行为识别:行人跌倒检测(含源码)
文章目录
- ST-GCN
- 骨架的图结构
- 空间图卷积网络
- 划分子集
- 注意力机制
- TCN
- 训练
- 参考
本文抛砖引玉为大家提供一个行为识别的案例,大家也可以根据该方法实现更多任务,也可以提供一些改进的方法。
本项目主要检测7类行为:Standing,Walking,Sitting,Lying Down,Stand up,Sit down,Fall Down。算法主要分三部分:
- YOLOv3-tiny用于行人检测
- DeepSort用于行人跟踪
- ST-GCN用于行为检测
YOLO系列在笔者之前博客有讲解,DeepSort也比较常见(如有需要笔者另择时间讲解),本文主要讲一下ST-GCN方法。
ST-GCN

给出一个动作视频的骨架序列信息,首先构造出表示该骨架序列信息的图结构,ST-GCN的输入就是图节点上的关节坐标向量,然后是一系列时空图卷积操作来提取高层的特征,最后用SofMax分类器得到对应的动作分类。整个过程实现了端到端的训练。
骨架的图结构
设一个有N个节点和T帧的骨架序列的时空图为G=(V,E),其节点集合为V={vti|t=1,…,T,i=1,…,N},第t帧的第i个节点的特征向量F(vti)由该节点的坐标向量和估计置信度组成。
图结构由两个部分组成:
- 根据人体结构,将每一帧的节点连接成边,这些边形成
spatial edgesES={vtivtj|(i,j)∈H}。H是一组自然连接的人体关节。 - 将连续两帧中相同的节点连接成边,这些边形成
temporal edgesEF={vtiv(t+1)i}。
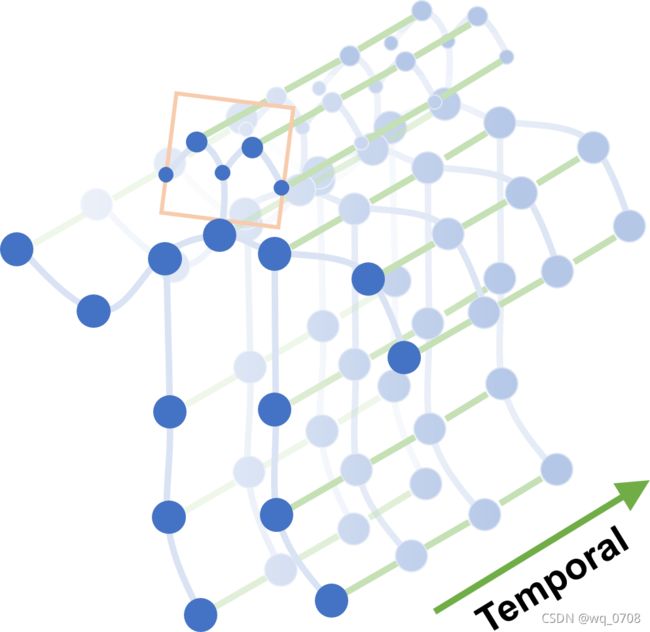
蓝色圆点表示身体关节。人体关节间的体内边缘是根据人体的自然联系来定义的。帧间边缘连接连续帧之间的相同关节。关节坐标用作ST-GCN的输入。
空间图卷积网络
以常见的图像的二维卷积为例,针对某一位置x的卷积输出可以写成如下形式:
f o u t ( x ) = ∑ h = 1 K ∑ w = 1 K f i n ( P ( x , h , w ) ) ⋅ W ( h , w ) (1) f_{out}(x)=\sum_{h=1}^K\sum_{w=1}^Kf_{in}(P(x,h,w))·W(h,w) \tag{1} fout(x)=h=1∑Kw=1∑Kfin(P(x,h,w))⋅W(h,w)(1)
输入通道数为c的特征图fin,卷积核大小K×K,sampling function采样函数P(x,h,w)=x+P′(h,w),weight function通道数为c的权重函数。
(1)sampling function
在图像中,采样函数P(h,w)指的是以x像素为中心的周围邻居像素,在图中,邻居像素集合被定义为:
B ( v t i ) = { v t j ∣ d ( v t j , v t i ) ≤ D } (2) B(v_{ti})=\{v_{tj}|d(v_{tj},v_{ti})≤D\} \tag{2} B(vti)={vtj∣d(vtj,vti)≤D}(2)
d(vtj,vti)指的是从vtj到vti的最短距离,因此采样函数可以写成:
P ( v t i , v t j ) = v t j (3) P(v_{ti},v_{tj})=v_{tj} \tag{3} P(vti,vtj)=vtj(3)
(2)weight function
在2D卷积中,邻居像素规则地排列在中心像素周围,因此可以根据空间顺序用规则的卷积核对其进行卷积操作。类比2D卷积,在图中,将sampling function得到的邻居像素划分成不同的子集,每一个子集有一个数字标签,因此有lti : B(vti)→{0,…,K−1}。将一个邻居节点映射到对应的子集标签,权重方程为:
W ( v t i , v t j ) = W ′ ( l t i ( v t j ) ) (4) W(v_{ti},v_{tj})=W^{'}(l_{ti}(v_{tj})) \tag{4} W(vti,vtj)=W′(lti(vtj))(4)
(3)空间图卷积
f o u t ( v t i ) = ∑ v t j ∈ B ( v t i ) 1 Z t i ( v t j ) f i n ( P ( v t i , v t j ) ) ⋅ W ( v t i , v t j ) (5) f_{out}(v_{ti})=\sum_{v_{tj}\in B(v_{ti})}\frac{1}{Z_{ti}(v_{tj})}f_{in}(P(v_{ti},v_{tj}))·W(v_{ti},v_{tj}) \tag{5} fout(vti)=vtj∈B(vti)∑Zti(vtj)1fin(P(vti,vtj))⋅W(vti,vtj)(5)
其中,归一化项
Z t i ( v t j ) = ∣ { v t k ∣ l t i ( v t k ) = l t i ( v v t j ) } ∣ (6) Z_{ti}(v_{tj})=|\{v_{tk}|l_{ti}(v_{tk})=l_{ti}(v_{vtj})\}| \tag{6} Zti(vtj)=∣{vtk∣lti(vtk)=lti(vvtj)}∣(6)
等价于对应子集的基。将式(3)(4)代入式(5)得到:
f o u t ( v t i ) = ∑ v t j ∈ B ( v t i ) 1 Z t i ( v t j ) f i n ( v t j ) ⋅ W ( l t i ( v t j ) ) (7) f_{out}(v_{ti})=\sum_{v_{tj}\in B(v_{ti})}\frac{1}{Z_{ti}(v_{tj})}f_{in}(v_{tj})·W(l_{ti}(v_{tj})) \tag{7} fout(vti)=vtj∈B(vti)∑Zti(vtj)1fin(vtj)⋅W(lti(vtj))(7)
(4)时空模型
将空间域模型扩展到时间域,得到采样函数:
B ( v t i ) = { v q j ∣ d ( v t j , v t i ) ≤ K , ∣ q − t ∣ ≤ ⌊ Γ / 2 ⌋ } (8) B(v_{ti})=\{v_{qj}|d(v_{tj},v_{ti})\leq K,|q-t|\leq\lfloor\Gamma/2\rfloor \} \tag{8} B(vti)={vqj∣d(vtj,vti)≤K,∣q−t∣≤⌊Γ/2⌋}(8)
参数 Γ \Gamma Γ控制时间域卷积核大小,weight function为
l S T ( v q j ) = l t i ( v t j ) + ( q − t + ⌊ Γ / 2 ⌋ ) × K (9) l_{ST}(v_{qj})=l_{ti}(v_{tj})+(q-t+\lfloor\Gamma/2\rfloor)\times K \tag{9} lST(vqj)=lti(vtj)+(q−t+⌊Γ/2⌋)×K(9)
其中, l t i ( v t j ) l_{ti}(v_{tj}) lti(vtj)是vti处单帧情况的标签映射。这样,就对构造的时空图定义了卷积运算。
划分子集

(a)输入骨架的示例帧,身体关节用蓝点绘制。D=1的滤波器的接收域用红色虚线圆圈表示。
(b)唯一划分 Uni-labeling:将节点的1邻域划分为一个子集。
(c)基于距离的划分 Distance partitioning:将节点的1邻域划分为两个子集,节点本身子集与邻节点子集。
(d)空间构型划分 Spatial configuration partitioning:将节点的1邻域划分为3个子集,第一个子集连接了空间位置上比根节点更远离整个骨架的邻居节点,第二个子集连接了更靠近中心的邻居节点,第三个子集为根节点本身,分别表示了离心运动、向心运动和静止的运动特征。
注意力机制
在运动过程中,不同的躯干重要性是不同的。例如腿的动作可能比脖子重要,通过腿部我们甚至能判断出跑步、走路和跳跃,但是脖子的动作中可能并不包含多少有效信息。
因此,ST-GCN 对不同躯干进行了加权(每个 ST-GCN单元都有自己的权重参数用于训练)。
TCN
GCN 帮助我们学习了到空间中相邻关节的局部特征。在此基础上,我们需要学习时间中关节变化的局部特征。如何为 Graph 叠加时序特征,是图卷积网络面临的问题之一。这方面的研究主要有两个思路:时间卷积(TCN)和序列模型(LSTM)。
ST-GCN 使用的是 TCN,由于形状固定,可以使用传统的卷积层完成时间卷积操作。为了便于理解,可以类比图像的卷积操作。ST-GCN 的 feature map最后三个维度的形状为(C,V,T),与图像 feature map的形状(C,W,H)相对应。
- 图像的通道数C对应关节的特征数C。
- 图像的宽W对应关键帧数V。
- 图像的高H对应关节数T。
在图像卷积中,卷积核的大小为w×1,则每次完成 w 行像素,1 列像素的卷积。stride为 s,则每次移动 s 像素,完成 1 行后进行下 1 行像素的卷积。
在时间卷积中,卷积核的大小为temporal_kernel_size×1,则每次完成 1 个节点,temporal_kernel_size个关键帧的卷积。stride为 1,则每次移动1帧,完成1个节点后进行下1个节点的卷积。
训练

输入的数据首先进行batch normalization,然后在经过9个ST-GCN单元,接着是一个global pooling得到每个序列的256维特征向量,最后用SoftMax函数进行分类,得到最后的标签。
每一个ST-GCN采用Resnet的结构,前三层的输出有64个通道,中间三层有128个通道,最后三层有256个通道,在每次经过ST-CGN结构后,以0.5的概率随机将特征dropout,第4和第7个时域卷积层的strides设置为2。用SGD训练,学习率为0.01,每10个epochs学习率下降0.1。
ST-GCN 最末卷积层的响应可视化结果图如下:

源码
Models
笔者Gitee主页
参考
[1].ST-GCN论文
[2].ST-GCN笔记
[3].ST-GCN官方代码
补:基于几何判断的跌倒检测算法