【TensorRT】神经网络中的量化
文章目录
-
- 一、TensorRT 为什么需要量化
- 二、基础内容
- 三、神经网络的量化过程
一、TensorRT 为什么需要量化
量化是什么:量化在数字信号处理领域,是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化主要应用于从连续信号到数字信号的转换中。
神经网络的量化是在做一件什么事:
- 对 FP32 的权重进行饱和映射:即对权重无需进行校准,只需要进行 ±|max| 映射为 ±127,即 INT8 表示范围即可
- 对 FP32 的激活层进行不饱和映射,需要使用校准数据集来寻求最优的阈值T:
- 需要寻找合适的阈值 T ,将 ±|T| 映射为 ±127,所以需要校准数据集,用这些数据集经过 FP32 的权重,然后得到每层的特征图(FP32),求取每层特征图的直方图,划分为 2048(NVIDIA)个 bin。之后,选取不同的阈值 T,求不同的阈值 T 对应的 INT8 分布(127 个 BIN)和原始 FP32 分布的 KL 散度,然后选择 KL 散度最低的 T 值,作为量化激活层的阈值。
尽管神经网络模型已经一直在小型化,但计算量还仍在在 200MFLOPS 左右,这个计算量对于目前的(中低端)移动端CPU算力来说,还是有点吃力的,所以移动端要在自己有限算力的情况下,尽可能的做出努力。移动端加速方案可以分为 GPU 和 CPU。
为什么训练得到的模型需要量化才能在移动端使用:
-
大多数深度学习模型在训练训练时,梯度更新往往比较微小,一般模型参数都采用较高精度的 FP32 数据格式进行训练。
-
FP32 精度的模型在推理时,可能需要更长时间来预测结果,在移动端侧会影响用户体验,因此,需要提升计算速度,常采用更低精度的 FP16 或 INT8。
-
这样不仅可以减少内存访问(更快搬运数据),还可以采用更小硅片(所需乘法器数目减少),减少与计算相关的功耗(或更高操作数OP)。
经过INT8量化后的模型:
- 模型容量变小了,这个很好理解,FP32 的权重变成 INT8,大小直接缩了 4 倍
- 模型运行速度可以提升,实际卷积计算的 op 是 INT8 类型,在特定硬件下可以利用 INT8 的指令集去实现高吞吐,不论是 GPU 还是 INTEL、ARM 等平台都有 INT8 的指令集优化
- 对于某些设备,使用 INT8 的模型耗电量更少,对于嵌入式侧端设备来说提升是巨大的
二、基础内容
计算机采用 0/1 来标识信息,每个 0 或每个 1 代表一个比特/二进制位(bit),信息一般以三种形式表示:
-
字符串,最小单元是char,占 8 个比特(bit, 简写 b)内存,等于 1 个字节(Byte, 简写 B)。
-
整数 INT(Integer),INT 后面数值表示该整数类型占用内存的比特位数,常用 INT8、INT16、INT32、INT64等。
-
浮点数 FP(Floating points),FP 后面数值也代表该浮点类型占用内存的比特位数,常用 FP16(半精度)、FP32(单精度)和 FP64(双精度)。
下图为不同数据格式占用内存、可表示动态范围和数据精度情况,整体上看,数据内存占用越少,可表示的动态范围越低,精度也越低,浮点数可表示的范围比整数要多得多。
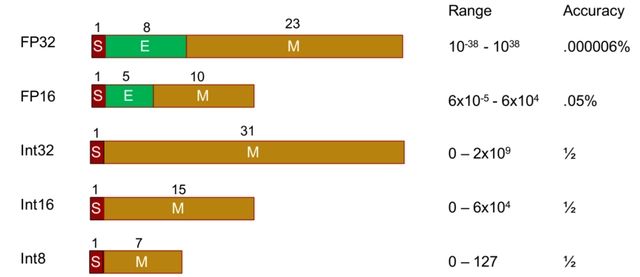
- FP32(单精度)占用 4 个字节,共 32 比特,其中 1 位为符号位(红色),8 位指数位(绿色),23 位尾数位(棕色)。
- FP16(半精度)占用 2 个字节,共 16 比特,其中 1 位为符号位,5 位指数位,10 位有效数字位。与 FP32 相比,FP16 的访存消耗仅为 1/2,也因此 FP16 是更适合在移动终端侧进行 AI 计算的数据格式。
- INT8,占用1个字节,共 8 比特,INT8 是一种定点计算方式,代表整数运算,一般是由浮点运算量化而来。在二进制中一个 “0” 或者 “1” 为 1 bit,INT8 则意味着用 8bit 来表示一个数字。因此,虽然 INT8 比 FP16 精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
三、神经网络的量化过程
量化在数字信号处理领域,是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化主要应用于从连续信号到数字信号的转换中。
神经网络的量化:将 FP 32 的权重和激活特征图量化到 INT8
- 权重量化:使用 max-max 的饱和量化即可
- 激活特征图量化:使用非饱和量化,需要使用校准数据集,先使用 FP32 的权重得到每个图形在每层的激活特征图,然后在每层,使用 KL 散度衡量不同阈值 T 得到的【量化后分布和量化前分布的 KL 散度】,每层得到一个最优阈值 T(对应的 KL 散度最小),然后对激活特征图进行不饱和量化即可。
量化的大致分类:
1、不饱和量化
量化的目的就是把训练得到的 FP32 的浮点数卷积操作,转换为 INT8 的卷积操作,这样计算就变成了原来的 1/4,最本质的操作 max-max 映射如下图,也叫不饱和映射(No saturation):
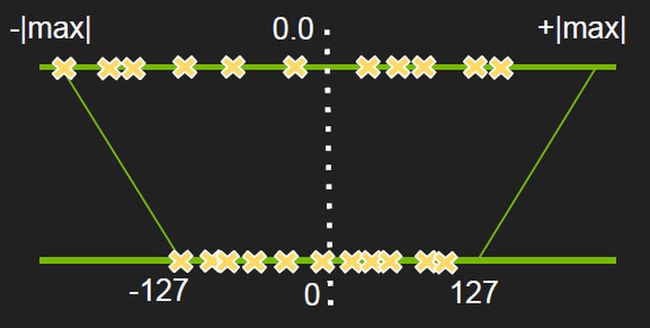
就是把一个 layer 的激活值范围的给圈出来,然后按照绝对值最大值作为阈值(因此当正负分布不均匀的时候,是有一部分是空缺的,也就是一部分值域被浪费了,也就是正负值的绝对值最大值相差较大),然后把这个范围直接按比例给映射到正负128的范围内来,公式如下:
FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t) + FP32_bias (b)
通过英伟达实验得知,bias 值去掉对精度的影响不是很大,因此直接去掉:
T = sf * t
2、饱和量化
上面是简单的 max-max 映射,这是针对均匀分布的,很明显的可以知道,只要数据分布的不是很均匀,那么精度损失是很大很明显的,于是很多情况下是这么干的,也叫饱和映射(Saturation),这种做法不是将 ±|max| 映射为 ±127,而是存在一个 阈值 |T| ,将 ±|T| 映射为±127,显然这里 |T|<|max|,阈值选取得当,就能将分布散乱的较大的值舍弃掉,也就有可能使精度损失不至于降低太多。:

为什么量化是可以保证原信息的?
- 量化可以看做保留低频信息的过程,有些高频信息不是很重要,只需要低频信息就可以得到很多的信息。
为什么说最大值映射会精度损失严重?
-
由于正负分布很不均匀,如果按照对称最大值映射(原意是为了尽可能多地保留原信息)的话,那么+max 那边有一块区域就浪费了,也就是说 scale 到 int8 后,int8 的动态范围就更小了
-
像上图这样,先找一个阀值 T,然后低于最低阀值的就全部都饱和映射到 -127 上,如上图的左边的三个红色的点就是这么处理的。
如何寻找 T:
-
建立一个模型来评估量化前后的精度损失,使得损失最小
-
NVIDIA 选择的是 KL-divergence,其实就是相对熵,来衡量两个分布的差异程度,所以也就是找到让熵最小的量化后的分布
-
KL 散度公式如下:
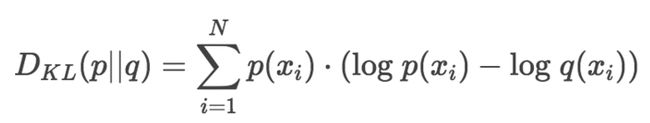
在编码理论里面,把 log 的底变为2,出来的就是 bit 位数,也就是描述一段信息的信息量需要多少个 bit
KL 散度就是来精确测量这种最优和次优之间的差异。在这里 FP32 就是原来的最优编码,INT8 就是次优的编码,用 KL 散度来描述这两种编码之间的差异。
NVIDIA 是怎么实现两者的映射:
- 将 FP32 划分到 2048 个 bin,INT8 划分到 128 个 bin
- 找到合理的阈值 T,将 2048 个 bin 映射到 128 个 bin,并且信息熵损失最小
INT8 量化流程:

int8 scale 表获取流程如下,首先准备一个校准数据集,然后对每一层:
- 收集激活值的直方图;
- 基于不同的阈值产生不同的量化分布;
- 然后计算每个分布与原分布的相对熵,然后选择熵最少的一个,也就是跟原分布最像的一个。
- 此时阀值就选出来啦,对应的 scale 值也就出来了,scale = T/127。
Calibration 校准:基于实验的迭代搜索阀值。
-
校准是量化的核心部分,提供一个样本数据集(最好是验证集的子集),称为 “校准数据集”,它用来做校准。
-
在校准数据集上运行 FP32 推理。收集激活特征图的直方图,选择不同的阈值,并计算 KL 散度,选择具有最少 KL 散度的阈值作为量化阈值,KL 散度是在参考分布(即 FP32 激活)和量化分布之间(即 INT8 激活)之间。
-
FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t),bias实验得知可去掉。
网络的前向计算涉及到两部分数值:权值和输入值(weights 和 activation,二者要做乘法运算),Szymon Migacz 也提到他们曾经做过实验,说对 weights 做 saturation 没有什么变化,因此对于 weights 的 int8 量化就使用的是不饱和的方式;而对 activation 做 saturation 就有比较显著的性能提升,因此对 activation 使用的是饱和的量化方式。
使用 KL 距离确定 |T|:映射后的分布(如 INT8 分布) 要和 FP32 的分布最接近
- 首先在校准集上进行 FP32 inference 推理;
- 对于网络的每一层(遍历):
- 收集这一层的 activation 值,并做直方图(histograms ),分成几个组别(bins)(官方给的一个说明使用的是 2048 组)
- 对于不同的阈值 |T| 进行遍历,因为这里 |T| 的取值肯定在第 128-2047 组之间,所以就选取每组的中间值进行遍历;选取使得 KL 散度取得最小值的 |T|。
- 返回一系列 |T|值,每一层都有一个 |T|。创建 CalibrationTable 。
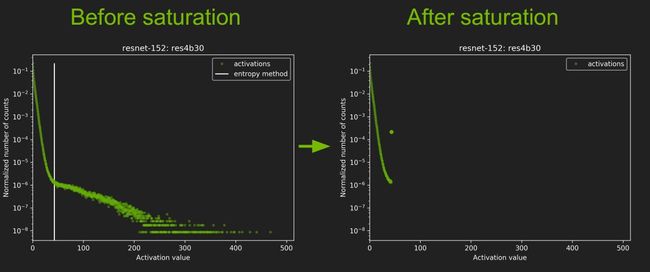
神经网络的权重是一些 float 数据,如果将其在二维坐标轴(横轴是值大小,纵轴是频次)上画出来的话,就是下面图一所示的原始概率分布函数曲线:
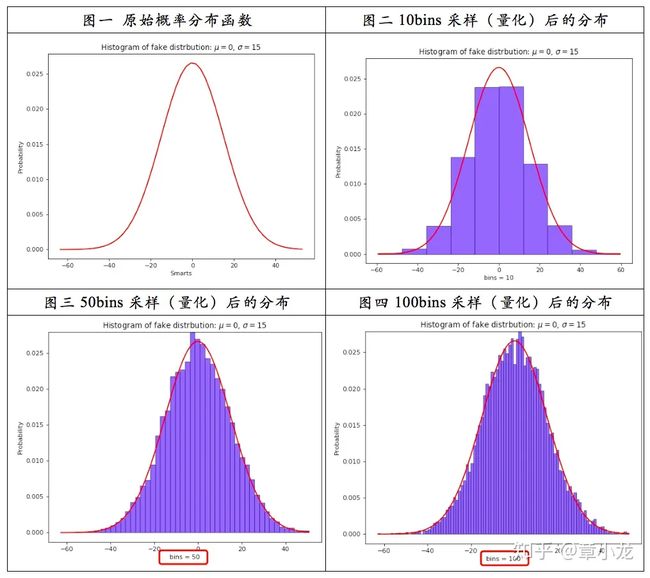
因此上面系列图可以得到的结论就是:
采样率应当越大越好,越大越接近真实情况呀,但是真实世界里面什么都是有限的,由于硬件、计算力等其他一些约束条件的限制,我们只能采用有限的采样率,这里 TensorRT 取的 2048 bins,而 mxnet 则取的是 4000bins(仅正半轴),bins 越多,优点是找到的饱和阀值更好,但是缺陷是在迭代搜索饱和阀址时计算更慢,因此这里又是一个权衡的问题。