域。

本文提出了一种自下而上和自上而下结合的视觉注意机制。
自下而上(Bottom-Up)机制提取出了一组显著图像区域,每个区域由一个汇集的卷积特征向量表示。使用Faster R-CNN实现自下而上的注意,它代表了自下而上注意机制的自然表达。
自上而下(Top-Down)的机制使用任务特定的上下文(context)来预测图像区域的注意力分布。然后,将参与的特征向量计算为所有区域图像特征的加权平均值。
三、相关工作
大量基于注意力的深度神经网络被提出用于图像字幕和VQA。通常,这些模型可以被描述为自顶向下(Top-Down)的方法。
这些方法确定图像区域的最佳数量时总是需要在粗和细的细节水平之间进行无法取胜的权衡。此外,区域相对于图像内容的任意定位可能使得难以检测与区域对齐不良的物体,并难以绑定与同一物体相关的视觉概念。
以前的工作相对较少考虑将注意力应用到突出的图像区域。
本文利用了Faster R-CNN,在视觉和语言任务与物体检测的当前进展之间建立了更紧密的联系。
通过这种方法,能够在目标检测数据集上预先训练区域建议(region proposals)。从概念上讲,这种优势应该类似于在ImageNet上进行预先训练的视觉表示,并且能够显著利用更大的跨领域知识。
四、方法
给定一个图像I,我们的图像字幕模型和视觉问答模型都将一个可能大小不等的k个图像特征集作为输入,![]() ,使得每个图像特征对图像的一个突出区域进行编码。空间图像特征V可以定义为自下而上(Bottom-Up)注意力模型的输出,或者按照标准做法,定义为卷积神经网络(CNN)的空间输出层。本文中的注意力机制,都使用的是简单的one-pass注意力机制(这里的one-pass机制有待了解)。
,使得每个图像特征对图像的一个突出区域进行编码。空间图像特征V可以定义为自下而上(Bottom-Up)注意力模型的输出,或者按照标准做法,定义为卷积神经网络(CNN)的空间输出层。本文中的注意力机制,都使用的是简单的one-pass注意力机制(这里的one-pass机制有待了解)。
4.1 自下而上(Bottom-Up)的注意力模型
根据边界框来定义空间区域,并使用Faster R-CNN实现自下而上的注意力。
Faster R-CNN是一个对象检测模型,设计用于识别属于特定类的对象实例,并使用边界框对其进行定位。
Faster R-CNN检测物体分两个阶段。第一阶段被称为区域候选网络(RPN),预测候选区域。一个小的网络在CNN的中间水平(level)的特征上滑动。在每个空间位置上,网络预测一个类未知的目标评分(class-agnostic objectness score)和一个经过边界框优化的多个尺度和长宽比的锚盒(anchor box)。采用贪心非最极大值抑制和交叉过并(intersection-over-union (IoU))阈值,选择最优的边界框提议作为第二阶段的输入。
在第二阶段,使用感兴趣区域(RoI)池为每个框提案提取一个小的特征图(例如14×14)。然后将这些特征映射批处理在一起,作为CNN最终层的输入。模型的最终输出包括类标签上的softmax分布和针对每个框提议的特定于类(class-specific)的包围框的优化。

在这项工作中,我们将Faster R-CNN与ResNet-101 CNN结合使用。为了生成用于图像字幕或视觉问答的图像特征输出集V,我们获取模型的最终输出,并使用IoU阈值对每个对象类执行非最大抑制。然后,我们选择类检测概率超过置信阈值的所有区域。对于每个选定的区域i, vi定义为来自该区域的均值池卷积特征,使图像特征向量的维数D为2048。以这种方式使用,Faster R-CNN有效地发挥了“硬”注意机制的作用,因为从大量可能的配置中只选择了相对较少的图像包围框特征。
为了对自底向上(bottom-up)注意力模型进行预训练,我们首先使用预训练的ResNet-101在ImageNet上初始化Faster R-CNN。然后我们在Visual Genome数据集上进行训练。为了帮助学习更好的特征表达,我们添加了一个额外的训练输出来预测属性类(除了对象类)。为了预测区域i的属性,我们将平均池化卷积特征vi与学习到的ground-truth的对象类embedding连接起来,并将其输入额外的输出层,在每个属性类和“无属性”类上定义一个softmax分布。(也就是能够得出区域i的属性在各种属性类别的概率分布)
原始的Faster R-CNN多任务损失函数包含四个组件,RPN的锚框分类、回归计算,以及最终的物体包围框分类、回归计算。我们保留这些成分,并添加一个额外的多类损失成分来训练属性预测器。
4.3 VQA Model
给定一组空间图像特征V,我们提出的VQA模型还使用“软的”自顶向下的注意机制来对每个特征进行加权,使用问题表示作为上下文。

图4. VQA模型的概述。深度神经网络实现了问题和图像特征{v1,…, vk}的联合嵌入。这些特征可以定义为CNN的空间输出,或者遵循我们的方法,使用自下而上的注意力生成。输出是由对固定的候选答案集操作的多标签分类器生成的。灰色数字表示层与层之间的向量表示的维度。黄色元素使用学习到的参数。
1.Question embedding
首先,输入的问题会被标记化:首先使用标点符号和空格将其分成单词,这里为了计算的效率,一个问题最多被修剪成14个单词,多余的单词会被丢弃(整个数据集中只有0.25%的问题超过了14个单词)。使用Wikipedia/Gigaword语料库上Glove公开版本来进行词特征向量化,对于少于14个词的,使用end-padded进行补零操作。每个单词都被转换为带有查找表的矢量表示,而其表项是在训练期间沿着其他参数学习的300维矢量表示,则一个问题可以被表述为14X300的矩阵。这个结果要经过GRU(Recurrent Gated Unit 循环门控单元),该循环门控单元有512维的内部状态,我们只用其最终状态,即在处理了14个字嵌入后,我们的结果问题嵌入为q,这个q是512维的。
2. Image features from bottom-up attention
输入图像特征是上文中经过faster R-CNN处理的k个2048维的特征向量。
3. top-down attention on image features
论文中的模型实现了大多数现代VQA模型中常见的经典的question-guided注意力机制,这个阶段被称为top-down attention(自上而下注意力机制)。在经过前面的Faster R-CNN后,图片被分为K个区域,每个区域都有一个特征向量Vi(V1,V2,V3,…Vi).Vi和问题嵌入q都分别经过一个非线性层,再经过一个线性层,去获得与对应的区域i有关的标量注意力权重αi,t。

(1)ai是指问题对第i个区域的注意力机制,fa指非线性层,Vi指与区域有关的特征向量,q是指嵌入的问题,Wa是指Learned parameter vector。
(2)所有的区域的注意力都经过softmax函数转为[0,1]之间的概率。
(3)αi与Vi的乘积代表第i个区域的加上了问题对图片的注意力的特征向量,公式(3)对每个区域的特征向量进行了一个加权求和,所得V-hat指的就是整个图片加上问题对图片的注意力的特征向量。
4. Multimodal fusion
在多模式融合之前,问题向量q和图片特征向量V-hat分别经过了一个非线性层,这个非线性层的功能可以理解为改变维度,方便二者融合时矩阵元素相乘。此时二者的维度都为512维。fq(q)和fv(V-hat)经过Hadamard乘积进行融合(即元素乘法),结果向量由h表示,即h表示图片和问题的联合嵌入结果。接着这个结果被喂入分类器。

5.其他
- 对提出的模型实现了问题和图片的多模态embedding,通过在候选答案中预测得分回归。
- 这篇论文中,并不像其他模型中使用的ReLU激活函数,而是在所有的非线性层中使用了gated tanh activation作为激活函数:
 ,参数a={W,W′,b,b′}:
,参数a={W,W′,b,b′}: 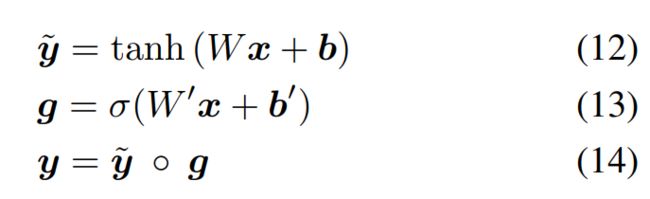
σ是sigmod激活函数,W,W′∈Rm×n(R为m行n列矩阵)是可学习的权重,b,b′∈Rn(R为n阶向量)是可学习的偏置,○是点乘。向量g作为中间激活y~d的门乘法。
6.损失函数为二元交叉熵损失函数,具体公式如下:

其中,M代表训练问题个数;N代表候选答案个数(3129个);Sij代表第i个训练问题的第j个候选答案的真实分数;Sij(hat)代表第i个训练问题的第j 个候选答案的预测分数。
五、数据集
4.1.3 vqa v2.0数据库
为了评估我们提出的VQA模型,我们使用了最近引入的VQA v2.0数据集,它试图通过平衡每个问题的答案来最小化学习数据集先验的有效性。该数据集被用作2017年VQA挑战的基础,包含110万个问题,1110万个答案与MSCOCO图像有关。
我们执行标准的问题文本预处理和标记化。为了计算效率,问题被精简到最多14个单词。候选答案集仅限于训练集中出现次数超过8次的正确答案,输出词汇量为3129。我们的VQA测试服务器提交的文件经过培训和验证集,以及来自Visual Genome的额外问题和答案。为了评估答案的质量,我们使用标准VQA度量报告准确性,这考虑到注释者之间对ground-truth答案的偶尔分歧。
4.4. VQA Results
在表4中,我们报告了完整的自上而下VQA模型相对于VQA 2.0验证集上的几个ResNet基线的单一模型性能。尽管ResNet基线使用了大约两倍的卷积层,但自底向上注意的添加在所有问题类型的最佳ResNet基线之上提供了显著的改进。表5报告了官方VQA 2.0测试标准评估服务器上30个集成模型的性能,以及先前发布的基线结果和其他最高排名的条目。在提交的时候(2017年8月8日),我们超过了所有其他测试服务器提交。我们的作品还获得了2017年VQA挑战赛的第一名。


六、代码复现