YoloV4-tiny网络结构搭建
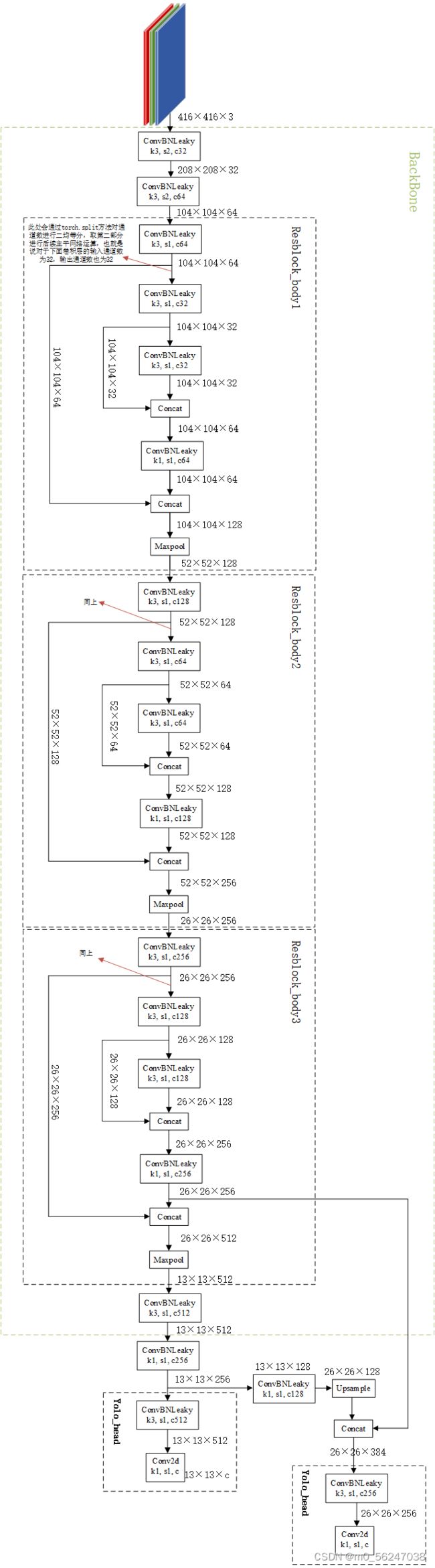
YoloV4-tiny网络结构图
一、基本的卷积块Conv + BN + LeakyReLU
# 卷积块
# Conv2d + BatchNorm2d + LeakyReLU
#-------------------------------------------------#
class ConvBNLeaky(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(ConvBNLeaky, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = nn.LeakyReLU(0.1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
二、定义Resblock_body结构
# CSPdarknet53-tiny的结构块
# 存在一个大残差边
# 这个大残差边绕过了很多的残差结构
#---------------------------------------------------#
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels):
super(Resblock_body, self).__init__()
self.out_channels = out_channels
self.conv1 = ConvBNLeaky(in_channels, out_channels, 3)
self.conv2 = ConvBNLeaky(out_channels//2, out_channels//2, 3)
self.conv3 = ConvBNLeaky(out_channels//2, out_channels//2, 3)
self.conv4 = ConvBNLeaky(out_channels, out_channels, 1)
self.maxpool = nn.MaxPool2d([2,2],[2,2])
def forward(self, x):
# 利用一个3x3卷积进行特征整合
x = self.conv1(x)
# 引出一个大的残差边route
route = x
c = self.out_channels
# 通过split对特征层的通道进行分割,将通道进行二均等分,取第二部分作为主干部分。
x = torch.split(x, c//2, dim = 1)[1]
# 对主干部分进行3x3卷积
x = self.conv2(x)
# 引出一个小的残差边route_1
route1 = x
# 对第主干部分进行3x3卷积
x = self.conv3(x)
# 主干部分与小残差部分进行相接
x = torch.cat([x,route1], dim = 1)
# 对相接后的结果进行1x1卷积
x = self.conv4(x)
feat = x
# 主干部分与大残差边进行相接
x = torch.cat([route, x], dim = 1)
# 利用最大池化进行高和宽的压缩
x = self.maxpool(x)
return x,feat
三、主干网络Backbone部分
class CSPDarkNet(nn.Module):
def __init__(self):
super(CSPDarkNet, self).__init__()
# 首先利用两次步长为2x2的3x3卷积进行高和宽的压缩
# 416,416,3 -> 208,208,32 -> 104,104,64
self.conv1 = ConvBNLeaky(3, 32, kernel_size=3, stride=2)
self.conv2 = ConvBNLeaky(32, 64, kernel_size=3, stride=2)
# 104,104,64 -> 52,52,128
self.resblock_body1 = Resblock_body(64, 64)
# 52,52,128 -> 26,26,256
self.resblock_body2 = Resblock_body(128, 128)
# 26,26,256 -> 13,13,512
self.resblock_body3 = Resblock_body(256, 256)
# 13,13,512 -> 13,13,512
self.conv3 = ConvBNLeaky(512, 512, kernel_size=3)
self.num_features = 1
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
# 416,416,3 -> 208,208,32 -> 104,104,64
x = self.conv1(x)
x = self.conv2(x)
# 104,104,64 -> 52,52,128
x, _ = self.resblock_body1(x) #前两个resblock_body不需要输出feat分支
# 52,52,128 -> 26,26,256
x, _ = self.resblock_body2(x) #前两个resblock_body不需要输出feat分支
# 26,26,256 -> x为13,13,512
# -> feat1为26,26,256
x, feat1 = self.resblock_body3(x) #输出feat1分支,后面会用到,feat1为26,26,256
# 13,13,512 -> 13,13,512
x = self.conv3(x)
feat2 = x #feat2就是主干网络最后的输出13,13,512,后面会接上FPN层
return feat1,feat2
def darknet53_tiny(pretrained, **kwargs):
model = CSPDarkNet()
if pretrained:
model.load_state_dict(torch.load("model_data/CSPdarknet53_tiny_backbone_weights.pth"))
return model
四、YOLOv4-tiny网络结构的构建
1、构建卷积 + 上采样模块(共有一处)
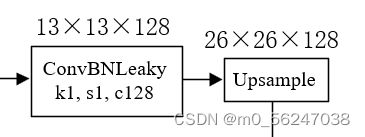
#---------------------------------------------------#
# 卷积 + 上采样
#---------------------------------------------------#
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
ConvBNLeaky(in_channels, out_channels, 1),
nn.Upsample(scale_factor=2, mode='nearest')
)
def forward(self, x,):
x = self.upsample(x)
return x
2、yolo_head部分(有两个)

#---------------------------------------------------#
# 最后获得yolov4的输出
# filters_list是一个列表[512, len(anchors_mask[0]) * (5 + num_classes)]
#---------------------------------------------------#
def yolo_head(filters_list, in_filters):
m = nn.Sequential(
ConvBNLeaky(in_filters, filters_list[0], 3),
nn.Conv2d(filters_list[0], filters_list[1], 1),
)
return m3、构建YoloBody
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, pretrained=False):
super(YoloBody, self).__init__()
self.backbone = darknet53_tiny(pretrained)
self.conv_for_P5 = ConvBNLeaky(512, 256, 1) # 主干网络后面紧接着的卷积层
self.yolo_headP5 = yolo_head([512, len(anchors_mask[0]) * (5 + num_classes)], 256)
self.upsample = Upsample(256, 128) # 包含卷积 + 上采样
self.yolo_headP4 = yolo_head([256, len(anchors_mask[1]) * (5 + num_classes)], 384)
def forward(self, x):
# ---------------------------------------------------#
# 生成CSPdarknet53_tiny的主干模型
# feat1的shape为26,26,256
# feat2的shape为13,13,512
# ---------------------------------------------------#
feat1, feat2 = self.backbone(x)
# 13,13,512 -> 13,13,256
P5 = self.conv_for_P5(feat2)
# 13,13,256 -> 13,13,512 -> 13,13,255
out0 = self.yolo_headP5(P5)
# 13,13,256 -> 13,13,128 -> 26,26,128
P5_Upsample = self.upsample(P5) # 再将P5经过一个卷积层和上采样层
# 26,26,256 + 26,26,128 -> 26,26,384
P4 = torch.cat([P5_Upsample, feat1], axis=1) # 将P5_Upsample,feat1进行拼接
# 26,26,384 -> 26,26,256 -> 26,26,255
out1 = self.yolo_headP4(P4)
return out0, out1
reference
Pytorch 搭建自己的YoloV4-tiny目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili