检测恶意软件分类模型中的概念漂移
科研笔记
论文题目-检测恶意软件分类模型中的概念漂移

共形预测 (conformal prediction)是一种置信度预测器,它生成具有用户定义的错误率的预测。在某个置信度水平下,所有预测范围的那部分将包括正确的标签或值(分别用于分类和回归问题)。共形预测的好处之一是它可以逐个类地应用,独立保证每个类的错误率。这对于不平衡的分类问题特别有用,因为其可以大大减少偏差。
- 统计学习(Statistical Machine Learning)笔记
人工智能、模式识别、数据挖掘、自然语言处理、语音处理、计算视觉、信息检索、生物信息。
定义:统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。
特点:以计算机和网络为平台;以数据为研究对象;以预测和分析数据为目的;以方法为中心;是多领域交叉的学科。

图1 统计学习方法步骤
机器学习的常用方法,主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。简单的归纳就是,是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习;没标签则为无监督学习。

图2 统计学习方法的分类
- 共形预测(Conformal Prediction, CP)笔记


显著性水平是估计总体参数落在某一区间内,可能犯错误的概率。
CP解决的问题
基于单一的传统机器学习方法,虽然在样本识别能力上都有提升,但是对复杂函数的表达能力有限,泛化能力较弱,不能很好地处理复杂分类问题。这些分类算法只输出预测结果标签﹐“非黑即白”式的判断样本数据的标签,缺少对预测结果置信度的评价机制,因此无法保证预测结果的可靠性。共形预测(Conformal Prediction , CP)算法利用有效的置信度来衡量预测结果的可靠性, 基于一致性原理且定义明确的数学框架, 用于衡量校准集与测试实例的符合程度,使用数据实例的奇异度(不一致性)确定新实例预测的置信值, 同时生成在某一范围内具有限定错误率的预测类标签(假设训练集样本和被预测实例需独立分布)。
研究现状
共形预测是在机器学习算法基础上对预测结果进行置信度计算,因此很多分类算法(如SVM、KNN、ANN、贝叶斯网络等)在共形预测框架下被称为底层算法。CP算法融入到卷积神经网络/随机森林/支持向量机SVM。
想法笔记:
- CP的输出情况是p-value。预测的每个结果都对应一个p-value,p-value的值反映了预测数据和校准集的一致程度。p-value的值越大,预测数据与校准集C={(x1,y1), (x2,y2), …., (xn,yn)}越一致。CP框架提供预测结果的可信度和置信值这2个关键性能指标。

P值不是给定样本结果时原假设为真的概率,而是给定原假设为真时样本结果出现的概率。
- BRB也可以用来做分类和预测问题。BRB的输出情况是置信分布:{(D1, Degree1),(D2, Degree2),(D3, Degree3),(D4, Degree4)}。比如,安全评估问题,结果标签有四个评估等级分别是优(D1)、良(D2)、中(D3)、差(D4)。Degree代表每个等级对应的置信度。那么,{(D1, Degree1),(D2, Degree2),(D3, Degree3),(D4, Degree4)}代表安全评估模型的预测结果评估为优(D1)的置信度为Degree1,良(D2)的置信度为Degree2,中(D3)的置信度为Degree3,差(D4)的置信度为Degree4。
置信度表示评估算法对该选择的确定程度或承诺程度。
- 论文大体整理笔记
检测恶意软件分类模型中的概念漂移
摘要------建立恶意软件行为的机器学习模型被广泛认为是实现恶意软件有效分类的灵丹妙药。然而,构建可持续学习模型的一个关键要求是在各种恶意软件样本上进行训练。不幸的是,恶意软件发展迅速,因此很难——如果不是不可能的话——推广学习模型来反映未来的、以前看不到的行为。因此,大多数恶意软件分类器在长期运行中变得不可持续,随着恶意软件的不断发展,它们会迅速过时。在这项工作中,提出了Transend框架,在机器学习模型的性能开始下降之前,在部署过程中识别老化分类模型。这与传统的方法有很大的不同,传统的方法是在观察到不良性能时对老化模型(?)进行回顾性再训练。我们的方法使用在部署期间看到的样本与用于训练模型的样本的统计比较,从而构建预测质量的度量。我们展示了Transcend如何用于识别基于Android和Windows恶意软件的两个独立案例研究的概念漂移,在模型开始由于过时的训练而做出持续糟糕的决策之前提出了一个红色信号。
(概念漂移:在预测分析和机器学习的概念漂移表示目标变量的统计特性随着时间的推移以不可预见的方式变化的现象。随着时间的推移,模型的预测精度将降低。)
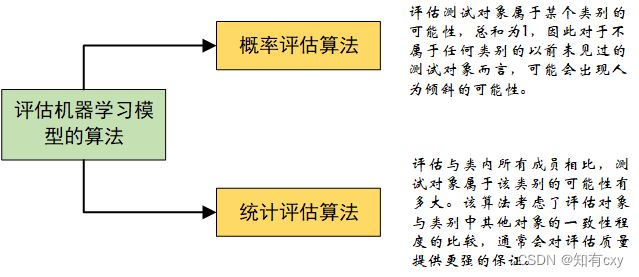
决策评估的统计方法是在以前所作决策的背景下考虑每个决策。这与概率评估不同,在概率评估中,度量指示测试对象属于一个类的可能性有多大。决策评估?文章应该是在共形预测器(Conformal Predictor,CP)的基础上构建了共性评估器(conformal evaluator,CE)。
1.论文背景----恶意软件分类
参考资料1:计算机病毒分析-王志老师课程链接
https://www.xuetangx.com/learn/nankai080910028031/nankai080910028031/12426169/video/23406883
参考资料2:
论文《IoT-Based DDoS Attack Detection and Mitigation Using the Edge of SDN》;
论文《An Adaptive Behavioral-Based Incremental Batch Learning Malware Variants Detection Model Using Concept Drift Detection and Sequential Deep Learning》。
自适应 区间构造的BRB
1.1 计算机病毒的定义和类型
广义的计算机病毒定义,也称为恶意代码。任何以某种方式对用户、计算机或网络造成破坏的软件,都可以被称为是恶意代码,包括计算机病毒、木马、蠕虫、Rootkit、勒索病毒、间谍软件,等等。
计算机病毒的功能分类:(1)后门。攻击者绕过安全认证,远程控制受感染的计算机。(2)僵尸网络。由大量被感染的计算机组成的网络,可以发起大规模的网络攻击,例如DDoS攻击。(3)木马。表面上是有用的软件,实际目的却是危害计算机安全的程序。(4)下载器、启动器。用来下载和执行其他病毒的恶意代码。(5)间谍软件。从受害者计算机上收集信息并发送给攻击者的恶意代码。(6)Rootkit。获得计算机root权限的工具,可以用来隐藏其它计算机病毒。(7)勒索软件。通过加密受感染用户的文或者硬盘,索要赎金的病毒。(8)垃圾邮件发送病毒。感染用户计算机之后,使用系统与网络资源来发送大量的垃圾邮件,例如广告邮件、钓鱼邮件等。(8)蠕虫。可以自我复制并感染其他计算机的病毒。
1.2 计算机病毒分析的目标
1.计算机病毒分析
通常是为一起计算机病毒事件的应急响应提供所需信息,包括以下的分析内容: (1)系统到底发生了什么? (2)定位被感染的计算机和可疑的程序。(3)对可疑文件进行分析。(4)提取出可以在系统和网络上检测病毒的特征码,主机特征码和网络特征码。(5)衡量并消除计算机病毒所带来的损害。
2.可疑文件分析
对病毒文件进行分析是对计算机病毒进行应急响应的关键。
√ 计算机病毒是如何工作的
√ 如何识别计算机病毒
√ 如何消除计算机病毒
3.计算机病毒特征码
A.计算机病毒的主机特征码
- 主机特征码与反病毒软件所使用的病毒特征码不同。
- 主机特征码关注的是病毒对系统做了什么,而不是病毒本身的文件特征。
- 比反病毒软件特征码更加有效。
√多态、变形、加壳、花指令。
√甚至计算机病毒执行过程中将自身文件从硬盘中删除
B.病毒特征码:反病毒软件所使用的病毒特征码关注恶意代码本身的特性
C.计算机病毒的网络特征码
- 通过分析计算机病毒的网络通信数据提取出的特征码
- 网络特征码包括恶意的IP地址URL、邮件、攻击数据包、计算机病毒间的通信协议等。
- 可以和主机特征码相结合,提供更高的检测率和更少的误报。
1.3 计算机病毒分析技术概述
静态分析:静态分析方法是在没有运行计算机病毒时,对其进行分析的相关技术。常用的分析工具有VirusTotal、strings、IDA pro等。
动态分析:动态分析方法则需要运行计算机病毒。常用的分析工具有RegShot、Process Monitor、OllyDbg等。
这两类技术又进一步分为基础分析和高级分析。
2.论文解决的问题---- 恶意软件可变性大(概念漂移),难以推广学习模型
建立恶意软件行为的机器学习模型被广泛认为是实现恶意软件有效分类的灵丹妙药。然而,构建可持续学习模型的一个关键要求是在各种恶意软件样本上进行训练。不幸的是,恶意软件(恶意软件可变性大,概念漂移)发展迅速,因此很难——如果不是不可能的话——推广学习模型来反映未来的、以前看不到的行为。因此,大多数恶意软件分类器在长期运行中变得不可持续,随着恶意软件的不断发展,它们会迅速过时。
3. 用什么方法解决这些问题----Transend 框架
为了建立可持续的恶意软件分类模型,重要的是要识别模型何时显示出老化的迹象,从而无法识别新的恶意软件。现有的解决方案旨在定期对模型进行再训练。但是,现有解决方案存在缺点:如果对模型进行过于频繁的再训练,所获得的信息将缺乏新意,无法丰富分类器。另一方面,松散的再训练频率会导致模型性能不可信的时间段。无论如何,再训练过程需要手动标记所有处理过的样本,这受到可用资源的限制。一旦获得了标签,传统的指标,如精度和召回率,将用于回顾性地指示模型性能。然而,这些指标并不评估分类器的决策。
对学习模型的决策进行定性评估的一个众所周知的方法是测试对象在候选类中的拟合概率。概率方法有一些局限性,作者举了几个例子,并不适合存在概念漂移的情况下使用。统计评估似乎克服了概率方法的局限性。然而,在使用统计评估来检测概念漂移之前,还有两个关键问题需要解决:(1)首先,评估必须与用于构建学习模型的算法无关。这很重要,因为不同的算法可能有不同的底层分类机制。(2)任何评估都必须从算法中抽象化出来,并确定一个通用的标准,该标准将底层算法视为一个黑箱。第二,更重要的是,自动计算阈值以从抽象的评估标准识别老化模型,需要在训练对象的分数之间进行蛮力搜索。
方法:在这项工作中,我们提出了Transend框架,在机器学习模型的性能开始下降之前,在部署过程中识别老化分类模型。这与传统的方法有很大的不同,传统的方法是在观察到不良性能时对老化模型进行回顾性再训练。我们的方法使用在部署期间看到的样本与用于训练模型的样本的统计比较,从而构建预测质量的度量。
4.方法的创新点
(1)提出了共形评估器(CE),这是一种评估机器学习任务质量的评估框架。CE的核心是来自评估下ML算法(AUE)和特征集的不符合度量定义。该度量建立了统计度量来量化AUE质量,并根据AUE在统计上支持数据点与类的拟合优度。
注:构成共形评估器核心的统计技术对决策评估的意义。决策评估的统计方法是在以前所作决策的背景下考虑每个决策。这与概率评估不同,在概率评估中,度量指示测试对象属于一个类的可能性有多大。相反,统计技术回答了这个问题:与所有其他成员相比,测试对象属于一个类的可能性有多大。统计证据产生的上下文证据是超越标准概率证据的一步,通常为评估的质量提供更强的保证。我们的工作剖析了共形预测器(CP)[24],并提取了其健全的统计基础来构建共形评估器(CE)。
(决策评估) P-value—算法置信度和算法可信度\概率(概率评估)
(2)在CE的统计指标之上构建评估,以评估AUE设计,并了解数据的统计分布,以更好地捕捉AUE的泛化和类别分离。
(3)提出了Transcend。这是一个完全可调的分类系统,可以根据用户的规格定制,以适应不同程度的概念漂移。这种多功能性使Transend可以用于各种各样的部署环境,在这些环境中,手工分析的成本是分类策略的核心。
(4)展示了CE的评估如何促进Transcend识别合适的统计阈值,以检测现实环境中ML性能的衰减。特别是,我们用两个案例研究来支持我们的发现,这两个案例研究展示了Transcend如何识别二元和多类分类任务中的概念漂移。
5.论文的实验
实验:展示了Transcend如何用于识别基于Android和Windows恶意软件的两个独立案例研究的概念漂移,在模型开始由于过时的训练而做出持续糟糕的决策之前提出了一个红色信号。这两个案例研究展示了Transcend如何识别二元和多类分类任务中的概念漂移。
用原始数据集对二元和多元分类案例研究进行决策评估,还对比了p度量比概率度量更有优势。。正确的预测具有较高的平均算法可信度和置信度,而错误的预测分别具有较低的算法可信度和较高的算法置信度。总的来说,积极的结果得到了强有力的统计证据的支持。
Transcend使用两种技术来评估算法在给定数据集上的质量:(i)决策评估——评估算法做出的预测的鲁棒性;Alpha评价—评价不符合措施的质量。我们将这些评估结合起来,以检测概念漂移。