YOLOv2论文笔记
前些天把yolov1论文学习完(yolov1论文笔记_crlearning的博客-CSDN博客),今天分享一下yolov2的论文(YOLO9000:Better,Faster,Stronger),主要是对yolov1的缺点进行改进,并提出一些训练小trick。
论文地址:https://pan.baidu.com/s/1_30O3DD8gDzQocp9UndxwQ 提取码: 6666
目录
1、摘要
2、Better
2.1Batch Normalization
2.2High Resolution Classifier
2.3Convolutional With Anchor Boxes
2.4Dimension Clusters
2.5 Direct location prediction
2.6Fine-Grained Features
2.7Multi-Scale Training
3、Faster
4、Stronger
1、摘要
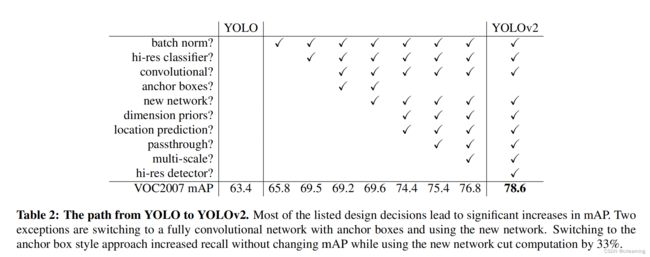
这篇论文提出两个新颖的算法,一个是yolov2,一个是yolo9000,作者指出这些算法在COCO数据集上的效果比yolov1以及fast r-cnn都要好。由于目标检测的数据集比图像分类的数据集少,并且价格贵,作者想是通过ImageNet和COCO数据集联合训练得到的yolo9000,通过名字看出,它可以预测9000个分类,其中我主要学习yolov2,下面是论文中主要从更好、更快、更健壮三个维度描述yolov2的提升。
2、Better
yolov1中存在这较大的定位误差,recall值也比较低,因此需要提在提高recall和localization的同时还需要保持classification的精度。但是网络又不能太大,否则算法就会慢,yolov2汇聚了很多新的概念来提高yolo性能。
2.1Batch Normalization
采用批量归一化大大提高模型的收敛性,能够帮助模型更好的规范化,也可以在不过度拟合的情况下去除dropout,并且使用batch normalization能够使得模型的map值提升2%。对于bn的理解,我认为就是将我们的数据规范在同一个范围之内,大大减少了不同数据之间的误差。
2.2High Resolution Classifier
更好分辨率分类器,就是将输入的图片变大,yolov1的主干网络输入图片是224 x 224进行预训练,然后在提高到448 x 448进行检测训练,而yolov2将输入图片提升为448 x 448,在Imagenet预训练模型上更改输入图片分辨率,然后在训练10个epoch,使用这个方法提升了4%的map值。
2.3Convolutional With Anchor Boxes
在yolov1中使用全连接层来预测box的坐标,并不像Faster R-CNN中RPN生成预选框,RPN只需预测偏移量,而不是整个坐标,这样简化了网络学习。yolov2模型有几点改进:
1、移除最后一层的全连接层,并使用anchor boxes来预测
2、移除一层pooling层,为了使得有不错分辨率
3、将输入448 x 448改为416 x 416,论文中提到因为416除32等于奇数,就会有单个单元格对应,怎么去理解这个概念,首先,在我们的网络中存在5个pooling层,那么就相当于缩小32倍,那么在最后的特征图上就是13 x 13,每一个单元格对应原图32 x 32的大小,也就是感受野。如果最后的输出不是奇数,有一个大物体在图像中心,那么就没有中心单元格,中心只能是4个单元格去对应,就导致浪费。(个人理解)
yolov1只有7 x 7 x 2个box,而yolov2有13 x 13 x 9个box,在结果对比起来,yolov2的准确率只降低0.4map,但recall上升了7%,可见有效。
2.4Dimension Clusters
维度聚类,使用anchor boxes有两个问题,首先box的大小是手工挑选,network在进行调整。但是如果可以选择更好的预选框是不是可以让模型更容易学习。作者使用k-means聚类来选择预选框,其中距离并不是使用欧式距离,这容易导致大盒子更大的误差,而是用IOU值来作为距离:
![]()

左边曲线图这是聚类的结果,选择k = 5能够得到一个Aug IOU相对较大,并且boxes的个数不多,再往上得到的效果并不是那么好,右边图中是5个box,蓝色为COCO数据集上的,白色为VOC数据集上。

可以看出使用k-means选择boxes比手工选择有更好提升。
2.5 Direct location prediction
直接位置预测,yolo使用anchor的第二个问题就是在模型刚开始迭代时,模型不稳定,原因是预测box的(x,y)位置。论文中给出的计算方式为:

但是从Faster R-CNN论文中的计算方式中

所以论文中应该是写错了符号,这些计算方式对x,y没有任何的限制,收敛速度可能相对较慢,作者使用的是相对每个单元格做偏移,使得x和y的偏移量在0到1之间,计算公式如下:

使用聚类和位置限制的方式比单纯使用anchor提高了5%的map值。
2.6Fine-Grained Features
细粒度特性,它的功能和resnet的原理类似,就是添加一个直通层,将26 x 26的分辨率和 13 x 13的层相加,在26 x 26那一层做个卷积操作,拉长通道数,这样做主要是为了让小信息不丢失,并且有1%的提升
2.7Multi-Scale Training
多尺度训练,为了使得yolov2有更好的鲁棒性,能够在不同的图片大小下进行,每10epoch就改变输入图像尺寸,大小是32的倍数,最大为608,最小为320。这使得yolov2可以对不同的分辨率进行检测。低分辨率速度快,精度低,高分辨速度稍微慢,精度高

3、Faster
Darknet-19,yolov2并没有使用vgg-16,虽然精确,但是处理一张224 x 224图片需要306.9亿次浮点运算,在yolov1中是基于Googlenet的架构,只用了85.2亿计算,精度略低于vgg-16。在yolov2中使用Darknet-19,只需要55.8亿次计算,精度也很高。

分类训练,对训练的图片进行随机裁剪、旋转等数据处理操作,其中对学习率进行处理
4、Stronger
这一块主要是讲解了Imagenet和COCO数据集的分类检测联合训练方式,实现YOLO9000这个模型,由于里面的一些类别存在冲突,使用的是一种WordNet的方式建立WordTree,使得每个类别都分离开

这一块了解得没有很懂,大概就知道这么多,大家有兴趣可以看看原论文,过几天更新YOLOv3,v1,v2我就是打算了解作者的整个思路流程,所以代码也没有看,v3代码打算自己实现一下,谢谢各位大佬观看。